 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMineTheGap: Automatic Mining of Biases in Text-to-Image Models
Dec 15, 2025Text-to-Image (TTI) models generate images based on text prompts, which often leave certain aspects of the desired image ambiguous. When faced with these ambiguities, TTI models have been shown to exhibit biases in their interpretations. These biases can have societal impacts, e.g., when showing only a certain race for a stated occupation. They can also affect user experience when creating redundancy within a set of generated images instead of spanning diverse possibilities. Here, we introduce MineTheGap - a method for automatically mining prompts that cause a TTI model to generate biased outputs. Our method goes beyond merely detecting bias for a given prompt. Rather, it leverages a genetic algorithm to iteratively refine a pool of prompts, seeking for those that expose biases. This optimization process is driven by a novel bias score, which ranks biases according to their severity, as we validate on a dataset with known biases. For a given prompt, this score is obtained by comparing the distribution of generated images to the distribution of LLM-generated texts that constitute variations on the prompt. Code and examples are available on the project's webpage.
Splatent: Splatting Diffusion Latents for Novel View Synthesis
Dec 10, 2025Radiance field representations have recently been explored in the latent space of VAEs that are commonly used by diffusion models. This direction offers efficient rendering and seamless integration with diffusion-based pipelines. However, these methods face a fundamental limitation: The VAE latent space lacks multi-view consistency, leading to blurred textures and missing details during 3D reconstruction. Existing approaches attempt to address this by fine-tuning the VAE, at the cost of reconstruction quality, or by relying on pre-trained diffusion models to recover fine-grained details, at the risk of some hallucinations. We present Splatent, a diffusion-based enhancement framework designed to operate on top of 3D Gaussian Splatting (3DGS) in the latent space of VAEs. Our key insight departs from the conventional 3D-centric view: rather than reconstructing fine-grained details in 3D space, we recover them in 2D from input views through multi-view attention mechanisms. This approach preserves the reconstruction quality of pretrained VAEs while achieving faithful detail recovery. Evaluated across multiple benchmarks, Splatent establishes a new state-of-the-art for VAE latent radiance field reconstruction. We further demonstrate that integrating our method with existing feed-forward frameworks, consistently improves detail preservation, opening new possibilities for high-quality sparse-view 3D reconstruction.
FlowEdit: Inversion-Free Text-Based Editing Using Pre-Trained Flow Models
Dec 11, 2024



Editing real images using a pre-trained text-to-image (T2I) diffusion/flow model often involves inverting the image into its corresponding noise map. However, inversion by itself is typically insufficient for obtaining satisfactory results, and therefore many methods additionally intervene in the sampling process. Such methods achieve improved results but are not seamlessly transferable between model architectures. Here, we introduce FlowEdit, a text-based editing method for pre-trained T2I flow models, which is inversion-free, optimization-free and model agnostic. Our method constructs an ODE that directly maps between the source and target distributions (corresponding to the source and target text prompts) and achieves a lower transport cost than the inversion approach. This leads to state-of-the-art results, as we illustrate with Stable Diffusion 3 and FLUX. Code and examples are available on the project's webpage.
Slicedit: Zero-Shot Video Editing With Text-to-Image Diffusion Models Using Spatio-Temporal Slices
May 20, 2024Text-to-image (T2I) diffusion models achieve state-of-the-art results in image synthesis and editing. However, leveraging such pretrained models for video editing is considered a major challenge. Many existing works attempt to enforce temporal consistency in the edited video through explicit correspondence mechanisms, either in pixel space or between deep features. These methods, however, struggle with strong nonrigid motion. In this paper, we introduce a fundamentally different approach, which is based on the observation that spatiotemporal slices of natural videos exhibit similar characteristics to natural images. Thus, the same T2I diffusion model that is normally used only as a prior on video frames, can also serve as a strong prior for enhancing temporal consistency by applying it on spatiotemporal slices. Based on this observation, we present Slicedit, a method for text-based video editing that utilizes a pretrained T2I diffusion model to process both spatial and spatiotemporal slices. Our method generates videos that retain the structure and motion of the original video while adhering to the target text. Through extensive experiments, we demonstrate Slicedit's ability to edit a wide range of real-world videos, confirming its clear advantages compared to existing competing methods. Webpage: https://matankleiner.github.io/slicedit/
An Edit Friendly DDPM Noise Space: Inversion and Manipulations
Apr 14, 2023



Denoising diffusion probabilistic models (DDPMs) employ a sequence of white Gaussian noise samples to generate an image. In analogy with GANs, those noise maps could be considered as the latent code associated with the generated image. However, this native noise space does not possess a convenient structure, and is thus challenging to work with in editing tasks. Here, we propose an alternative latent noise space for DDPM that enables a wide range of editing operations via simple means, and present an inversion method for extracting these edit-friendly noise maps for any given image (real or synthetically generated). As opposed to the native DDPM noise space, the edit-friendly noise maps do not have a standard normal distribution and are not statistically independent across timesteps. However, they allow perfect reconstruction of any desired image, and simple transformations on them translate into meaningful manipulations of the output image (e.g., shifting, color edits). Moreover, in text-conditional models, fixing those noise maps while changing the text prompt, modifies semantics while retaining structure. We illustrate how this property enables text-based editing of real images via the diverse DDPM sampling scheme (in contrast to the popular non-diverse DDIM inversion). We also show how it can be used within existing diffusion-based editing methods to improve their quality and diversity.
Discovering Interpretable Directions in the Semantic Latent Space of Diffusion Models
Mar 20, 2023



