 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Safe and Unsafe Corruptions via Anisotropy and Locality
Jan 30, 2025



State-of-the-art machine learning systems are vulnerable to small perturbations to their input, where ``small'' is defined according to a threat model that assigns a positive threat to each perturbation. Most prior works define a task-agnostic, isotropic, and global threat, like the $\ell_p$ norm, where the magnitude of the perturbation fully determines the degree of the threat and neither the direction of the attack nor its position in space matter. However, common corruptions in computer vision, such as blur, compression, or occlusions, are not well captured by such threat models. This paper proposes a novel threat model called \texttt{Projected Displacement} (PD) to study robustness beyond existing isotropic and global threat models. The proposed threat model measures the threat of a perturbation via its alignment with \textit{unsafe directions}, defined as directions in the input space along which a perturbation of sufficient magnitude changes the ground truth class label. Unsafe directions are identified locally for each input based on observed training data. In this way, the PD threat model exhibits anisotropy and locality. Experiments on Imagenet-1k data indicate that, for any input, the set of perturbations with small PD threat includes \textit{safe} perturbations of large $\ell_p$ norm that preserve the true label, such as noise, blur and compression, while simultaneously excluding \textit{unsafe} perturbations that alter the true label. Unlike perceptual threat models based on embeddings of large-vision models, the PD threat model can be readily computed for arbitrary classification tasks without pre-training or finetuning. Further additional task annotation such as sensitivity to image regions or concept hierarchies can be easily integrated into the assessment of threat and thus the PD threat model presents practitioners with a flexible, task-driven threat specification.
Sparsity-aware generalization theory for deep neural networks
Jul 04, 2023Deep artificial neural networks achieve surprising generalization abilities that remain poorly understood. In this paper, we present a new approach to analyzing generalization for deep feed-forward ReLU networks that takes advantage of the degree of sparsity that is achieved in the hidden layer activations. By developing a framework that accounts for this reduced effective model size for each input sample, we are able to show fundamental trade-offs between sparsity and generalization. Importantly, our results make no strong assumptions about the degree of sparsity achieved by the model, and it improves over recent norm-based approaches. We illustrate our results numerically, demonstrating non-vacuous bounds when coupled with data-dependent priors in specific settings, even in over-parametrized models.
Adversarial robustness of sparse local Lipschitz predictors
Feb 26, 2022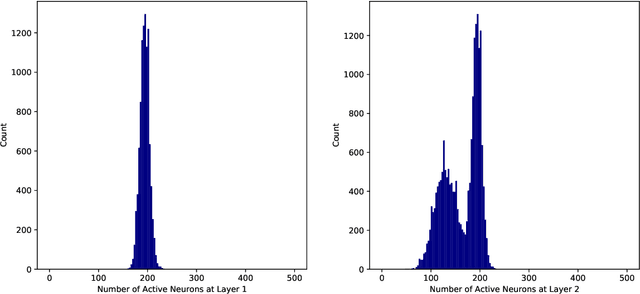
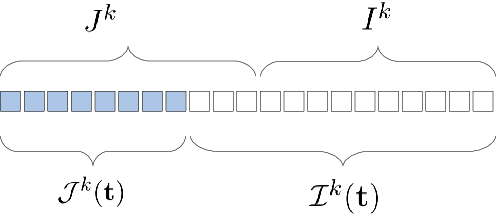
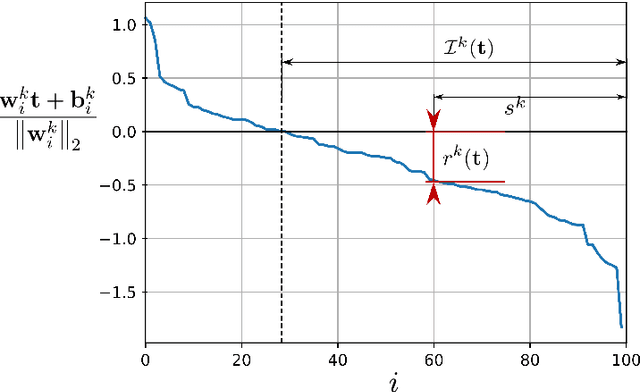
This work studies the adversarial robustness of parametric functions composed of a linear predictor and a non-linear representation map. Our analysis relies on sparse local Lipschitzness (SLL), an extension of local Lipschitz continuity that better captures the stability and reduced effective dimensionality of predictors upon local perturbations. SLL functions preserve a certain degree of structure, given by the sparsity pattern in the representation map, and include several popular hypothesis classes, such as piece-wise linear models, Lasso and its variants, and deep feed-forward ReLU networks. We provide a tighter robustness certificate on the minimal energy of an adversarial example, as well as tighter data-dependent non-uniform bounds on the robust generalization error of these predictors. We instantiate these results for the case of deep neural networks and provide numerical evidence that supports our results, shedding new insights into natural regularization strategies to increase the robustness of these models.
