 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeuLayout: Unified Room Layout Estimation for Perspective and Panoramic Images
Mar 27, 2025We present uLayout, a unified model for estimating room layout geometries from both perspective and panoramic images, whereas traditional solutions require different model designs for each image type. The key idea of our solution is to unify both domains into the equirectangular projection, particularly, allocating perspective images into the most suitable latitude coordinate to effectively exploit both domains seamlessly. To address the Field-of-View (FoV) difference between the input domains, we design uLayout with a shared feature extractor with an extra 1D-Convolution layer to condition each domain input differently. This conditioning allows us to efficiently formulate a column-wise feature regression problem regardless of the FoV input. This simple yet effective approach achieves competitive performance with current state-of-the-art solutions and shows for the first time a single end-to-end model for both domains. Extensive experiments in the real-world datasets, LSUN, Matterport3D, PanoContext, and Stanford 2D-3D evidence the contribution of our approach. Code is available at https://github.com/JonathanLee112/uLayout.
CTRL-D: Controllable Dynamic 3D Scene Editing with Personalized 2D Diffusion
Dec 02, 2024
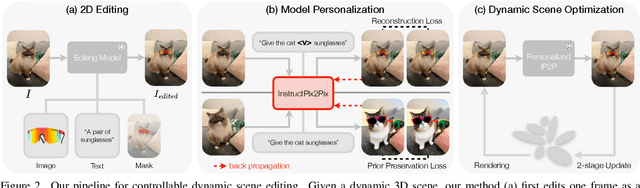


Recent advances in 3D representations, such as Neural Radiance Fields and 3D Gaussian Splatting, have greatly improved realistic scene modeling and novel-view synthesis. However, achieving controllable and consistent editing in dynamic 3D scenes remains a significant challenge. Previous work is largely constrained by its editing backbones, resulting in inconsistent edits and limited controllability. In our work, we introduce a novel framework that first fine-tunes the InstructPix2Pix model, followed by a two-stage optimization of the scene based on deformable 3D Gaussians. Our fine-tuning enables the model to "learn" the editing ability from a single edited reference image, transforming the complex task of dynamic scene editing into a simple 2D image editing process. By directly learning editing regions and styles from the reference, our approach enables consistent and precise local edits without the need for tracking desired editing regions, effectively addressing key challenges in dynamic scene editing. Then, our two-stage optimization progressively edits the trained dynamic scene, using a designed edited image buffer to accelerate convergence and improve temporal consistency. Compared to state-of-the-art methods, our approach offers more flexible and controllable local scene editing, achieving high-quality and consistent results.
Self-training Room Layout Estimation via Geometry-aware Ray-casting
Jul 21, 2024



In this paper, we introduce a novel geometry-aware self-training framework for room layout estimation models on unseen scenes with unlabeled data. Our approach utilizes a ray-casting formulation to aggregate multiple estimates from different viewing positions, enabling the computation of reliable pseudo-labels for self-training. In particular, our ray-casting approach enforces multi-view consistency along all ray directions and prioritizes spatial proximity to the camera view for geometry reasoning. As a result, our geometry-aware pseudo-labels effectively handle complex room geometries and occluded walls without relying on assumptions such as Manhattan World or planar room walls. Evaluation on publicly available datasets, including synthetic and real-world scenarios, demonstrates significant improvements in current state-of-the-art layout models without using any human annotation.
iFusion: Inverting Diffusion for Pose-Free Reconstruction from Sparse Views
Dec 28, 2023We present iFusion, a novel 3D object reconstruction framework that requires only two views with unknown camera poses. While single-view reconstruction yields visually appealing results, it can deviate significantly from the actual object, especially on unseen sides. Additional views improve reconstruction fidelity but necessitate known camera poses. However, assuming the availability of pose may be unrealistic, and existing pose estimators fail in sparse view scenarios. To address this, we harness a pre-trained novel view synthesis diffusion model, which embeds implicit knowledge about the geometry and appearance of diverse objects. Our strategy unfolds in three steps: (1) We invert the diffusion model for camera pose estimation instead of synthesizing novel views. (2) The diffusion model is fine-tuned using provided views and estimated poses, turned into a novel view synthesizer tailored for the target object. (3) Leveraging registered views and the fine-tuned diffusion model, we reconstruct the 3D object. Experiments demonstrate strong performance in both pose estimation and novel view synthesis. Moreover, iFusion seamlessly integrates with various reconstruction methods and enhances them.
