 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Interpretable Directions in the Semantic Latent Space of Diffusion Models
Mar 20, 2023



Denoising Diffusion Models (DDMs) have emerged as a strong competitor to Generative Adversarial Networks (GANs). However, despite their widespread use in image synthesis and editing applications, their latent space is still not as well understood. Recently, a semantic latent space for DDMs, coined `$h$-space', was shown to facilitate semantic image editing in a way reminiscent of GANs. The $h$-space is comprised of the bottleneck activations in the DDM's denoiser across all timesteps of the diffusion process. In this paper, we explore the properties of h-space and propose several novel methods for finding meaningful semantic directions within it. We start by studying unsupervised methods for revealing interpretable semantic directions in pretrained DDMs. Specifically, we show that global latent directions emerge as the principal components in the latent space. Additionally, we provide a novel method for discovering image-specific semantic directions by spectral analysis of the Jacobian of the denoiser w.r.t. the latent code. Next, we extend the analysis by finding directions in a supervised fashion in unconditional DDMs. We demonstrate how such directions can be found by relying on either a labeled data set of real images or by annotating generated samples with a domain-specific attribute classifier. We further show how to semantically disentangle the found direction by simple linear projection. Our approaches are applicable without requiring any architectural modifications, text-based guidance, CLIP-based optimization, or model fine-tuning.
Controllable GAN Synthesis Using Non-Rigid Structure-from-Motion
Nov 14, 2022



In this paper, we present an approach for combining non-rigid structure-from-motion (NRSfM) with deep generative models,and propose an efficient framework for discovering trajectories in the latent space of 2D GANs corresponding to changes in 3D geometry. Our approach uses recent advances in NRSfM and enables editing of the camera and non-rigid shape information associated with the latent codes without needing to retrain the generator. This formulation provides an implicit dense 3D reconstruction as it enables the image synthesis of novel shapes from arbitrary view angles and non-rigid structure. The method is built upon a sparse backbone, where a neural regressor is first trained to regress parameters describing the cameras and sparse non-rigid structure directly from the latent codes. The latent trajectories associated with changes in the camera and structure parameters are then identified by estimating the local inverse of the regressor in the neighborhood of a given latent code. The experiments show that our approach provides a versatile, systematic way to model, analyze, and edit the geometry and non-rigid structures of faces.
Tensor-based Emotion Editing in the StyleGAN Latent Space
May 12, 2022



In this paper, we use a tensor model based on the Higher-Order Singular Value Decomposition (HOSVD) to discover semantic directions in Generative Adversarial Networks. This is achieved by first embedding a structured facial expression database into the latent space using the e4e encoder. Specifically, we discover directions in latent space corresponding to the six prototypical emotions: anger, disgust, fear, happiness, sadness, and surprise, as well as a direction for yaw rotation. These latent space directions are employed to change the expression or yaw rotation of real face images. We compare our found directions to similar directions found by two other methods. The results show that the visual quality of the resultant edits are on par with State-of-the-Art. It can also be concluded that the tensor-based model is well suited for emotion and yaw editing, i.e., that the emotion or yaw rotation of a novel face image can be robustly changed without a significant effect on identity or other attributes in the images.
Tensor-based Subspace Factorization for StyleGAN
Nov 08, 2021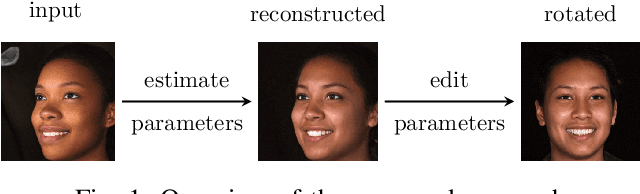
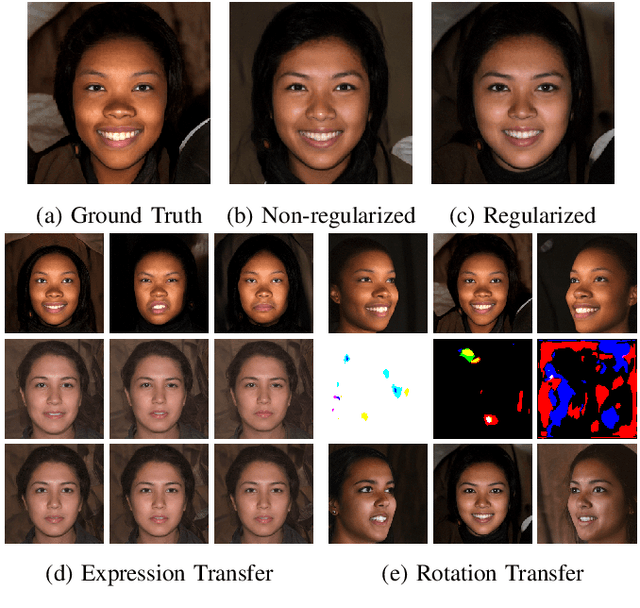

In this paper, we propose $\tau$GAN a tensor-based method for modeling the latent space of generative models. The objective is to identify semantic directions in latent space. To this end, we propose to fit a multilinear tensor model on a structured facial expression database, which is initially embedded into latent space. We validate our approach on StyleGAN trained on FFHQ using BU-3DFE as a structured facial expression database. We show how the parameters of the multilinear tensor model can be approximated by Alternating Least Squares. Further, we introduce a tacked style-separated tensor model, defined as an ensemble of style-specific models to integrate our approach with the extended latent space of StyleGAN. We show that taking the individual styles of the extended latent space into account leads to higher model flexibility and lower reconstruction error. Finally, we do several experiments comparing our approach to former work on both GANs and multilinear models. Concretely, we analyze the expression subspace and find that the expression trajectories meet at an apathetic face that is consistent with earlier work. We also show that by changing the pose of a person, the generated image from our approach is closer to the ground truth than results from two competing approaches.
Discriminating Between Similar Nordic Languages
Dec 11, 2020
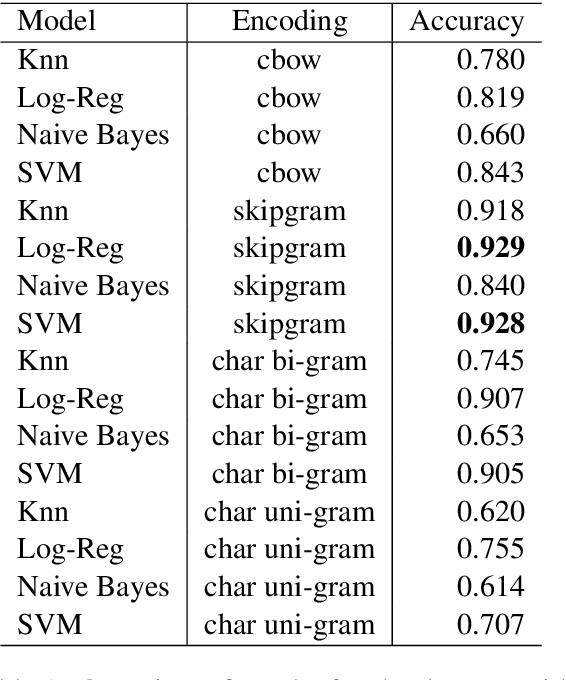


Automatic language identification is a challenging problem. Discriminating between closely related languages is especially difficult. This paper presents a machine learning approach for automatic language identification for the Nordic languages, which often suffer miscategorisation by existing state-of-the-art tools. Concretely we will focus on discrimination between six Nordic languages: Danish, Swedish, Norwegian (Nynorsk), Norwegian (Bokm{\aa}l), Faroese and Icelandic.