A Study of Neural Training with Non-Gradient and Noise Assisted Gradient Methods
May 08, 2020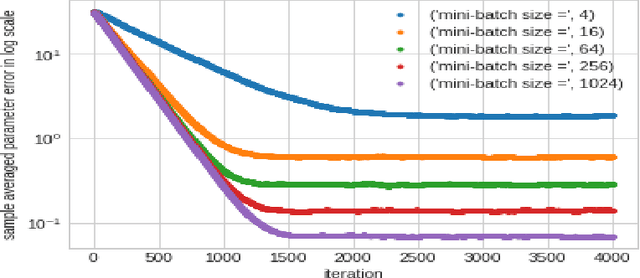
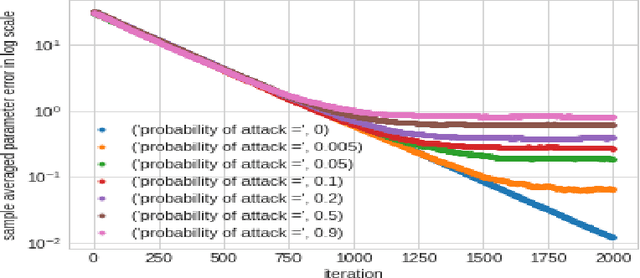
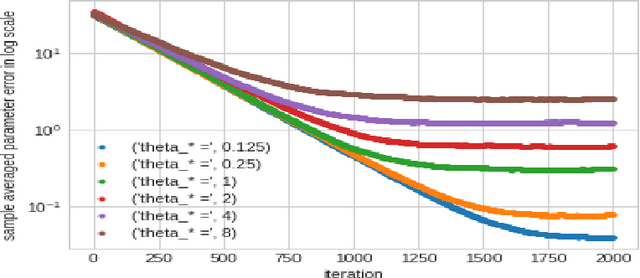
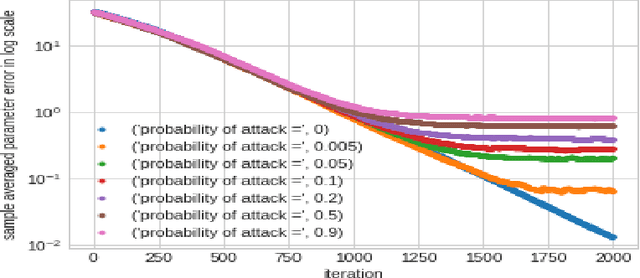
In this work we demonstrate provable guarantees on the training of depth-2 neural networks in new regimes than previously explored. (1) We start with a simple stochastic algorithm that can train a ReLU gate in the realizable setting with significantly milder conditions on the data distribution than previous results. Leveraging some additional distributional assumptions we also show near-optimal guarantees of training a ReLU gate when an adversary is allowed to corrupt the true labels. (2) Next we analyze the behaviour of noise assisted gradient descent on a ReLU gate in the realizable setting. While making no further distributional assumptions, we locate a ball centered at the origin such that all the iterates remain inside it with high probability. (3) Lastly we demonstrate a non-gradient iterative algorithm for which we give near optimal guarantees for training a class of depth-2 neural networks in the presence of an adversary who is additively corrupting the true labels. This analysis brings to light the advantage of having a large width for the network while defending against an adversary. We demonstrate that faced with data poisoning attacks of the kind we instantiate, for our chosen class of nets, the accuracy achieved by the algorithm in recovering the ground truth parameters, scales inversely with the width.
