 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Noise: Aligning Prompts with Latent Representations in Diffusion Models
Dec 09, 2025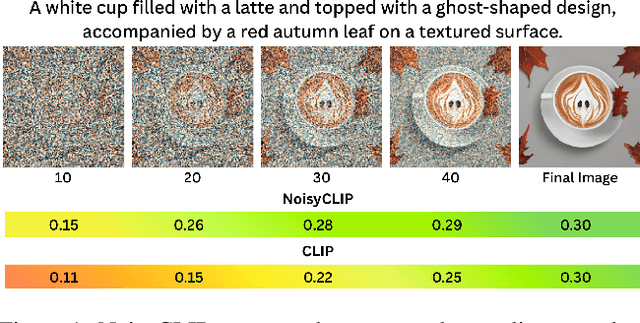
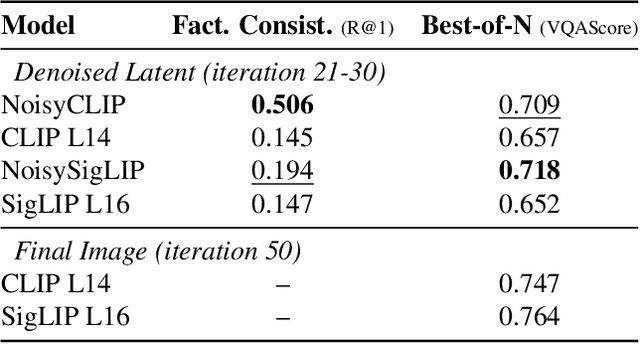
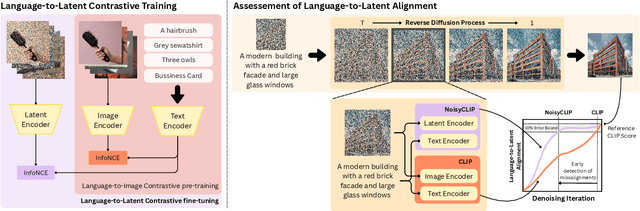
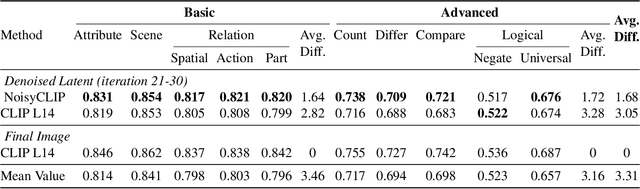
Conditional diffusion models rely on language-to-image alignment methods to steer the generation towards semantically accurate outputs. Despite the success of this architecture, misalignment and hallucinations remain common issues and require automatic misalignment detection tools to improve quality, for example by applying them in a Best-of-N (BoN) post-generation setting. Unfortunately, measuring the alignment after the generation is an expensive step since we need to wait for the overall generation to finish to determine prompt adherence. In contrast, this work hypothesizes that text/image misalignments can be detected early in the denoising process, enabling real-time alignment assessment without waiting for the complete generation. In particular, we propose NoisyCLIP a method that measures semantic alignment in the noisy latent space. This work is the first to explore and benchmark prompt-to-latent misalignment detection during image generation using dual encoders in the reverse diffusion process. We evaluate NoisyCLIP qualitatively and quantitatively and find it reduces computational cost by 50% while achieving 98% of CLIP alignment performance in BoN settings. This approach enables real-time alignment assessment during generation, reducing costs without sacrificing semantic fidelity.
Latent Beam Diffusion Models for Decoding Image Sequences
Mar 26, 2025While diffusion models excel at generating high-quality images from text prompts, they struggle with visual consistency in image sequences. Existing methods generate each image independently, leading to disjointed narratives - a challenge further exacerbated in non-linear storytelling, where scenes must connect beyond adjacent frames. We introduce a novel beam search strategy for latent space exploration, enabling conditional generation of full image sequences with beam search decoding. Unlike prior approaches that use fixed latent priors, our method dynamically searches for an optimal sequence of latent representations, ensuring coherent visual transitions. To address beam search's quadratic complexity, we integrate a cross-attention mechanism that efficiently scores search paths and enables pruning, prioritizing alignment with both textual prompts and visual context. Human evaluations confirm that our approach outperforms baseline methods, producing full sequences with superior coherence, visual continuity, and textual alignment. By bridging advances in search optimization and latent space refinement, this work sets a new standard for structured image sequence generation.
Contrastive Sequential-Diffusion Learning: An approach to Multi-Scene Instructional Video Synthesis
Jul 16, 2024



