 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Graph Meta-Network for Learning on Kolmogorov-Arnold Networks
Feb 18, 2026Weight-space models learn directly from the parameters of neural networks, enabling tasks such as predicting their accuracy on new datasets. Naive methods -- like applying MLPs to flattened parameters -- perform poorly, making the design of better weight-space architectures a central challenge. While prior work leveraged permutation symmetries in standard networks to guide such designs, no analogous analysis or tailored architecture yet exists for Kolmogorov-Arnold Networks (KANs). In this work, we show that KANs share the same permutation symmetries as MLPs, and propose the KAN-graph, a graph representation of their computation. Building on this, we develop WS-KAN, the first weight-space architecture that learns on KANs, which naturally accounts for their symmetry. We analyze WS-KAN's expressive power, showing it can replicate an input KAN's forward pass - a standard approach for assessing expressiveness in weight-space architectures. We construct a comprehensive ``zoo'' of trained KANs spanning diverse tasks, which we use as benchmarks to empirically evaluate WS-KAN. Across all tasks, WS-KAN consistently outperforms structure-agnostic baselines, often by a substantial margin. Our code is available at https://github.com/BarSGuy/KAN-Graph-Metanetwork.
Learning on LLM Output Signatures for gray-box LLM Behavior Analysis
Mar 18, 2025Large Language Models (LLMs) have achieved widespread adoption, yet our understanding of their behavior remains limited, particularly in detecting data contamination and hallucinations. While recently proposed probing techniques provide insights through activation analysis, they require "white-box" access to model internals, often unavailable. Current "gray-box" approaches typically analyze only the probability of the actual tokens in the sequence with simple task-specific heuristics. Importantly, these methods overlook the rich information contained in the full token distribution at each processing step. To address these limitations, we propose that gray-box analysis should leverage the complete observable output of LLMs, consisting of both the previously used token probabilities as well as the complete token distribution sequences - a unified data type we term LOS (LLM Output Signature). To this end, we develop a transformer-based approach to process LOS that theoretically guarantees approximation of existing techniques while enabling more nuanced analysis. Our approach achieves superior performance on hallucination and data contamination detection in gray-box settings, significantly outperforming existing baselines. Furthermore, it demonstrates strong transfer capabilities across datasets and LLMs, suggesting that LOS captures fundamental patterns in LLM behavior. Our code is available at: https://github.com/BarSGuy/LLM-Output-Signatures-Network.
Balancing Efficiency and Expressiveness: Subgraph GNNs with Walk-Based Centrality
Jan 06, 2025



We propose an expressive and efficient approach that combines the strengths of two prominent extensions of Graph Neural Networks (GNNs): Subgraph GNNs and Structural Encodings (SEs). Our approach leverages walk-based centrality measures, both as a powerful form of SE and also as a subgraph selection strategy for Subgraph GNNs. By drawing a connection to perturbation analysis, we highlight the effectiveness of centrality-based sampling, and show it significantly reduces the computational burden associated with Subgraph GNNs. Further, we combine our efficient Subgraph GNN with SEs derived from the calculated centrality and demonstrate this hybrid approach, dubbed HyMN, gains in discriminative power. HyMN effectively addresses the expressiveness limitations of Message Passing Neural Networks (MPNNs) while mitigating the computational costs of Subgraph GNNs. Through a series of experiments on synthetic and real-world tasks, we show it outperforms other subgraph sampling approaches while being competitive with full-bag Subgraph GNNs and other state-of-the-art approaches with a notably reduced runtime.
Topological Blind Spots: Understanding and Extending Topological Deep Learning Through the Lens of Expressivity
Aug 10, 2024Topological deep learning (TDL) facilitates learning from data represented by topological structures. The primary model utilized in this setting is higher-order message-passing (HOMP), which extends traditional graph message-passing neural networks (MPNN) to diverse topological domains. Given the significant expressivity limitations of MPNNs, our paper aims to explore both the strengths and weaknesses of HOMP's expressive power and subsequently design novel architectures to address these limitations. We approach this from several perspectives: First, we demonstrate HOMP's inability to distinguish between topological objects based on fundamental topological and metric properties such as diameter, orientability, planarity, and homology. Second, we show HOMP's limitations in fully leveraging the topological structure of objects constructed using common lifting and pooling operators on graphs. Finally, we compare HOMP's expressive power to hypergraph networks, which are the most extensively studied TDL methods. We then develop two new classes of TDL models: multi-cellular networks (MCN) and scalable multi-cellular networks (SMCN). These models draw inspiration from expressive graph architectures. While MCN can reach full expressivity but is highly unscalable, SMCN offers a more scalable alternative that still mitigates many of HOMP's expressivity limitations. Finally, we construct a synthetic dataset, where TDL models are tasked with separating pairs of topological objects based on basic topological properties. We demonstrate that while HOMP is unable to distinguish between any of the pairs in the dataset, SMCN successfully distinguishes all pairs, empirically validating our theoretical findings. Our work opens a new design space and new opportunities for TDL, paving the way for more expressive and versatile models.
A Flexible, Equivariant Framework for Subgraph GNNs via Graph Products and Graph Coarsening
Jun 13, 2024



