 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Free and Group Conditional Online Conformal Prediction
May 29, 2026Uncertainty quantification (UQ) is critical for the deployment of machine learning predictors in real-world scenarios where the data distribution may shift over time (i.e., data may not be exchangeable). Online conformal prediction (OCP) methods address this issue at the expense of either (i) group-wise error control or (ii) learning-rate independent implementation. Group-conditional coverage is essential for fairness across different collections of data points and for providing finer UQ guarantees. Parameter-free optimization is crucial for robustness to adversarial and unknown data shifts. We propose a parameter-free algorithm for group-conditional OCP and demonstrate that it achieves the best group-conditional coverage guarantees.We evaluate our algorithm on synthetic and real-world data, demonstrating that our method not only improves the reliability of existing parameter-free OCP methods but also provides prediction intervals that are comparable in size to well-tuned group-conditional approaches. By unifying group-conditional coverage with parameter-free online algorithms, our work lays a foundation for fair and robust uncertainty quantification in shifting environments.
Protein Design with Agent Rosetta: A Case Study for Specialized Scientific Agents
Mar 16, 2026Large language models (LLMs) are capable of emulating reasoning and using tools, creating opportunities for autonomous agents that execute complex scientific tasks. Protein design provides a natural testbed: although machine learning (ML) methods achieve strong results, these are largely restricted to canonical amino acids and narrow objectives, leaving unfilled need for a generalist tool for broad design pipelines. We introduce Agent Rosetta, an LLM agent paired with a structured environment for operating Rosetta, the leading physics-based heteropolymer design software, capable of modeling non-canonical building blocks and geometries. Agent Rosetta iteratively refines designs to achieve user-defined objectives, combining LLM reasoning with Rosetta's generality. We evaluate Agent Rosetta on design with canonical amino acids, matching specialized models and expert baselines, and with non-canonical residues -- where ML approaches fail -- achieving comparable performance. Critically, prompt engineering alone often fails to generate Rosetta actions, demonstrating that environment design is essential for integrating LLM agents with specialized software. Our results show that properly designed environments enable LLM agents to make scientific software accessible while matching specialized tools and human experts.
Aligning Explanations with Human Communication
May 21, 2025


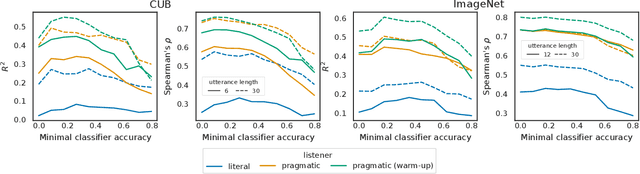
Machine learning explainability aims to make the decision-making process of black-box models more transparent by finding the most important input features for a given prediction task. Recent works have proposed composing explanations from semantic concepts (e.g., colors, patterns, shapes) that are inherently interpretable to the user of a model. However, these methods generally ignore the communicative context of explanation-the ability of the user to understand the prediction of the model from the explanation. For example, while a medical doctor might understand an explanation in terms of clinical markers, a patient may need a more accessible explanation to make sense of the same diagnosis. In this paper, we address this gap with listener-adaptive explanations. We propose an iterative procedure grounded in principles of pragmatic reasoning and the rational speech act to generate explanations that maximize communicative utility. Our procedure only needs access to pairwise preferences between candidate explanations, relevant in real-world scenarios where a listener model may not be available. We evaluate our method in image classification tasks, demonstrating improved alignment between explanations and listener preferences across three datasets. Furthermore, we perform a user study that demonstrates our explanations increase communicative utility.
I Bet You Did Not Mean That: Testing Semantic Importance via Betting
May 29, 2024



Recent works have extended notions of feature importance to \emph{semantic concepts} that are inherently interpretable to the users interacting with a black-box predictive model. Yet, precise statistical guarantees, such as false positive rate control, are needed to communicate findings transparently and to avoid unintended consequences in real-world scenarios. In this paper, we formalize the global (i.e., over a population) and local (i.e., for a sample) statistical importance of semantic concepts for the predictions of opaque models, by means of conditional independence, which allows for rigorous testing. We use recent ideas of sequential kernelized testing (SKIT) to induce a rank of importance across concepts, and showcase the effectiveness and flexibility of our framework on synthetic datasets as well as on image classification tasks using vision-language models such as CLIP.