360-MLC: Multi-view Layout Consistency for Self-training and Hyper-parameter Tuning
Oct 24, 2022We present 360-MLC, a self-training method based on multi-view layout consistency for finetuning monocular room-layout models using unlabeled 360-images only. This can be valuable in practical scenarios where a pre-trained model needs to be adapted to a new data domain without using any ground truth annotations. Our simple yet effective assumption is that multiple layout estimations in the same scene must define a consistent geometry regardless of their camera positions. Based on this idea, we leverage a pre-trained model to project estimated layout boundaries from several camera views into the 3D world coordinate. Then, we re-project them back to the spherical coordinate and build a probability function, from which we sample the pseudo-labels for self-training. To handle unconfident pseudo-labels, we evaluate the variance in the re-projected boundaries as an uncertainty value to weight each pseudo-label in our loss function during training. In addition, since ground truth annotations are not available during training nor in testing, we leverage the entropy information in multiple layout estimations as a quantitative metric to measure the geometry consistency of the scene, allowing us to evaluate any layout estimator for hyper-parameter tuning, including model selection without ground truth annotations. Experimental results show that our solution achieves favorable performance against state-of-the-art methods when self-training from three publicly available source datasets to a unique, newly labeled dataset consisting of multi-view of the same scenes.
360-DFPE: Leveraging Monocular 360-Layouts for Direct Floor Plan Estimation
Dec 21, 2021

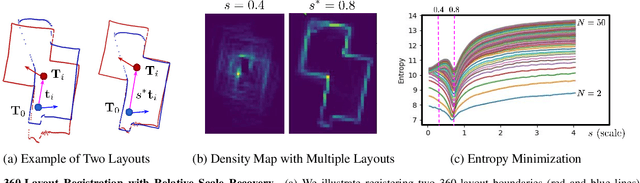
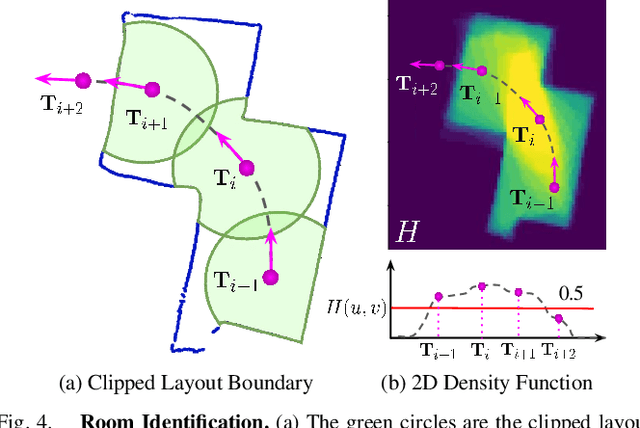
We present 360-DFPE, a sequential floor plan estimation method that directly takes 360-images as input without relying on active sensors or 3D information. Our approach leverages a loosely coupled integration between a monocular visual SLAM solution and a monocular 360-room layout approach, which estimate camera poses and layout geometries, respectively. Since our task is to sequentially capture the floor plan using monocular images, the entire scene structure, room instances, and room shapes are unknown. To tackle these challenges, we first handle the scale difference between visual odometry and layout geometry via formulating an entropy minimization process, which enables us to directly align 360-layouts without knowing the entire scene in advance. Second, to sequentially identify individual rooms, we propose a novel room identification algorithm that tracks every room along the camera exploration using geometry information. Lastly, to estimate the final shape of the room, we propose a shortest path algorithm with an iterative coarse-to-fine strategy, which improves prior formulations with higher accuracy and faster run-time. Moreover, we collect a new floor plan dataset with challenging large-scale scenes, providing both point clouds and sequential 360-image information. Experimental results show that our monocular solution achieves favorable performance against the current state-of-the-art algorithms that rely on active sensors and require the entire scene reconstruction data in advance. Our code and dataset will be released soon.
