 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImageRAGTurbo: Towards One-step Text-to-Image Generation with Retrieval-Augmented Diffusion Models
Feb 13, 2026Diffusion models have emerged as the leading approach for text-to-image generation. However, their iterative sampling process, which gradually morphs random noise into coherent images, introduces significant latency that limits their applicability. While recent few-step diffusion models reduce the number of sampling steps to as few as one to four steps, they often compromise image quality and prompt alignment, especially in one-step generation. Additionally, these models require computationally expensive training procedures. To address these limitations, we propose ImageRAGTurbo, a novel approach to efficiently finetune few-step diffusion models via retrieval augmentation. Given a text prompt, we retrieve relevant text-image pairs from a database and use them to condition the generation process. We argue that such retrieved examples provide rich contextual information to the UNet denoiser that helps reduce the number of denoising steps without compromising image quality. Indeed, our initial investigations show that using the retrieved content to edit the denoiser's latent space ($\mathcal{H}$-space) without additional finetuning already improves prompt fidelity. To further improve the quality of the generated images, we augment the UNet denoiser with a trainable adapter in the $\mathcal{H}$-space, which efficiently blends the retrieved content with the target prompt using a cross-attention mechanism. Experimental results on fast text-to-image generation demonstrate that our approach produces high-fidelity images without compromising latency compared to existing methods.
Rethinking Visual Information Processing in Multimodal LLMs
Nov 13, 2025
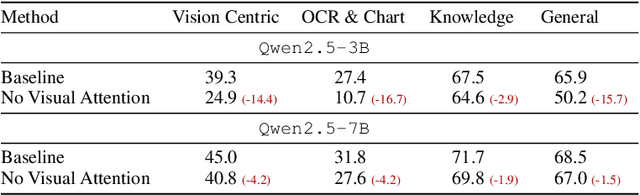
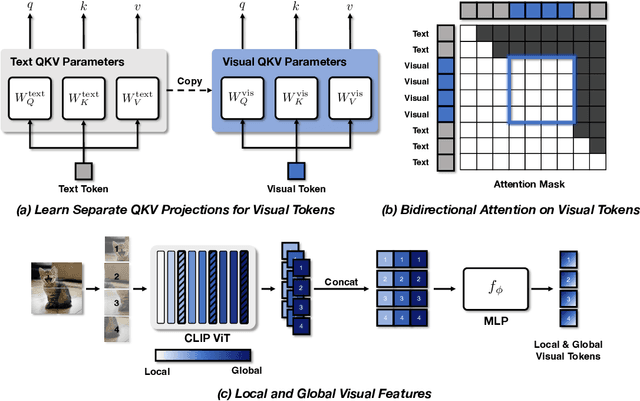
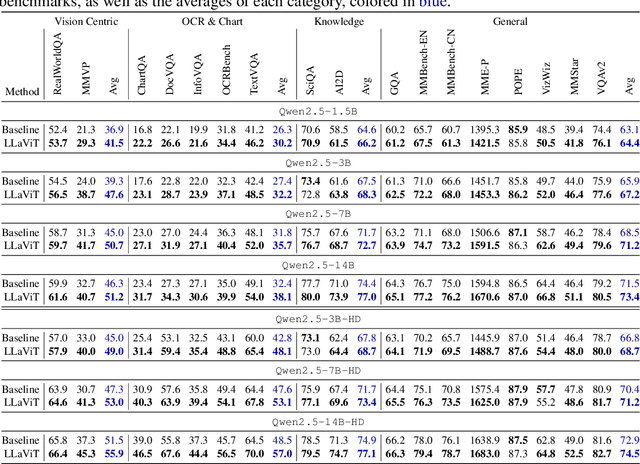
Despite the remarkable success of the LLaVA architecture for vision-language tasks, its design inherently struggles to effectively integrate visual features due to the inherent mismatch between text and vision modalities. We tackle this issue from a novel perspective in which the LLM not only serves as a language model but also a powerful vision encoder. To this end, we present LLaViT - Large Language Models as extended Vision Transformers - which enables the LLM to simultaneously function as a vision encoder through three key modifications: (1) learning separate QKV projections for vision modality, (2) enabling bidirectional attention on visual tokens, and (3) incorporating both global and local visual representations. Through extensive controlled experiments on a wide range of LLMs, we demonstrate that LLaViT significantly outperforms the baseline LLaVA method on a multitude of benchmarks, even surpassing models with double its parameter count, establishing a more effective approach to vision-language modeling.