How to Trust Your Diffusion Model: A Convex Optimization Approach to Conformal Risk Control
Feb 07, 2023Score-based generative modeling, informally referred to as diffusion models, continue to grow in popularity across several important domains and tasks. While they provide high-quality and diverse samples from empirical distributions, important questions remain on the reliability and trustworthiness of these sampling procedures for their responsible use in critical scenarios. Conformal prediction is a modern tool to construct finite-sample, distribution-free uncertainty guarantees for any black-box predictor. In this work, we focus on image-to-image regression tasks and we present a generalization of the Risk-Controlling Prediction Sets (RCPS) procedure, that we term $K$-RCPS, which allows to $(i)$ provide entrywise calibrated intervals for future samples of any diffusion model, and $(ii)$ control a certain notion of risk with respect to a ground truth image with minimal mean interval length. Differently from existing conformal risk control procedures, ours relies on a novel convex optimization approach that allows for multidimensional risk control while provably minimizing the mean interval length. We illustrate our approach on two real-world image denoising problems: on natural images of faces as well as on computed tomography (CT) scans of the abdomen, demonstrating state of the art performance.
Weakly Supervised Learning Significantly Reduces the Number of Labels Required for Intracranial Hemorrhage Detection on Head CT
Nov 29, 2022



Modern machine learning pipelines, in particular those based on deep learning (DL) models, require large amounts of labeled data. For classification problems, the most common learning paradigm consists of presenting labeled examples during training, thus providing strong supervision on what constitutes positive and negative samples. This constitutes a major obstacle for the development of DL models in radiology--in particular for cross-sectional imaging (e.g., computed tomography [CT] scans)--where labels must come from manual annotations by expert radiologists at the image or slice-level. These differ from examination-level annotations, which are coarser but cheaper, and could be extracted from radiology reports using natural language processing techniques. This work studies the question of what kind of labels should be collected for the problem of intracranial hemorrhage detection in brain CT. We investigate whether image-level annotations should be preferred to examination-level ones. By framing this task as a multiple instance learning problem, and employing modern attention-based DL architectures, we analyze the degree to which different levels of supervision improve detection performance. We find that strong supervision (i.e., learning with local image-level annotations) and weak supervision (i.e., learning with only global examination-level labels) achieve comparable performance in examination-level hemorrhage detection (the task of selecting the images in an examination that show signs of hemorrhage) as well as in image-level hemorrhage detection (highlighting those signs within the selected images). Furthermore, we study this behavior as a function of the number of labels available during training. Our results suggest that local labels may not be necessary at all for these tasks, drastically reducing the time and cost involved in collecting and curating datasets.
From Shapley back to Pearson: Hypothesis Testing via the Shapley Value
Jul 14, 2022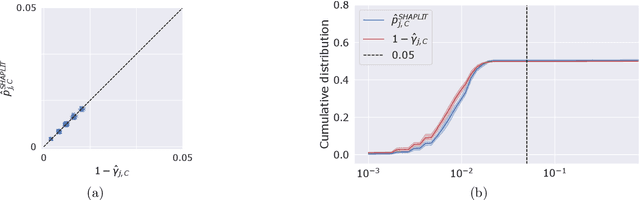
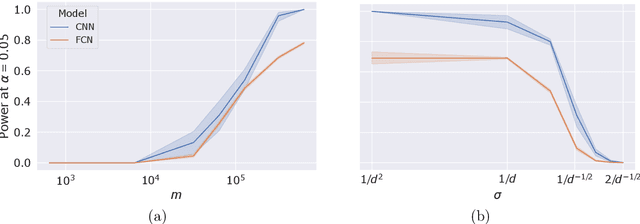
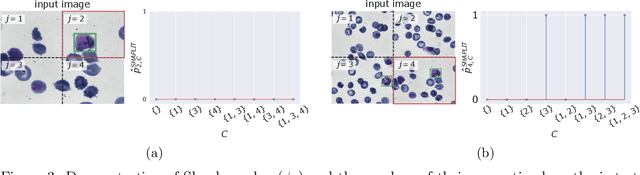
Machine learning models, in particular artificial neural networks, are increasingly used to inform decision making in high-stakes scenarios across a variety of fields--from financial services, to public safety, and healthcare. While neural networks have achieved remarkable performance in many settings, their complex nature raises concerns on their reliability, trustworthiness, and fairness in real-world scenarios. As a result, several a-posteriori explanation methods have been proposed to highlight the features that influence a model's prediction. Notably, the Shapley value--a game theoretic quantity that satisfies several desirable properties--has gained popularity in the machine learning explainability literature. More traditionally, however, feature importance in statistical learning has been formalized by conditional independence, and a standard way to test for it is via Conditional Randomization Tests (CRTs). So far, these two perspectives on interpretability and feature importance have been considered distinct and separate. In this work, we show that Shapley-based explanation methods and conditional independence testing for feature importance are closely related. More precisely, we prove that evaluating a Shapley coefficient amounts to performing a specific set of conditional independence tests, as implemented by a procedure similar to the CRT but for a different null hypothesis. Furthermore, the obtained game-theoretic values upper bound the $p$-values of such tests. As a result, we grant large Shapley coefficients with a precise statistical sense of importance with controlled type I error.
