 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Zero-Shot Models with Label Distribution Priors
Paper and Code
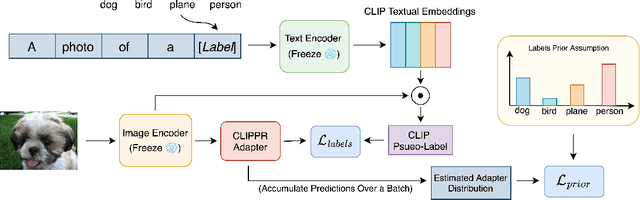

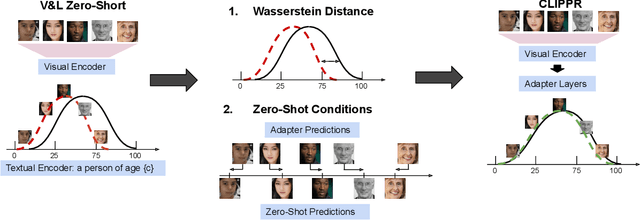

Labeling large image datasets with attributes such as facial age or object type is tedious and sometimes infeasible. Supervised machine learning methods provide a highly accurate solution, but require manual labels which are often unavailable. Zero-shot models (e.g., CLIP) do not require manual labels but are not as accurate as supervised ones, particularly when the attribute is numeric. We propose a new approach, CLIPPR (CLIP with Priors), which adapts zero-shot models for regression and classification on unlabelled datasets. Our method does not use any annotated images. Instead, we assume a prior over the label distribution in the dataset. We then train an adapter network on top of CLIP under two competing objectives: i) minimal change of predictions from the original CLIP model ii) minimal distance between predicted and prior distribution of labels. Additionally, we present a novel approach for selecting prompts for Vision & Language models using a distributional prior. Our method is effective and presents a significant improvement over the original model. We demonstrate an improvement of 28% in mean absolute error on the UTK age regression task. We also present promising results for classification benchmarks, improving the classification accuracy on the ImageNet dataset by 2.83%, without using any labels.