 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Hidden Gems in Model Repositories
Jan 29, 2026Public repositories host millions of fine-tuned models, yet community usage remains disproportionately concentrated on a small number of foundation checkpoints. We investigate whether this concentration reflects efficient market selection or if superior models are systematically overlooked. Through an extensive evaluation of over 2,000 models, we show the prevalence of "hidden gems", unpopular fine-tunes that significantly outperform their popular counterparts. Notably, within the Llama-3.1-8B family, we find rarely downloaded checkpoints that improve math performance from 83.2% to 96.0% without increasing inference costs. However, discovering these models through exhaustive evaluation of every uploaded model is computationally infeasible. We therefore formulate model discovery as a Multi-Armed Bandit problem and accelerate the Sequential Halving search algorithm by using shared query sets and aggressive elimination schedules. Our method retrieves top models with as few as 50 queries per candidate, accelerating discovery by over 50x.
Charting and Navigating Hugging Face's Model Atlas
Mar 13, 2025



As there are now millions of publicly available neural networks, searching and analyzing large model repositories becomes increasingly important. Navigating so many models requires an atlas, but as most models are poorly documented charting such an atlas is challenging. To explore the hidden potential of model repositories, we chart a preliminary atlas representing the documented fraction of Hugging Face. It provides stunning visualizations of the model landscape and evolution. We demonstrate several applications of this atlas including predicting model attributes (e.g., accuracy), and analyzing trends in computer vision models. However, as the current atlas remains incomplete, we propose a method for charting undocumented regions. Specifically, we identify high-confidence structural priors based on dominant real-world model training practices. Leveraging these priors, our approach enables accurate mapping of previously undocumented areas of the atlas. We publicly release our datasets, code, and interactive atlas.
Can this Model Also Recognize Dogs? Zero-Shot Model Search from Weights
Feb 13, 2025



With the increasing numbers of publicly available models, there are probably pretrained, online models for most tasks users require. However, current model search methods are rudimentary, essentially a text-based search in the documentation, thus users cannot find the relevant models. This paper presents ProbeLog, a method for retrieving classification models that can recognize a target concept, such as "Dog", without access to model metadata or training data. Differently from previous probing methods, ProbeLog computes a descriptor for each output dimension (logit) of each model, by observing its responses on a fixed set of inputs (probes). Our method supports both logit-based retrieval ("find more logits like this") and zero-shot, text-based retrieval ("find all logits corresponding to dogs"). As probing-based representations require multiple costly feedforward passes through the model, we develop a method, based on collaborative filtering, that reduces the cost of encoding repositories by 3x. We demonstrate that ProbeLog achieves high retrieval accuracy, both in real-world and fine-grained search tasks and is scalable to full-size repositories.
Representing Model Weights with Language using Tree Experts
Oct 17, 2024



The increasing availability of public models begs the question: can we train neural networks that use other networks as input? This paper learns to represent models within a joint space that embeds both model weights and language. However, machine learning on model weights is challenging as model weights often exhibit significant variation unrelated to the models' semantic properties (nuisance variation). We identify a key property of real-world models: most public models belong to a small set of Model Trees, where all models within a tree are fine-tuned from a common ancestor (e.g., a foundation model). Importantly, we find that within each tree there is less nuisance variation between models. For example, while classifying models according to their training dataset generally requires complex architectures, in our case, even a linear classifier trained on a single layer is often effective. While effective, linear layers are computationally expensive as model weights are very high dimensional. To address this, we introduce Probing Experts (ProbeX), a theoretically motivated, lightweight probing method. Notably, ProbeX is the first probing method designed to learn from the weights of just a single model layer. We also construct and release a dataset that simulates the structure of public model repositories. Our results show that ProbeX can effectively map the weights of large models into a shared weight-language embedding space. Furthermore, we demonstrate the impressive generalization of our method, achieving zero-shot model classification and retrieval.
Deep Linear Probe Generators for Weight Space Learning
Oct 14, 2024



