 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusionQC: Artifact Detection in Histopathology via Diffusion Model
Jan 18, 2026Digital pathology plays a vital role across modern medicine, offering critical insights for disease diagnosis, prognosis, and treatment. However, histopathology images often contain artifacts introduced during slide preparation and digitization. Detecting and excluding them is essential to ensure reliable downstream analysis. Traditional supervised models typically require large annotated datasets, which is resource-intensive and not generalizable to novel artifact types. To address this, we propose DiffusionQC, which detects artifacts as outliers among clean images using a diffusion model. It requires only a set of clean images for training rather than pixel-level artifact annotations and predefined artifact types. Furthermore, we introduce a contrastive learning module to explicitly enlarge the distribution separation between artifact and clean images, yielding an enhanced version of our method. Empirical results demonstrate superior performance to state-of-the-art and offer cross-stain generalization capacity, with significantly less data and annotations.
Aligning Explanations with Human Communication
May 21, 2025


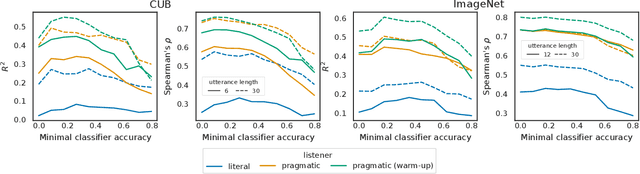
Machine learning explainability aims to make the decision-making process of black-box models more transparent by finding the most important input features for a given prediction task. Recent works have proposed composing explanations from semantic concepts (e.g., colors, patterns, shapes) that are inherently interpretable to the user of a model. However, these methods generally ignore the communicative context of explanation-the ability of the user to understand the prediction of the model from the explanation. For example, while a medical doctor might understand an explanation in terms of clinical markers, a patient may need a more accessible explanation to make sense of the same diagnosis. In this paper, we address this gap with listener-adaptive explanations. We propose an iterative procedure grounded in principles of pragmatic reasoning and the rational speech act to generate explanations that maximize communicative utility. Our procedure only needs access to pairwise preferences between candidate explanations, relevant in real-world scenarios where a listener model may not be available. We evaluate our method in image classification tasks, demonstrating improved alignment between explanations and listener preferences across three datasets. Furthermore, we perform a user study that demonstrates our explanations increase communicative utility.
Label Cleaning Multiple Instance Learning: Refining Coarse Annotations on Single Whole-Slide Images
Sep 22, 2021
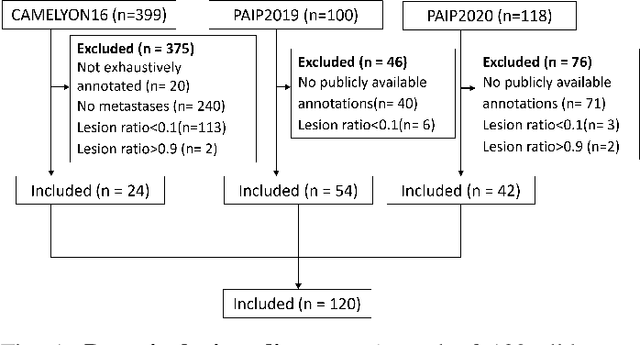

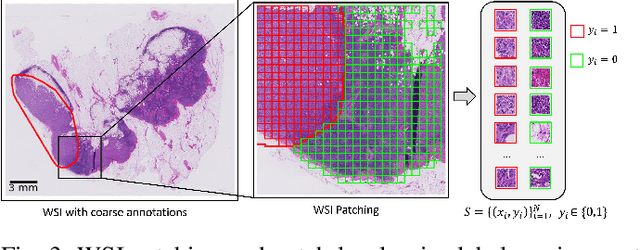
Annotating cancerous regions in whole-slide images (WSIs) of pathology samples plays a critical role in clinical diagnosis, biomedical research, and machine learning algorithms development. However, generating exhaustive and accurate annotations is labor-intensive, challenging, and costly. Drawing only coarse and approximate annotations is a much easier task, less costly, and it alleviates pathologists' workload. In this paper, we study the problem of refining these approximate annotations in digital pathology to obtain more accurate ones. Some previous works have explored obtaining machine learning models from these inaccurate annotations, but few of them tackle the refinement problem where the mislabeled regions should be explicitly identified and corrected, and all of them require a - often very large - number of training samples. We present a method, named Label Cleaning Multiple Instance Learning (LC-MIL), to refine coarse annotations on a single WSI without the need of external training data. Patches cropped from a WSI with inaccurate labels are processed jointly with a MIL framework, and a deep-attention mechanism is leveraged to discriminate mislabeled instances, mitigating their impact on the predictive model and refining the segmentation. Our experiments on a heterogeneous WSI set with breast cancer lymph node metastasis, liver cancer, and colorectal cancer samples show that LC-MIL significantly refines the coarse annotations, outperforming the state-of-the-art alternatives, even while learning from a single slide. These results demonstrate the LC-MIL is a promising, lightweight tool to provide fine-grained annotations from coarsely annotated pathology sets.