Unsupervised and semi-supervised co-salient object detection via segmentation frequency statistics
Nov 11, 2023In this paper, we address the detection of co-occurring salient objects (CoSOD) in an image group using frequency statistics in an unsupervised manner, which further enable us to develop a semi-supervised method. While previous works have mostly focused on fully supervised CoSOD, less attention has been allocated to detecting co-salient objects when limited segmentation annotations are available for training. Our simple yet effective unsupervised method US-CoSOD combines the object co-occurrence frequency statistics of unsupervised single-image semantic segmentations with salient foreground detections using self-supervised feature learning. For the first time, we show that a large unlabeled dataset e.g. ImageNet-1k can be effectively leveraged to significantly improve unsupervised CoSOD performance. Our unsupervised model is a great pre-training initialization for our semi-supervised model SS-CoSOD, especially when very limited labeled data is available for training. To avoid propagating erroneous signals from predictions on unlabeled data, we propose a confidence estimation module to guide our semi-supervised training. Extensive experiments on three CoSOD benchmark datasets show that both of our unsupervised and semi-supervised models outperform the corresponding state-of-the-art models by a significant margin (e.g., on the Cosal2015 dataset, our US-CoSOD model has an 8.8% F-measure gain over a SOTA unsupervised co-segmentation model and our SS-CoSOD model has an 11.81% F-measure gain over a SOTA semi-supervised CoSOD model).
On Utilizing Relationships for Transferable Few-Shot Fine-Grained Object Detection
Dec 01, 2022
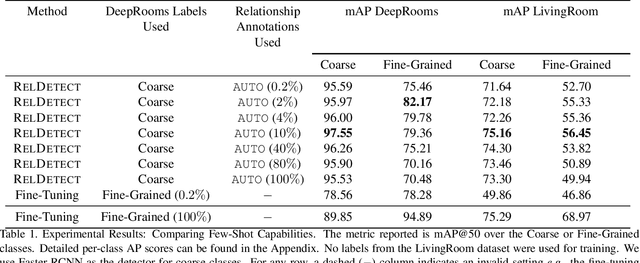
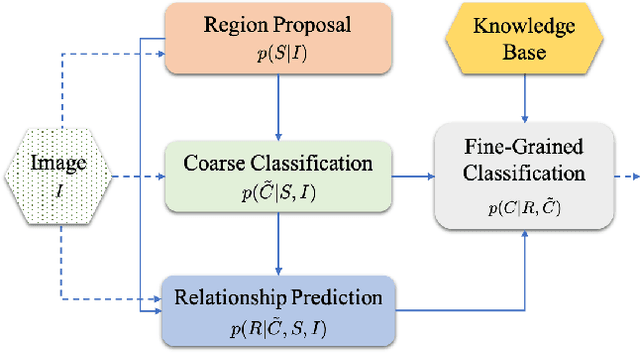
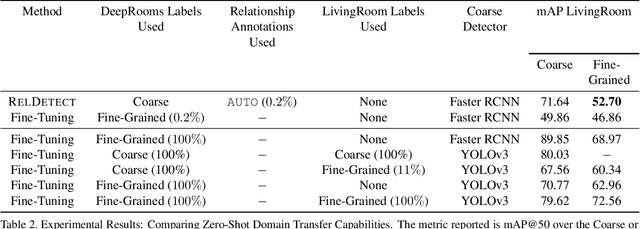
State-of-the-art object detectors are fast and accurate, but they require a large amount of well annotated training data to obtain good performance. However, obtaining a large amount of training annotations specific to a particular task, i.e., fine-grained annotations, is costly in practice. In contrast, obtaining common-sense relationships from text, e.g., "a table-lamp is a lamp that sits on top of a table", is much easier. Additionally, common-sense relationships like "on-top-of" are easy to annotate in a task-agnostic fashion. In this paper, we propose a probabilistic model that uses such relational knowledge to transform an off-the-shelf detector of coarse object categories (e.g., "table", "lamp") into a detector of fine-grained categories (e.g., "table-lamp"). We demonstrate that our method, RelDetect, achieves performance competitive to finetuning based state-of-the-art object detector baselines when an extremely low amount of fine-grained annotations is available ($0.2\%$ of entire dataset). We also demonstrate that RelDetect is able to utilize the inherent transferability of relationship information to obtain a better performance ($+5$ mAP points) than the above baselines on an unseen dataset (zero-shot transfer). In summary, we demonstrate the power of using relationships for object detection on datasets where fine-grained object categories can be linked to coarse-grained categories via suitable relationships.