 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamlining Conformal Information Retrieval via Score Refinement
Oct 03, 2024
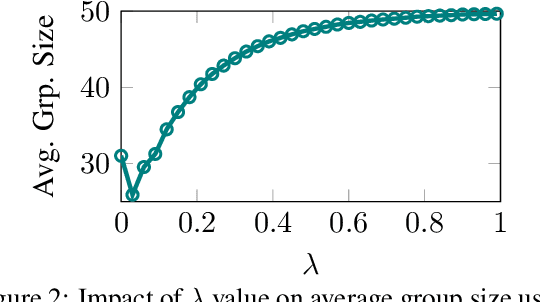
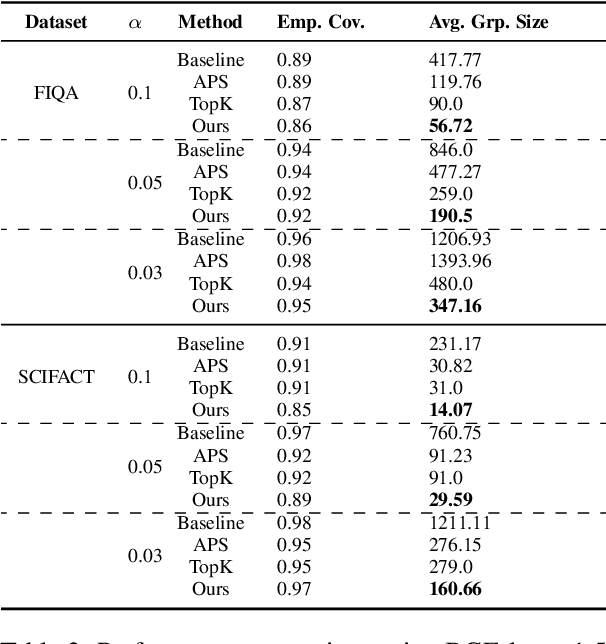
Information retrieval (IR) methods, like retrieval augmented generation, are fundamental to modern applications but often lack statistical guarantees. Conformal prediction addresses this by retrieving sets guaranteed to include relevant information, yet existing approaches produce large-sized sets, incurring high computational costs and slow response times. In this work, we introduce a score refinement method that applies a simple monotone transformation to retrieval scores, leading to significantly smaller conformal sets while maintaining their statistical guarantees. Experiments on various BEIR benchmarks validate the effectiveness of our approach in producing compact sets containing relevant information.
Semantic Parsing of Colonoscopy Videos with Multi-Label Temporal Networks
Jun 12, 2023Following the successful debut of polyp detection and characterization, more advanced automation tools are being developed for colonoscopy. The new automation tasks, such as quality metrics or report generation, require understanding of the procedure flow that includes activities, events, anatomical landmarks, etc. In this work we present a method for automatic semantic parsing of colonoscopy videos. The method uses a novel DL multi-label temporal segmentation model trained in supervised and unsupervised regimes. We evaluate the accuracy of the method on a test set of over 300 annotated colonoscopy videos, and use ablation to explore the relative importance of various method's components.
Motion-Based Weak Supervision for Video Parsing with Application to Colonoscopy
Oct 16, 2022



We propose a two-stage unsupervised approach for parsing videos into phases. We use motion cues to divide the video into coarse segments. Noisy segment labels are then used to weakly supervise an appearance-based classifier. We show the effectiveness of the method for phase detection in colonoscopy videos.
Learning Halfspaces With Membership Queries
Dec 20, 2020



Active learning is a subfield of machine learning, in which the learning algorithm is allowed to choose the data from which it learns. In some cases, it has been shown that active learning can yield an exponential gain in the number of samples the algorithm needs to see, in order to reach generalization error $\leq \epsilon$. In this work we study the problem of learning halfspaces with membership queries. In the membership query scenario, we allow the learning algorithm to ask for the label of every sample in the input space. We suggest a new algorithm for this problem, and prove it achieves a near optimal label complexity in some cases. We also show that the algorithm works well in practice, and significantly outperforms uncertainty sampling.