 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Parameter-efficient Multi-subject Model for Predicting fMRI Activity
Aug 04, 2023This is the Algonauts 2023 submission report for team "BlobGPT". Our model consists of a multi-subject linear encoding head attached to a pretrained trunk model. The multi-subject head consists of three components: (1) a shared multi-layer feature projection, (2) shared plus subject-specific low-dimension linear transformations, and (3) a shared PCA fMRI embedding. In this report, we explain these components in more detail and present some experimental results. Our code is available at https://github.com/cmi-dair/algonauts23.
On the Regularization Properties of Structured Dropout
Oct 30, 2019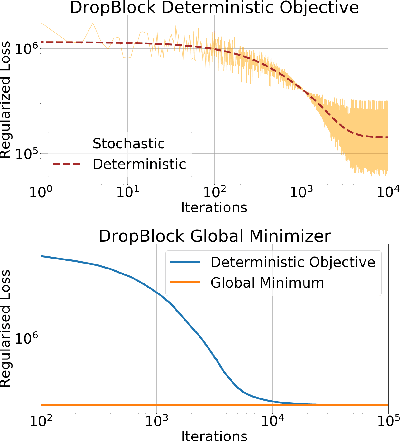
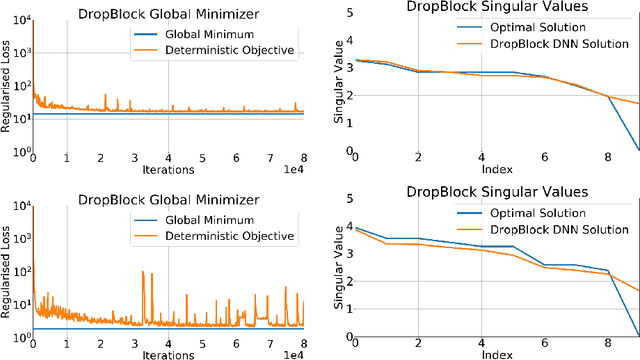
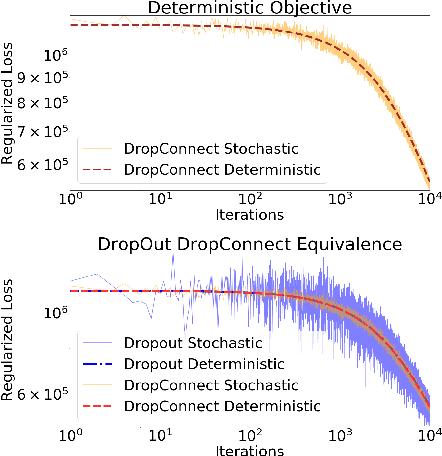
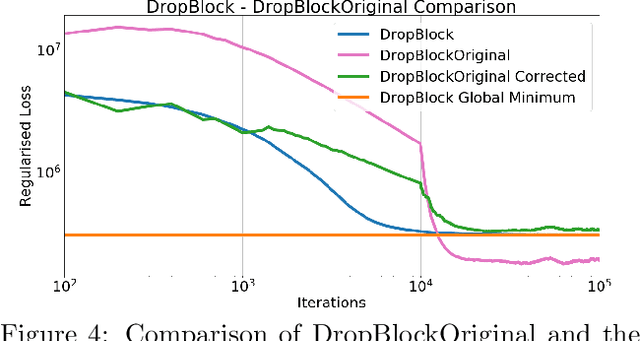
Dropout and its extensions (eg. DropBlock and DropConnect) are popular heuristics for training neural networks, which have been shown to improve generalization performance in practice. However, a theoretical understanding of their optimization and regularization properties remains elusive. Recent work shows that in the case of single hidden-layer linear networks, Dropout is a stochastic gradient descent method for minimizing a regularized loss, and that the regularizer induces solutions that are low-rank and balanced. In this work we show that for single hidden-layer linear networks, DropBlock induces spectral k-support norm regularization, and promotes solutions that are low-rank and have factors with equal norm. We also show that the global minimizer for DropBlock can be computed in closed form, and that DropConnect is equivalent to Dropout. We then show that some of these results can be extended to a general class of Dropout-strategies, and, with some assumptions, to deep non-linear networks when Dropout is applied to the last layer. We verify our theoretical claims and assumptions experimentally with commonly used network architectures.