Action-centric sequence descriptions like recipe instructions and do-it-yourself projects include non-linear patterns in which the next step may require to be visually consistent not on the immediate previous step but on earlier steps. Current video synthesis approaches fail to generate consistent multi-scene videos for such task descriptions. We propose a contrastive sequential video diffusion method that selects the most suitable previously generated scene to guide and condition the denoising process of the next scene. The result is a multi-scene video that is grounded in the scene descriptions and coherent w.r.t the scenes that require consistent visualisation. Our experiments with real-world data demonstrate the practicality and improved consistency of our model compared to prior work.
Generating Coherent Sequences of Visual Illustrations for Real-World Manual Tasks
May 16, 2024



Multistep instructions, such as recipes and how-to guides, greatly benefit from visual aids, such as a series of images that accompany the instruction steps. While Large Language Models (LLMs) have become adept at generating coherent textual steps, Large Vision/Language Models (LVLMs) are less capable of generating accompanying image sequences. The most challenging aspect is that each generated image needs to adhere to the relevant textual step instruction, as well as be visually consistent with earlier images in the sequence. To address this problem, we propose an approach for generating consistent image sequences, which integrates a Latent Diffusion Model (LDM) with an LLM to transform the sequence into a caption to maintain the semantic coherence of the sequence. In addition, to maintain the visual coherence of the image sequence, we introduce a copy mechanism to initialise reverse diffusion processes with a latent vector iteration from a previously generated image from a relevant step. Both strategies will condition the reverse diffusion process on the sequence of instruction steps and tie the contents of the current image to previous instruction steps and corresponding images. Experiments show that the proposed approach is preferred by humans in 46.6% of the cases against 26.6% for the second best method. In addition, automatic metrics showed that the proposed method maintains semantic coherence and visual consistency across steps in both domains.
TWIZ: The Wizard of Multimodal Conversational-Stimulus
Oct 03, 2023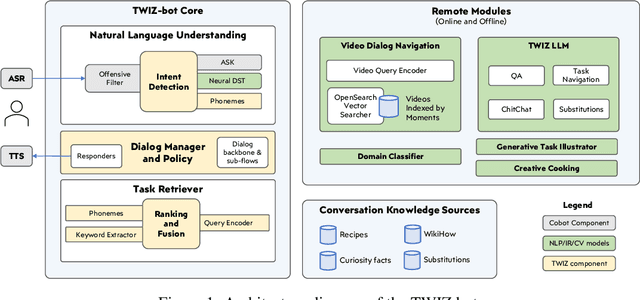

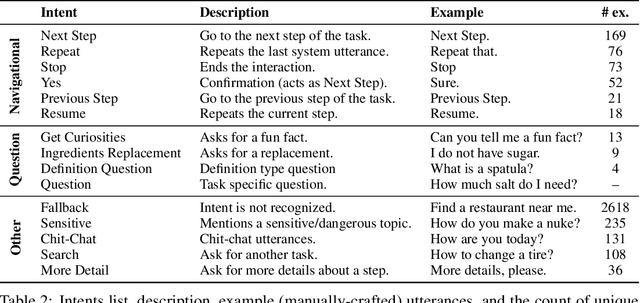
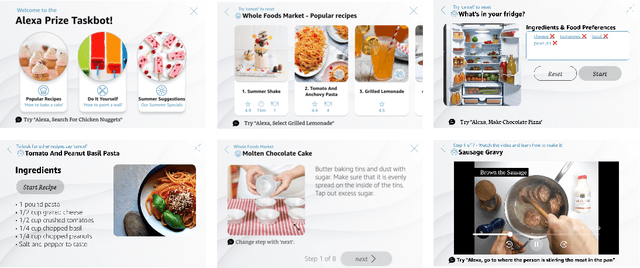
In this report, we describe the vision, challenges, and scientific contributions of the Task Wizard team, TWIZ, in the Alexa Prize TaskBot Challenge 2022. Our vision, is to build TWIZ bot as an helpful, multimodal, knowledgeable, and engaging assistant that can guide users towards the successful completion of complex manual tasks. To achieve this, we focus our efforts on three main research questions: (1) Humanly-Shaped Conversations, by providing information in a knowledgeable way; (2) Multimodal Stimulus, making use of various modalities including voice, images, and videos; and (3) Zero-shot Conversational Flows, to improve the robustness of the interaction to unseen scenarios. TWIZ is an assistant capable of supporting a wide range of tasks, with several innovative features such as creative cooking, video navigation through voice, and the robust TWIZ-LLM, a Large Language Model trained for dialoguing about complex manual tasks. Given ratings and feedback provided by users, we observed that TWIZ bot is an effective and robust system, capable of guiding users through tasks while providing several multimodal stimuli.