Guarantees on learning depth-2 neural networks under a data-poisoning attack
May 04, 2020
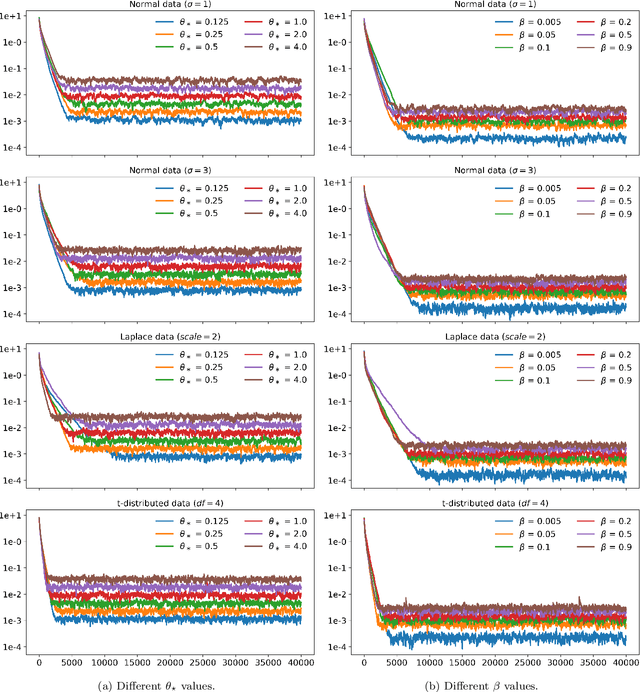
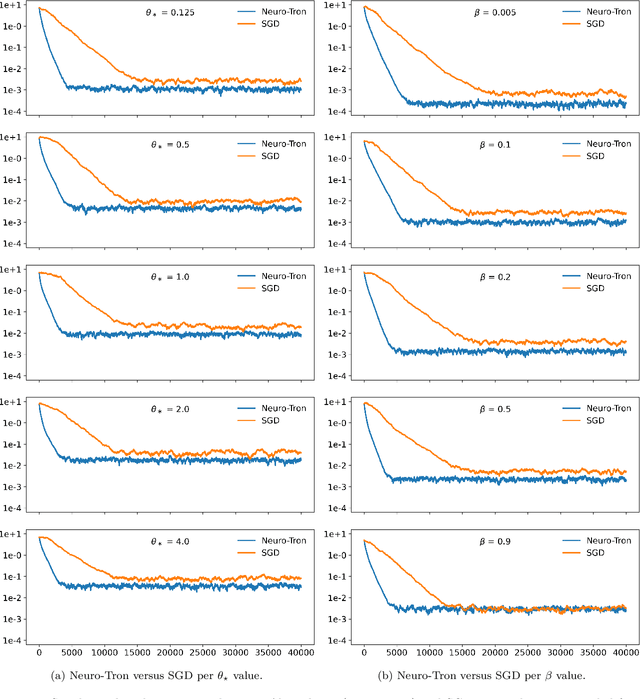
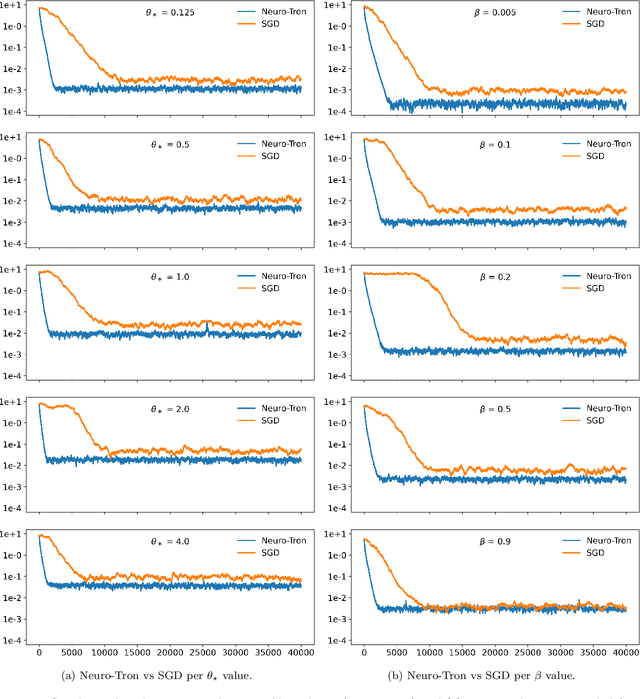
In recent times many state-of-the-art machine learning models have been shown to be fragile to adversarial attacks. In this work we attempt to build our theoretical understanding of adversarially robust learning with neural nets. We demonstrate a specific class of neural networks of finite size and a non-gradient stochastic algorithm which tries to recover the weights of the net generating the realizable true labels in the presence of an oracle doing a bounded amount of malicious additive distortion to the labels. We prove (nearly optimal) trade-offs among the magnitude of the adversarial attack, the accuracy and the confidence achieved by the proposed algorithm.