 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Cleaning Multiple Instance Learning: Refining Coarse Annotations on Single Whole-Slide Images
Paper and Code

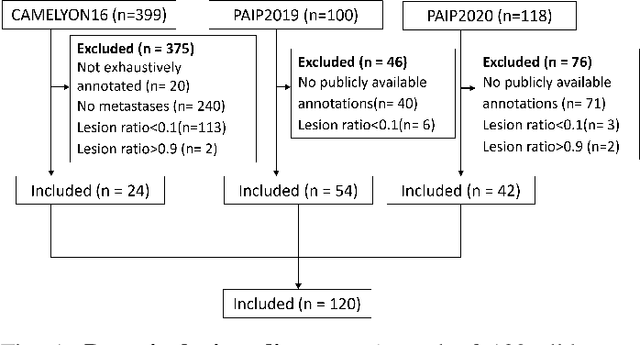

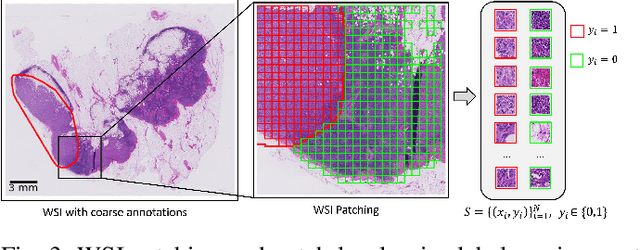
Annotating cancerous regions in whole-slide images (WSIs) of pathology samples plays a critical role in clinical diagnosis, biomedical research, and machine learning algorithms development. However, generating exhaustive and accurate annotations is labor-intensive, challenging, and costly. Drawing only coarse and approximate annotations is a much easier task, less costly, and it alleviates pathologists' workload. In this paper, we study the problem of refining these approximate annotations in digital pathology to obtain more accurate ones. Some previous works have explored obtaining machine learning models from these inaccurate annotations, but few of them tackle the refinement problem where the mislabeled regions should be explicitly identified and corrected, and all of them require a - often very large - number of training samples. We present a method, named Label Cleaning Multiple Instance Learning (LC-MIL), to refine coarse annotations on a single WSI without the need of external training data. Patches cropped from a WSI with inaccurate labels are processed jointly with a MIL framework, and a deep-attention mechanism is leveraged to discriminate mislabeled instances, mitigating their impact on the predictive model and refining the segmentation. Our experiments on a heterogeneous WSI set with breast cancer lymph node metastasis, liver cancer, and colorectal cancer samples show that LC-MIL significantly refines the coarse annotations, outperforming the state-of-the-art alternatives, even while learning from a single slide. These results demonstrate the LC-MIL is a promising, lightweight tool to provide fine-grained annotations from coarsely annotated pathology sets.