 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIGiA: Instructional Video Guidance via Dialogue Reasoning and Retrieval
Feb 22, 2026We introduce VIGiA, a novel multimodal dialogue model designed to understand and reason over complex, multi-step instructional video action plans. Unlike prior work which focuses mainly on text-only guidance, or treats vision and language in isolation, VIGiA supports grounded, plan-aware dialogue that requires reasoning over visual inputs, instructional plans, and interleaved user interactions. To this end, VIGiA incorporates two key capabilities: (1) multimodal plan reasoning, enabling the model to align uni- and multimodal queries with the current task plan and respond accurately; and (2) plan-based retrieval, allowing it to retrieve relevant plan steps in either textual or visual representations. Experiments were done on a novel dataset with rich Instructional Video Dialogues aligned with Cooking and DIY plans. Our evaluation shows that VIGiA outperforms existing state-of-the-art models on all tasks in a conversational plan guidance setting, reaching over 90\% accuracy on plan-aware VQA.
RedTWIZ: Diverse LLM Red Teaming via Adaptive Attack Planning
Oct 08, 2025This paper presents the vision, scientific contributions, and technical details of RedTWIZ: an adaptive and diverse multi-turn red teaming framework, to audit the robustness of Large Language Models (LLMs) in AI-assisted software development. Our work is driven by three major research streams: (1) robust and systematic assessment of LLM conversational jailbreaks; (2) a diverse generative multi-turn attack suite, supporting compositional, realistic and goal-oriented jailbreak conversational strategies; and (3) a hierarchical attack planner, which adaptively plans, serializes, and triggers attacks tailored to specific LLM's vulnerabilities. Together, these contributions form a unified framework -- combining assessment, attack generation, and strategic planning -- to comprehensively evaluate and expose weaknesses in LLMs' robustness. Extensive evaluation is conducted to systematically assess and analyze the performance of the overall system and each component. Experimental results demonstrate that our multi-turn adversarial attack strategies can successfully lead state-of-the-art LLMs to produce unsafe generations, highlighting the pressing need for more research into enhancing LLM's robustness.
Show and Guide: Instructional-Plan Grounded Vision and Language Model
Sep 27, 2024



Guiding users through complex procedural plans is an inherently multimodal task in which having visually illustrated plan steps is crucial to deliver an effective plan guidance. However, existing works on plan-following language models (LMs) often are not capable of multimodal input and output. In this work, we present MM-PlanLLM, the first multimodal LLM designed to assist users in executing instructional tasks by leveraging both textual plans and visual information. Specifically, we bring cross-modality through two key tasks: Conversational Video Moment Retrieval, where the model retrieves relevant step-video segments based on user queries, and Visually-Informed Step Generation, where the model generates the next step in a plan, conditioned on an image of the user's current progress. MM-PlanLLM is trained using a novel multitask-multistage approach, designed to gradually expose the model to multimodal instructional-plans semantic layers, achieving strong performance on both multimodal and textual dialogue in a plan-grounded setting. Furthermore, we show that the model delivers cross-modal temporal and plan-structure representations aligned between textual plan steps and instructional video moments.
Generating Coherent Sequences of Visual Illustrations for Real-World Manual Tasks
May 16, 2024



Multistep instructions, such as recipes and how-to guides, greatly benefit from visual aids, such as a series of images that accompany the instruction steps. While Large Language Models (LLMs) have become adept at generating coherent textual steps, Large Vision/Language Models (LVLMs) are less capable of generating accompanying image sequences. The most challenging aspect is that each generated image needs to adhere to the relevant textual step instruction, as well as be visually consistent with earlier images in the sequence. To address this problem, we propose an approach for generating consistent image sequences, which integrates a Latent Diffusion Model (LDM) with an LLM to transform the sequence into a caption to maintain the semantic coherence of the sequence. In addition, to maintain the visual coherence of the image sequence, we introduce a copy mechanism to initialise reverse diffusion processes with a latent vector iteration from a previously generated image from a relevant step. Both strategies will condition the reverse diffusion process on the sequence of instruction steps and tie the contents of the current image to previous instruction steps and corresponding images. Experiments show that the proposed approach is preferred by humans in 46.6% of the cases against 26.6% for the second best method. In addition, automatic metrics showed that the proposed method maintains semantic coherence and visual consistency across steps in both domains.
Plan-Grounded Large Language Models for Dual Goal Conversational Settings
Feb 01, 2024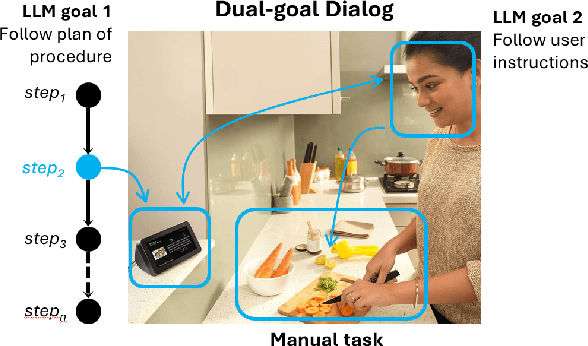
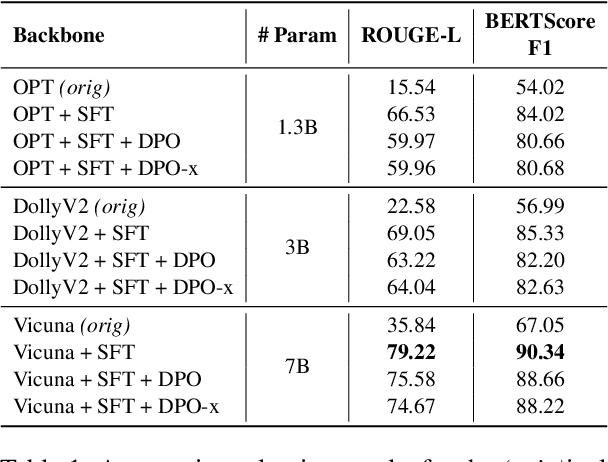
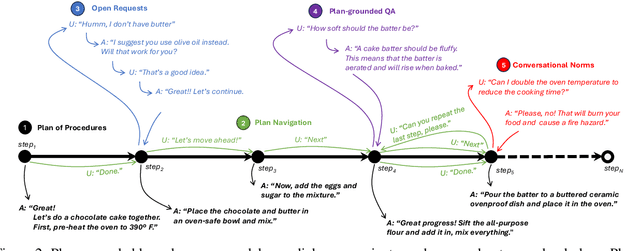

Training Large Language Models (LLMs) to follow user instructions has been shown to supply the LLM with ample capacity to converse fluently while being aligned with humans. Yet, it is not completely clear how an LLM can lead a plan-grounded conversation in mixed-initiative settings where instructions flow in both directions of the conversation, i.e. both the LLM and the user provide instructions to one another. In this paper, we tackle a dual goal mixed-initiative conversational setting where the LLM not only grounds the conversation on an arbitrary plan but also seeks to satisfy both a procedural plan and user instructions. The LLM is then responsible for guiding the user through the plan and, at the same time, adapting to new circumstances, answering questions, and activating safety guardrails when needed. We propose a novel LLM that grounds the dialogue on a procedural plan, can take the dialogue initiative, and enforces guardrails on the system's behavior, while also improving the LLM's responses to unexpected user behavior. Experiments in controlled settings and with real users show that the best-performing model, which we call PlanLLM, achieves a 2.1x improvement over a strong baseline. Moreover, experiments also show good generalization to unseen domains.