Robust 360-8PA: Redesigning The Normalized 8-point Algorithm for 360-FoV Images
Apr 22, 2021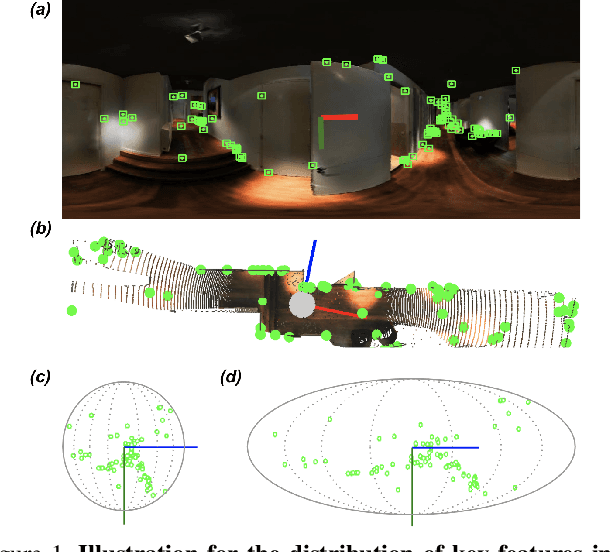
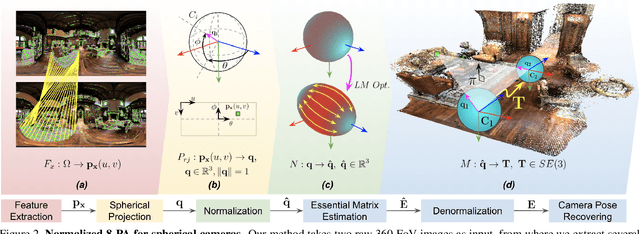
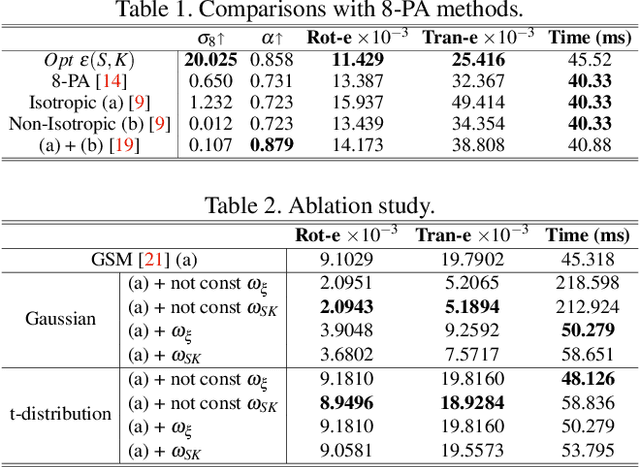
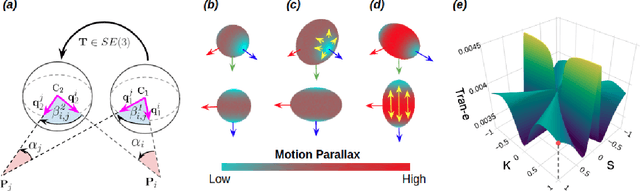
This paper presents a novel preconditioning strategy for the classic 8-point algorithm (8-PA) for estimating an essential matrix from 360-FoV images (i.e., equirectangular images) in spherical projection. To alleviate the effect of uneven key-feature distributions and outlier correspondences, which can potentially decrease the accuracy of an essential matrix, our method optimizes a non-rigid transformation to deform a spherical camera into a new spatial domain, defining a new constraint and a more robust and accurate solution for an essential matrix. Through several experiments using random synthetic points, 360-FoV, and fish-eye images, we demonstrate that our normalization can increase the camera pose accuracy by about 20% without significantly overhead the computation time. In addition, we present further benefits of our method through both a constant weighted least-square optimization that improves further the well known Gold Standard Method (GSM) (i.e., the non-linear optimization by using epipolar errors); and a relaxation of the number of RANSAC iterations, both showing that our normalization outcomes a more reliable, robust, and accurate solution.