Weight space learning aims to extract information about a neural network, such as its training dataset or generalization error. Recent approaches learn directly from model weights, but this presents many challenges as weights are high-dimensional and include permutation symmetries between neurons. An alternative approach, Probing, represents a model by passing a set of learned inputs (probes) through the model, and training a predictor on top of the corresponding outputs. Although probing is typically not used as a stand alone approach, our preliminary experiment found that a vanilla probing baseline worked surprisingly well. However, we discover that current probe learning strategies are ineffective. We therefore propose Deep Linear Probe Generators (ProbeGen), a simple and effective modification to probing approaches. ProbeGen adds a shared generator module with a deep linear architecture, providing an inductive bias towards structured probes thus reducing overfitting. While simple, ProbeGen performs significantly better than the state-of-the-art and is very efficient, requiring between 30 to 1000 times fewer FLOPs than other top approaches.
Dataset Size Recovery from LoRA Weights
Jun 27, 2024Model inversion and membership inference attacks aim to reconstruct and verify the data which a model was trained on. However, they are not guaranteed to find all training samples as they do not know the size of the training set. In this paper, we introduce a new task: dataset size recovery, that aims to determine the number of samples used to train a model, directly from its weights. We then propose DSiRe, a method for recovering the number of images used to fine-tune a model, in the common case where fine-tuning uses LoRA. We discover that both the norm and the spectrum of the LoRA matrices are closely linked to the fine-tuning dataset size; we leverage this finding to propose a simple yet effective prediction algorithm. To evaluate dataset size recovery of LoRA weights, we develop and release a new benchmark, LoRA-WiSE, consisting of over 25000 weight snapshots from more than 2000 diverse LoRA fine-tuned models. Our best classifier can predict the number of fine-tuning images with a mean absolute error of 0.36 images, establishing the feasibility of this attack.
Recovering the Pre-Fine-Tuning Weights of Generative Models
Feb 15, 2024



The dominant paradigm in generative modeling consists of two steps: i) pre-training on a large-scale but unsafe dataset, ii) aligning the pre-trained model with human values via fine-tuning. This practice is considered safe, as no current method can recover the unsafe, pre-fine-tuning model weights. In this paper, we demonstrate that this assumption is often false. Concretely, we present Spectral DeTuning, a method that can recover the weights of the pre-fine-tuning model using a few low-rank (LoRA) fine-tuned models. In contrast to previous attacks that attempt to recover pre-fine-tuning capabilities, our method aims to recover the exact pre-fine-tuning weights. Our approach exploits this new vulnerability against large-scale models such as a personalized Stable Diffusion and an aligned Mistral.
Improving Zero-Shot Models with Label Distribution Priors
Dec 01, 2022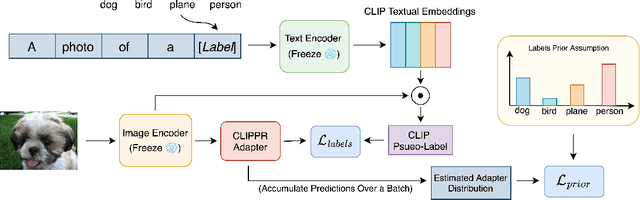

