 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Contrastive Objective for Learning Disentangled Representations
Paper and Code
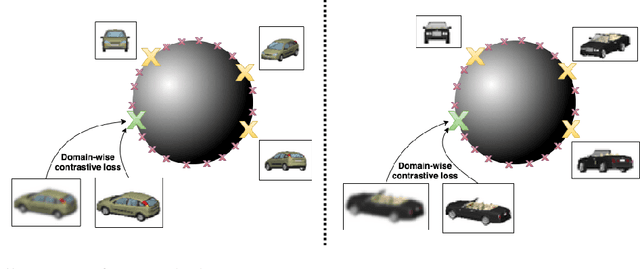
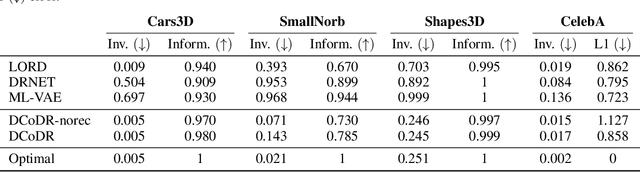

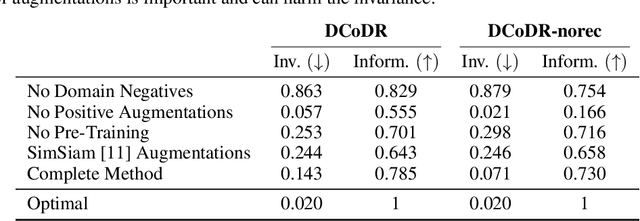
Learning representations of images that are invariant to sensitive or unwanted attributes is important for many tasks including bias removal and cross domain retrieval. Here, our objective is to learn representations that are invariant to the domain (sensitive attribute) for which labels are provided, while being informative over all other image attributes, which are unlabeled. We present a new approach, proposing a new domain-wise contrastive objective for ensuring invariant representations. This objective crucially restricts negative image pairs to be drawn from the same domain, which enforces domain invariance whereas the standard contrastive objective does not. This domain-wise objective is insufficient on its own as it suffers from shortcut solutions resulting in feature suppression. We overcome this issue by a combination of a reconstruction constraint, image augmentations and initialization with pre-trained weights. Our analysis shows that the choice of augmentations is important, and that a misguided choice of augmentations can harm the invariance and informativeness objectives. In an extensive evaluation, our method convincingly outperforms the state-of-the-art in terms of representation invariance, representation informativeness, and training speed. Furthermore, we find that in some cases our method can achieve excellent results even without the reconstruction constraint, leading to a much faster and resource efficient training.