 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-Q: Generating Pseudo Language Queries for Visual Grounding
Paper and Code
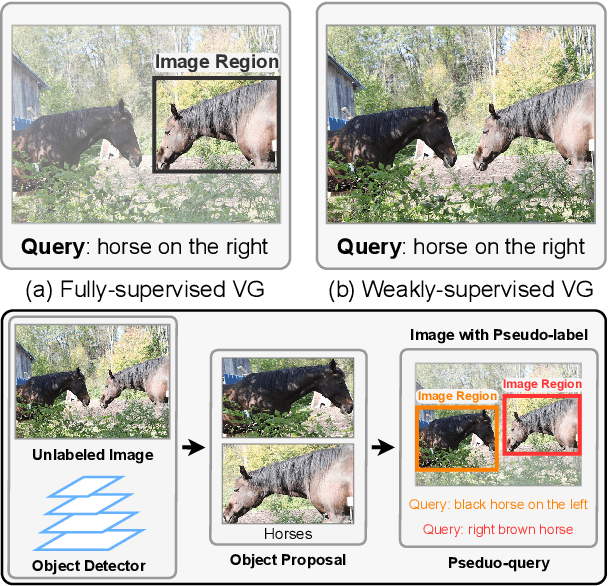
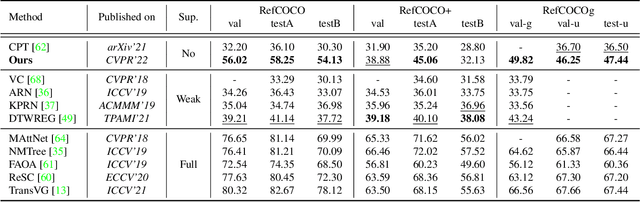
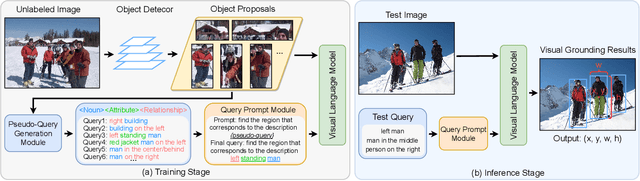
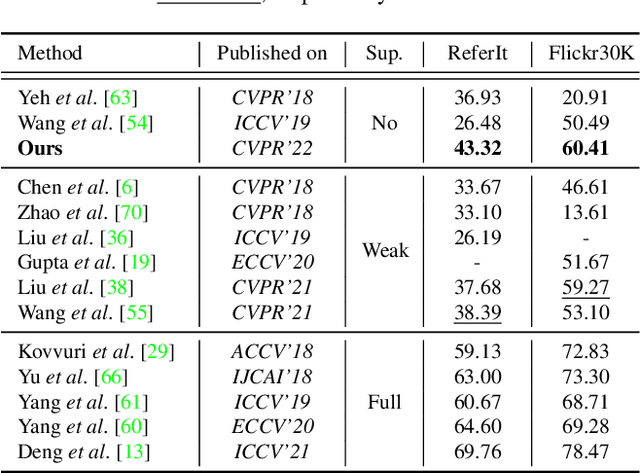
Visual grounding, i.e., localizing objects in images according to natural language queries, is an important topic in visual language understanding. The most effective approaches for this task are based on deep learning, which generally require expensive manually labeled image-query or patch-query pairs. To eliminate the heavy dependence on human annotations, we present a novel method, named Pseudo-Q, to automatically generate pseudo language queries for supervised training. Our method leverages an off-the-shelf object detector to identify visual objects from unlabeled images, and then language queries for these objects are obtained in an unsupervised fashion with a pseudo-query generation module. Then, we design a task-related query prompt module to specifically tailor generated pseudo language queries for visual grounding tasks. Further, in order to fully capture the contextual relationships between images and language queries, we develop a visual-language model equipped with multi-level cross-modality attention mechanism. Extensive experimental results demonstrate that our method has two notable benefits: (1) it can reduce human annotation costs significantly, e.g., 31% on RefCOCO without degrading original model's performance under the fully supervised setting, and (2) without bells and whistles, it achieves superior or comparable performance compared to state-of-the-art weakly-supervised visual grounding methods on all the five datasets we have experimented. Code is available at https://github.com/LeapLabTHU/Pseudo-Q.