Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuarantees on learning depth-2 neural networks under a data-poisoning attack
Paper and Code
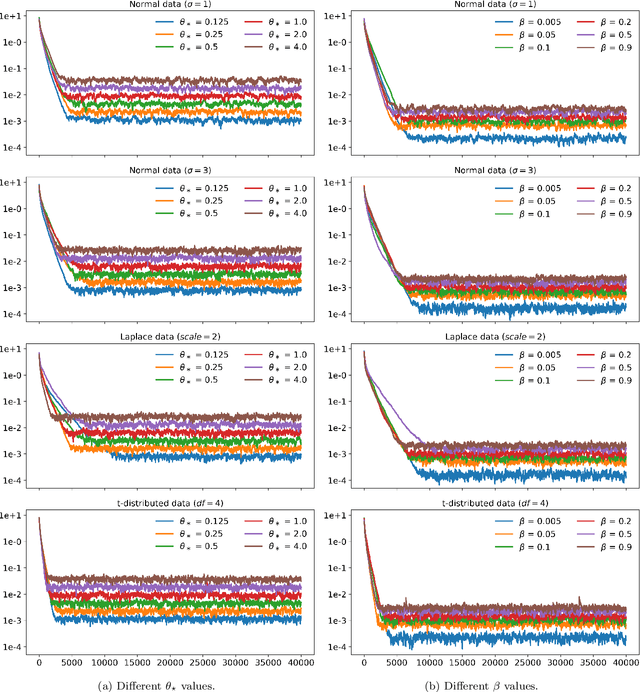
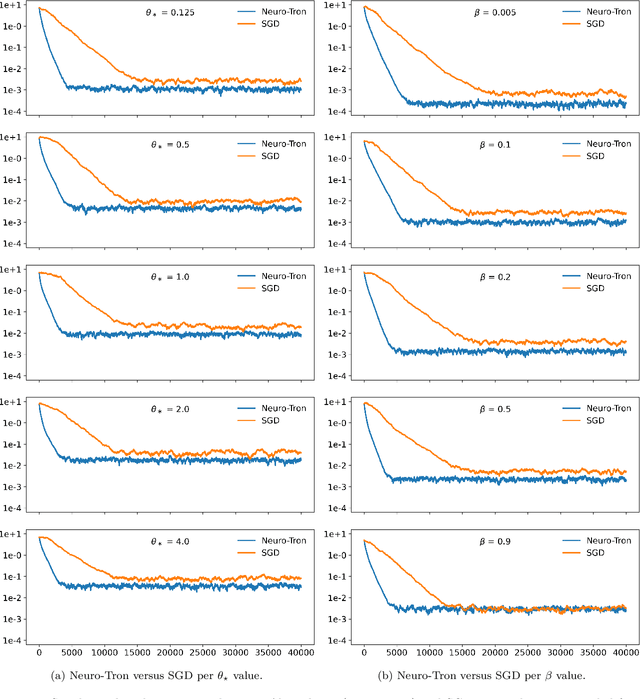
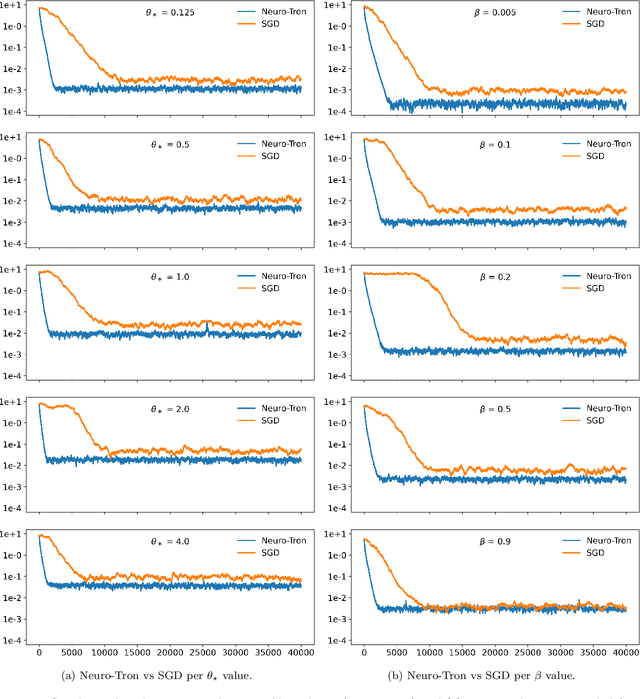
In recent times many state-of-the-art machine learning models have been shown to be fragile to adversarial attacks. In this work we attempt to build our theoretical understanding of adversarially robust learning with neural nets. We demonstrate a specific class of neural networks of finite size and a non-gradient stochastic algorithm which tries to recover the weights of the net generating the realizable true labels in the presence of an oracle doing a bounded amount of malicious additive distortion to the labels. We prove (nearly optimal) trade-offs among the magnitude of the adversarial attack, the accuracy and the confidence achieved by the proposed algorithm.
* 11 pages
View paper on