Attention-Aware Noisy Label Learning for Image Classification
Sep 30, 2020
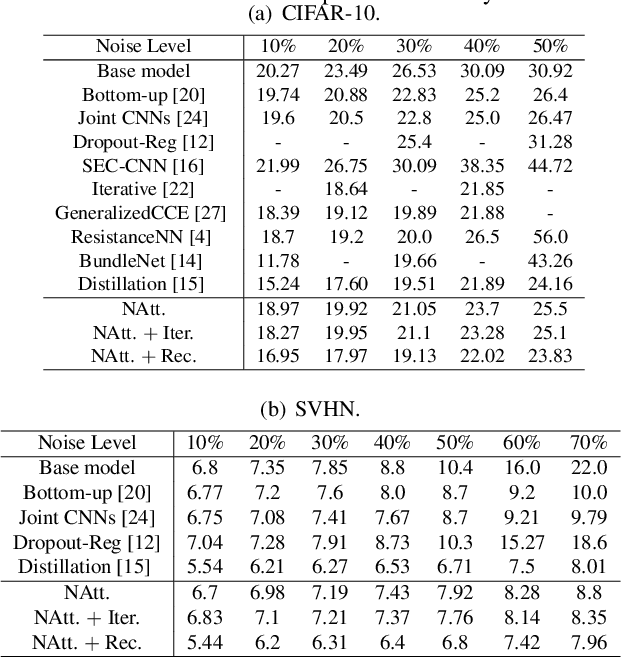
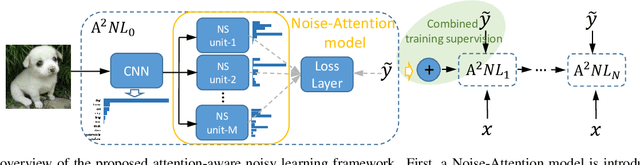
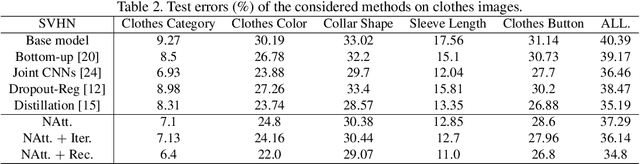
Deep convolutional neural networks (CNNs) learned on large-scale labeled samples have achieved remarkable progress in computer vision, such as image/video classification. The cheapest way to obtain a large body of labeled visual data is to crawl from websites with user-supplied labels, such as Flickr. However, these samples often tend to contain incorrect labels (i.e. noisy labels), which will significantly degrade the network performance. In this paper, the attention-aware noisy label learning approach ($A^2NL$) is proposed to improve the discriminative capability of the network trained on datasets with potential label noise. Specifically, a Noise-Attention model, which contains multiple noise-specific units, is designed to better capture noisy information. Each unit is expected to learn a specific noisy distribution for a subset of images so that different disturbances are more precisely modeled. Furthermore, a recursive learning process is introduced to strengthen the learning ability of the attention network by taking advantage of the learned high-level knowledge. To fully evaluate the proposed method, we conduct experiments from two aspects: manually flipped label noise on large-scale image classification datasets, including CIFAR-10, SVHN; and real-world label noise on an online crawled clothing dataset with multiple attributes. The superior results over state-of-the-art methods validate the effectiveness of our proposed approach.
Deep Reinforcement Learning with Label Embedding Reward for Supervised Image Hashing
Aug 10, 2020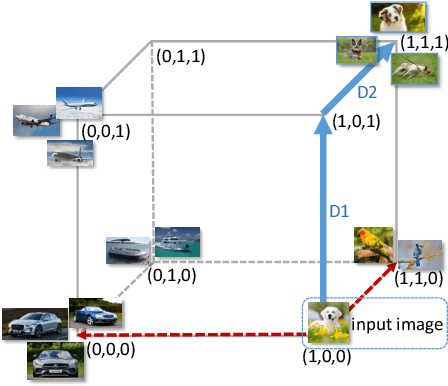
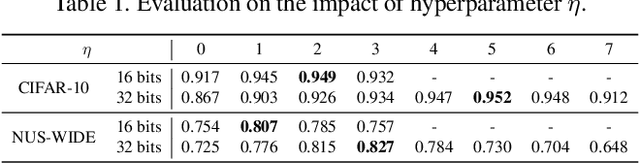
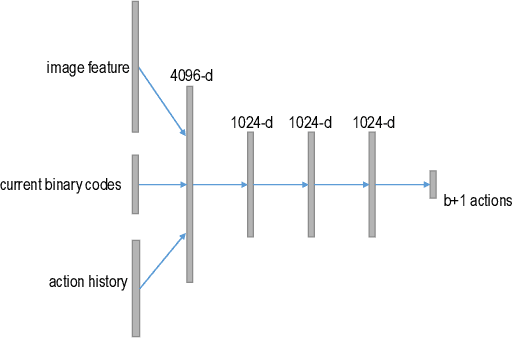
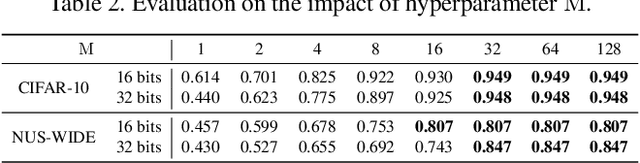
Deep hashing has shown promising results in image retrieval and recognition. Despite its success, most existing deep hashing approaches are rather similar: either multi-layer perceptron or CNN is applied to extract image feature, followed by different binarization activation functions such as sigmoid, tanh or autoencoder to generate binary code. In this work, we introduce a novel decision-making approach for deep supervised hashing. We formulate the hashing problem as travelling across the vertices in the binary code space, and learn a deep Q-network with a novel label embedding reward defined by Bose-Chaudhuri-Hocquenghem (BCH) codes to explore the best path. Extensive experiments and analysis on the CIFAR-10 and NUS-WIDE dataset show that our approach outperforms state-of-the-art supervised hashing methods under various code lengths.