Fast Hierarchical Games for Image Explanations
Apr 13, 2021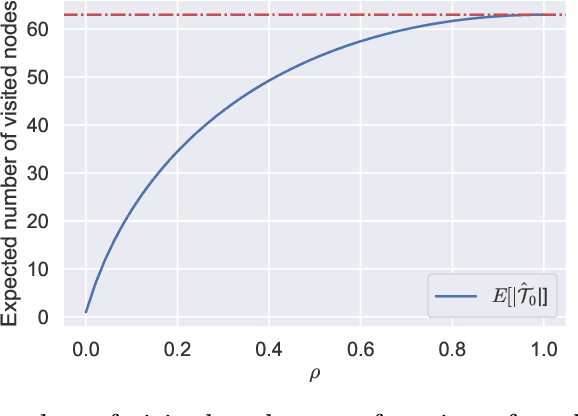
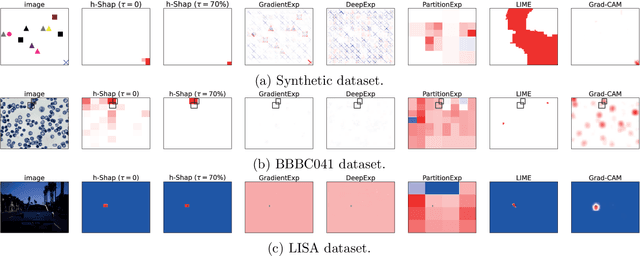

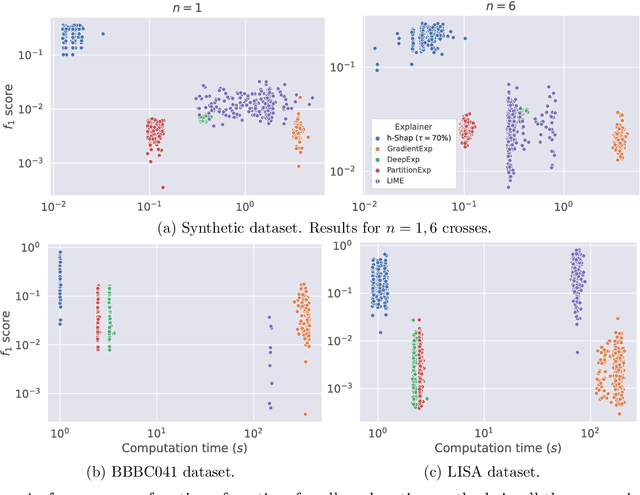
As modern complex neural networks keep breaking records and solving harder problems, their predictions also become less and less intelligible. The current lack of interpretability often undermines the deployment of accurate machine learning tools in sensitive settings. In this work, we present a model-agnostic explanation method for image classification based on a hierarchical extension of Shapley coefficients --Hierarchical Shap (h-Shap)-- that resolves some of the limitations of current approaches. Unlike other Shapley-based explanation methods, h-Shap is scalable and can be computed without the need of approximation. Under certain distributional assumptions, such as those common in multiple instance learning, h-Shap retrieves the exact Shapley coefficients with an exponential improvement in computational complexity. We compare our hierarchical approach with popular Shapley-based and non-Shapley-based methods on a synthetic dataset, a medical imaging scenario, and a general computer vision problem, showing that h-Shap outperforms the state of the art in both accuracy and runtime. Code and experiments are made publicly available.