Dropout as a Low-Rank Regularizer for Matrix Factorization
Oct 13, 2017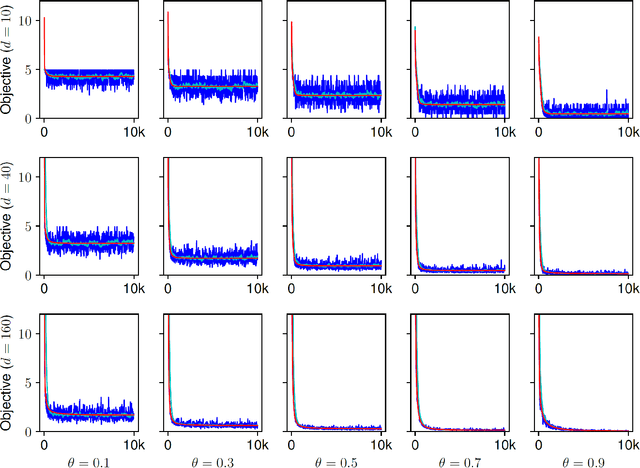
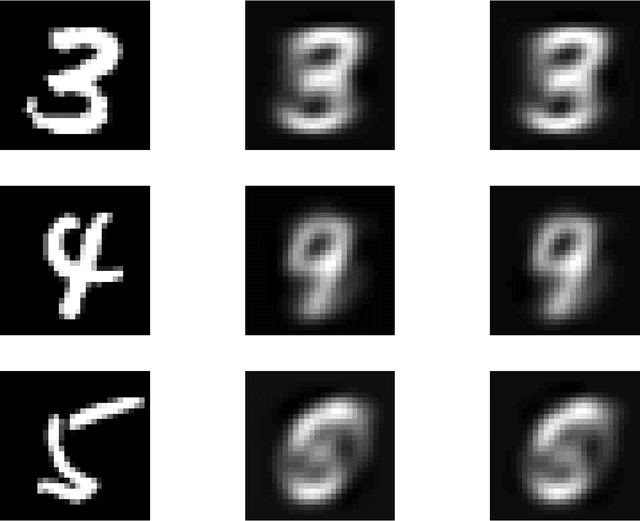
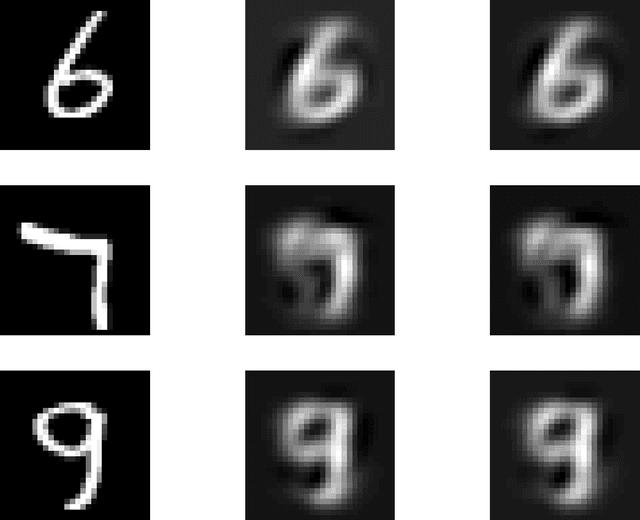
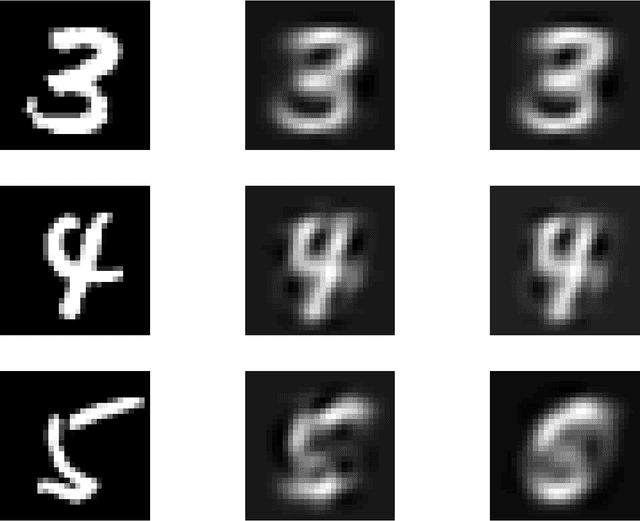
Regularization for matrix factorization (MF) and approximation problems has been carried out in many different ways. Due to its popularity in deep learning, dropout has been applied also for this class of problems. Despite its solid empirical performance, the theoretical properties of dropout as a regularizer remain quite elusive for this class of problems. In this paper, we present a theoretical analysis of dropout for MF, where Bernoulli random variables are used to drop columns of the factors. We demonstrate the equivalence between dropout and a fully deterministic model for MF in which the factors are regularized by the sum of the product of squared Euclidean norms of the columns. Additionally, we inspect the case of a variable sized factorization and we prove that dropout achieves the global minimum of a convex approximation problem with (squared) nuclear norm regularization. As a result, we conclude that dropout can be used as a low-rank regularizer with data dependent singular-value thresholding.
An Analysis of Dropout for Matrix Factorization
Oct 10, 2017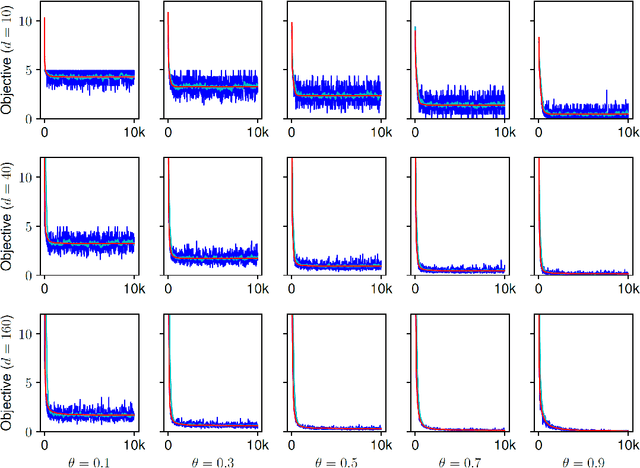
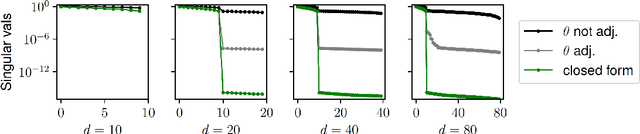
Dropout is a simple yet effective algorithm for regularizing neural networks by randomly dropping out units through Bernoulli multiplicative noise, and for some restricted problem classes, such as linear or logistic regression, several theoretical studies have demonstrated the equivalence between dropout and a fully deterministic optimization problem with data-dependent Tikhonov regularization. This work presents a theoretical analysis of dropout for matrix factorization, where Bernoulli random variables are used to drop a factor, thereby attempting to control the size of the factorization. While recent work has demonstrated the empirical effectiveness of dropout for matrix factorization, a theoretical understanding of the regularization properties of dropout in this context remains elusive. This work demonstrates the equivalence between dropout and a fully deterministic model for matrix factorization in which the factors are regularized by the sum of the product of the norms of the columns. While the resulting regularizer is closely related to a variational form of the nuclear norm, suggesting that dropout may limit the size of the factorization, we show that it is possible to trivially lower the objective value by doubling the size of the factorization. We show that this problem is caused by the use of a fixed dropout rate, which motivates the use of a rate that increases with the size of the factorization. Synthetic experiments validate our theoretical findings.