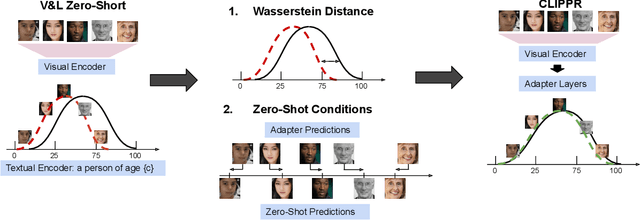

Labeling large image datasets with attributes such as facial age or object type is tedious and sometimes infeasible. Supervised machine learning methods provide a highly accurate solution, but require manual labels which are often unavailable. Zero-shot models (e.g., CLIP) do not require manual labels but are not as accurate as supervised ones, particularly when the attribute is numeric. We propose a new approach, CLIPPR (CLIP with Priors), which adapts zero-shot models for regression and classification on unlabelled datasets. Our method does not use any annotated images. Instead, we assume a prior over the label distribution in the dataset. We then train an adapter network on top of CLIP under two competing objectives: i) minimal change of predictions from the original CLIP model ii) minimal distance between predicted and prior distribution of labels. Additionally, we present a novel approach for selecting prompts for Vision & Language models using a distributional prior. Our method is effective and presents a significant improvement over the original model. We demonstrate an improvement of 28% in mean absolute error on the UTK age regression task. We also present promising results for classification benchmarks, improving the classification accuracy on the ImageNet dataset by 2.83%, without using any labels.
Red PANDA: Disambiguating Anomaly Detection by Removing Nuisance Factors
Jul 07, 2022
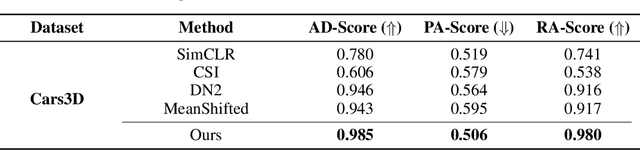
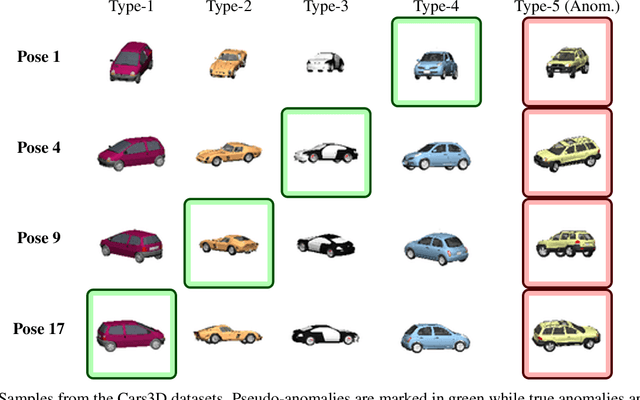
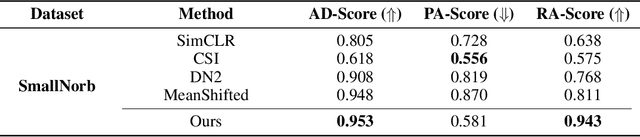
Anomaly detection methods strive to discover patterns that differ from the norm in a semantic way. This goal is ambiguous as a data point differing from the norm by an attribute e.g., age, race or gender, may be considered anomalous by some operators while others may consider this attribute irrelevant. Breaking from previous research, we present a new anomaly detection method that allows operators to exclude an attribute from being considered as relevant for anomaly detection. Our approach then learns representations which do not contain information over the nuisance attributes. Anomaly scoring is performed using a density-based approach. Importantly, our approach does not require specifying the attributes that are relevant for detecting anomalies, which is typically impossible in anomaly detection, but only attributes to ignore. An empirical investigation is presented verifying the effectiveness of our approach.
A Contrastive Objective for Learning Disentangled Representations
Mar 21, 2022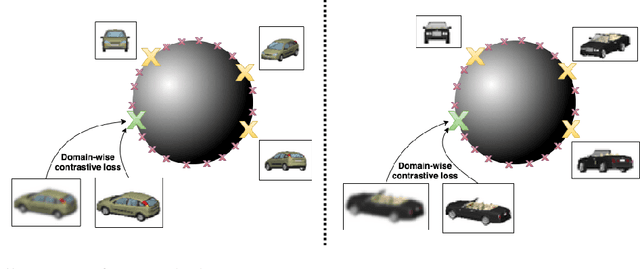
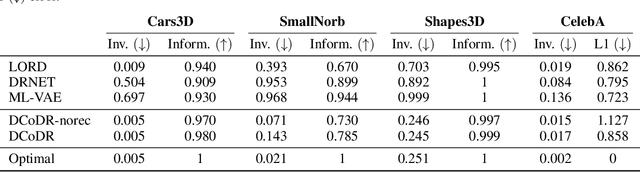

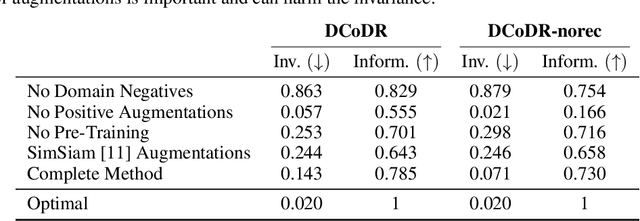
Learning representations of images that are invariant to sensitive or unwanted attributes is important for many tasks including bias removal and cross domain retrieval. Here, our objective is to learn representations that are invariant to the domain (sensitive attribute) for which labels are provided, while being informative over all other image attributes, which are unlabeled. We present a new approach, proposing a new domain-wise contrastive objective for ensuring invariant representations. This objective crucially restricts negative image pairs to be drawn from the same domain, which enforces domain invariance whereas the standard contrastive objective does not. This domain-wise objective is insufficient on its own as it suffers from shortcut solutions resulting in feature suppression. We overcome this issue by a combination of a reconstruction constraint, image augmentations and initialization with pre-trained weights. Our analysis shows that the choice of augmentations is important, and that a misguided choice of augmentations can harm the invariance and informativeness objectives. In an extensive evaluation, our method convincingly outperforms the state-of-the-art in terms of representation invariance, representation informativeness, and training speed. Furthermore, we find that in some cases our method can achieve excellent results even without the reconstruction constraint, leading to a much faster and resource efficient training.