Subgraph Graph Neural Networks (Subgraph GNNs) enhance the expressivity of message-passing GNNs by representing graphs as sets of subgraphs. They have shown impressive performance on several tasks, but their complexity limits applications to larger graphs. Previous approaches suggested processing only subsets of subgraphs, selected either randomly or via learnable sampling. However, they make suboptimal subgraph selections or can only cope with very small subset sizes, inevitably incurring performance degradation. This paper introduces a new Subgraph GNNs framework to address these issues. We employ a graph coarsening function to cluster nodes into super-nodes with induced connectivity. The product between the coarsened and the original graph reveals an implicit structure whereby subgraphs are associated with specific sets of nodes. By running generalized message-passing on such graph product, our method effectively implements an efficient, yet powerful Subgraph GNN. Controlling the coarsening function enables meaningful selection of any number of subgraphs while, contrary to previous methods, being fully compatible with standard training techniques. Notably, we discover that the resulting node feature tensor exhibits new, unexplored permutation symmetries. We leverage this structure, characterize the associated linear equivariant layers and incorporate them into the layers of our Subgraph GNN architecture. Extensive experiments on multiple graph learning benchmarks demonstrate that our method is significantly more flexible than previous approaches, as it can seamlessly handle any number of subgraphs, while consistently outperforming baseline approaches.
Subgraphormer: Unifying Subgraph GNNs and Graph Transformers via Graph Products
Feb 13, 2024



In the realm of Graph Neural Networks (GNNs), two exciting research directions have recently emerged: Subgraph GNNs and Graph Transformers. In this paper, we propose an architecture that integrates both approaches, dubbed Subgraphormer, which combines the enhanced expressive power, message-passing mechanisms, and aggregation schemes from Subgraph GNNs with attention and positional encodings, arguably the most important components in Graph Transformers. Our method is based on an intriguing new connection we reveal between Subgraph GNNs and product graphs, suggesting that Subgraph GNNs can be formulated as Message Passing Neural Networks (MPNNs) operating on a product of the graph with itself. We use this formulation to design our architecture: first, we devise an attention mechanism based on the connectivity of the product graph. Following this, we propose a novel and efficient positional encoding scheme for Subgraph GNNs, which we derive as a positional encoding for the product graph. Our experimental results demonstrate significant performance improvements over both Subgraph GNNs and Graph Transformers on a wide range of datasets.
Weakly-supervised Representation Learning for Video Alignment and Analysis
Feb 08, 2023Many tasks in video analysis and understanding boil down to the need for frame-based feature learning, aiming to encapsulate the relevant visual content so as to enable simpler and easier subsequent processing. While supervised strategies for this learning task can be envisioned, self and weakly-supervised alternatives are preferred due to the difficulties in getting labeled data. This paper introduces LRProp -- a novel weakly-supervised representation learning approach, with an emphasis on the application of temporal alignment between pairs of videos of the same action category. The proposed approach uses a transformer encoder for extracting frame-level features, and employs the DTW algorithm within the training iterations in order to identify the alignment path between video pairs. Through a process referred to as ``pair-wise position propagation'', the probability distributions of these correspondences per location are matched with the similarity of the frame-level features via KL-divergence minimization. The proposed algorithm uses also a regularized SoftDTW loss for better tuning the learned features. Our novel representation learning paradigm consistently outperforms the state of the art on temporal alignment tasks, establishing a new performance bar over several downstream video analysis applications.
TransBoost: Improving the Best ImageNet Performance using Deep Transduction
May 27, 2022
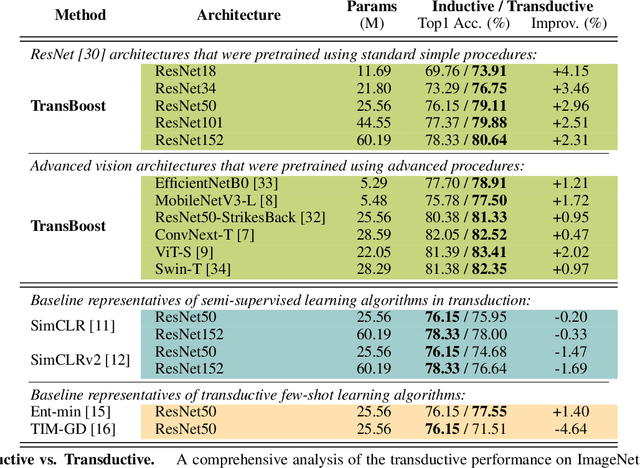
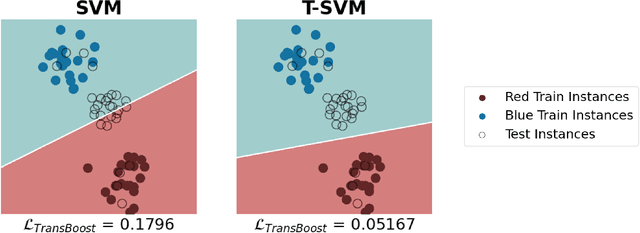

This paper deals with deep transductive learning, and proposes TransBoost as a procedure for fine-tuning any deep neural model to improve its performance on any (unlabeled) test set provided at training time. TransBoost is inspired by a large margin principle and is efficient and simple to use. The ImageNet classification performance is consistently and significantly improved with TransBoost on many architectures such as ResNets, MobileNetV3-L, EfficientNetB0, ViT-S, and ConvNext-T. Additionally we show that TransBoost is effective on a wide variety of image classification datasets.