Denoising Diffusion Models (DDMs) have emerged as a strong competitor to Generative Adversarial Networks (GANs). However, despite their widespread use in image synthesis and editing applications, their latent space is still not as well understood. Recently, a semantic latent space for DDMs, coined `$h$-space', was shown to facilitate semantic image editing in a way reminiscent of GANs. The $h$-space is comprised of the bottleneck activations in the DDM's denoiser across all timesteps of the diffusion process. In this paper, we explore the properties of h-space and propose several novel methods for finding meaningful semantic directions within it. We start by studying unsupervised methods for revealing interpretable semantic directions in pretrained DDMs. Specifically, we show that global latent directions emerge as the principal components in the latent space. Additionally, we provide a novel method for discovering image-specific semantic directions by spectral analysis of the Jacobian of the denoiser w.r.t. the latent code. Next, we extend the analysis by finding directions in a supervised fashion in unconditional DDMs. We demonstrate how such directions can be found by relying on either a labeled data set of real images or by annotating generated samples with a domain-specific attribute classifier. We further show how to semantically disentangle the found direction by simple linear projection. Our approaches are applicable without requiring any architectural modifications, text-based guidance, CLIP-based optimization, or model fine-tuning.
Single Image Object Counting and Localizing using Active-Learning
Nov 16, 2021
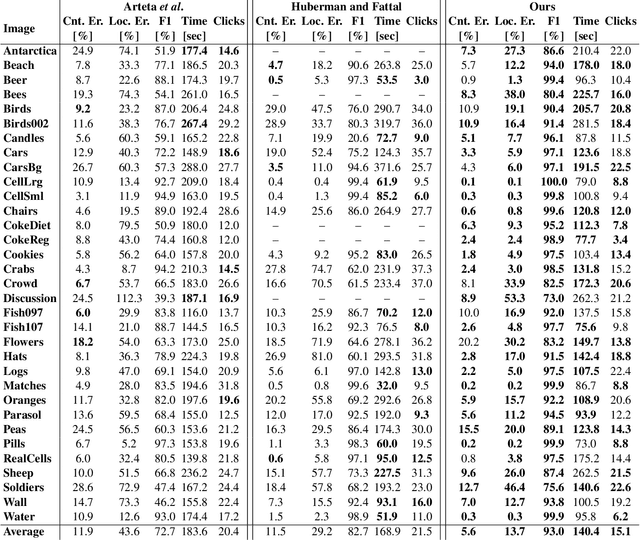


The need to count and localize repeating objects in an image arises in different scenarios, such as biological microscopy studies, production lines inspection, and surveillance recordings analysis. The use of supervised Convoutional Neural Networks (CNNs) achieves accurate object detection when trained over large class-specific datasets. The labeling effort in this approach does not pay-off when the counting is required over few images of a unique object class. We present a new method for counting and localizing repeating objects in single-image scenarios, assuming no pre-trained classifier is available. Our method trains a CNN over a small set of labels carefully collected from the input image in few active-learning iterations. At each iteration, the latent space of the network is analyzed to extract a minimal number of user-queries that strives to both sample the in-class manifold as thoroughly as possible as well as avoid redundant labels. Compared with existing user-assisted counting methods, our active-learning iterations achieve state-of-the-art performance in terms of counting and localizing accuracy, number of user mouse clicks, and running-time. This evaluation was performed through a large user study over a wide range of image classes with diverse conditions of illumination and occlusions.
Unpaired Learning for High Dynamic Range Image Tone Mapping
Oct 30, 2021


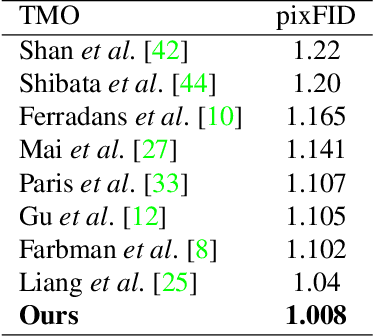
High dynamic range (HDR) photography is becoming increasingly popular and available by DSLR and mobile-phone cameras. While deep neural networks (DNN) have greatly impacted other domains of image manipulation, their use for HDR tone-mapping is limited due to the lack of a definite notion of ground-truth solution, which is needed for producing training data. In this paper we describe a new tone-mapping approach guided by the distinct goal of producing low dynamic range (LDR) renditions that best reproduce the visual characteristics of native LDR images. This goal enables the use of an unpaired adversarial training based on unrelated sets of HDR and LDR images, both of which are widely available and easy to acquire. In order to achieve an effective training under this minimal requirements, we introduce the following new steps and components: (i) a range-normalizing pre-process which estimates and applies a different level of curve-based compression, (ii) a loss that preserves the input content while allowing the network to achieve its goal, and (iii) the use of a more concise discriminator network, designed to promote the reproduction of low-level attributes native LDR possess. Evaluation of the resulting network demonstrates its ability to produce photo-realistic artifact-free tone-mapped images, and state-of-the-art performance on different image fidelity indices and visual distances.