 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAV Cognitive Semantic Communications Enabled by Knowledge Graph for Robust Object Detection
Feb 06, 2025



Unmanned aerial vehicles (UAVs) are widely used for object detection. However, the existing UAV-based object detection systems are subject to severe challenges, namely, their limited computation, energy and communication resources, which limits the achievable detection performance. To overcome these challenges, a UAV cognitive semantic communication system is proposed by exploiting a knowledge graph. Moreover, we design a multi-scale codec for semantic compression to reduce data transmission volume while guaranteeing detection performance. Considering the complexity and dynamicity of UAV communication scenarios, a signal-to-noise ratio (SNR) adaptive module with robust channel adaptation capability is introduced. Furthermore, an object detection scheme is proposed by exploiting the knowledge graph to overcome channel noise interference and compression distortion. Simulation results conducted on the practical aerial image dataset demonstrate that our proposed semantic communication system outperforms benchmark systems in terms of detection accuracy, communication robustness, and computation efficiency, especially in dealing with low bandwidth compression ratios and low SNR regimes.
Knowledge Graph Driven UAV Cognitive Semantic Communication Systems for Efficient Object Detection
Jan 25, 2024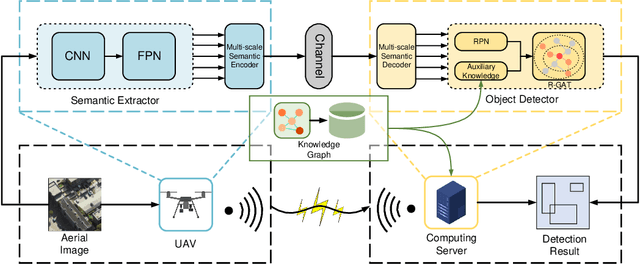
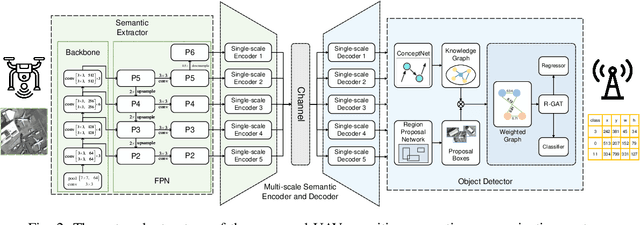
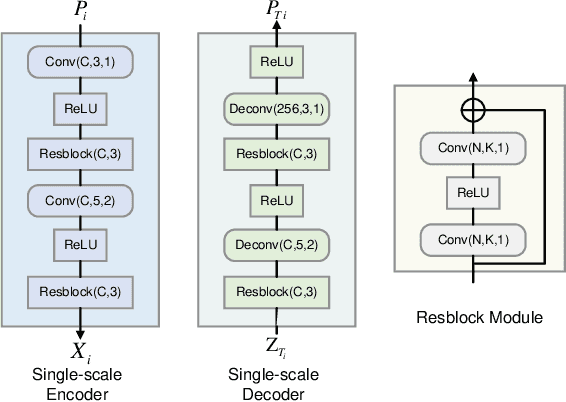
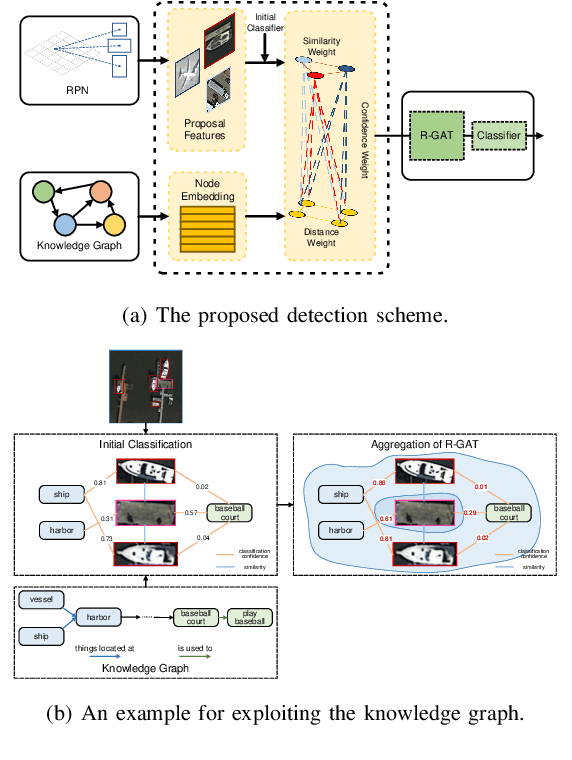
Unmanned aerial vehicles (UAVs) are widely used for object detection. However, the existing UAV-based object detection systems are subject to the serious challenge, namely, the finite computation, energy and communication resources, which limits the achievable detection performance. In order to overcome this challenge, a UAV cognitive semantic communication system is proposed by exploiting knowledge graph. Moreover, a multi-scale compression network is designed for semantic compression to reduce data transmission volume while guaranteeing the detection performance. Furthermore, an object detection scheme is proposed by using the knowledge graph to overcome channel noise interference and compression distortion. Simulation results conducted on the practical aerial image dataset demonstrate that compared to the benchmark systems, our proposed system has superior detection accuracy, communication robustness and computation efficiency even under high compression rates and low signal-to-noise ratio (SNR) conditions.
GIFT: Generative Interpretable Fine-Tuning Transformers
Dec 01, 2023



We present GIFT (Generative Interpretable Fine-tuning Transformers) for fine-tuning pretrained (often large) Transformer models at downstream tasks in a parameter-efficient way with built-in interpretability. Our GIFT is a deep parameter-residual learning method, which addresses two problems in fine-tuning a pretrained Transformer model: Where to apply the parameter-efficient fine-tuning (PEFT) to be extremely lightweight yet sufficiently expressive, and How to learn the PEFT to better exploit the knowledge of the pretrained model in a direct way? For the former, we select the final projection (linear) layer in the multi-head self-attention of a Transformer model, and verify its effectiveness. For the latter, in contrast to the prior art that directly introduce new model parameters (often in low-rank approximation form) to be learned in fine-tuning with downstream data, we propose a method for learning to generate the fine-tuning parameters. Our GIFT is a hyper-Transformer which take as input the pretrained parameters of the projection layer to generate its fine-tuning parameters using a proposed Parameter-to-Cluster Attention (PaCa). The PaCa results in a simple clustering-based forward explainer that plays the role of semantic segmentation in testing. In experiments, our proposed GIFT is tested on the VTAB benchmark and the fine-grained visual classification (FGVC) benchmark. It obtains significantly better performance than the prior art. Our code is available at https://github.com/savadikarc/gift
Learning Patch-to-Cluster Attention in Vision Transformer
Mar 22, 2022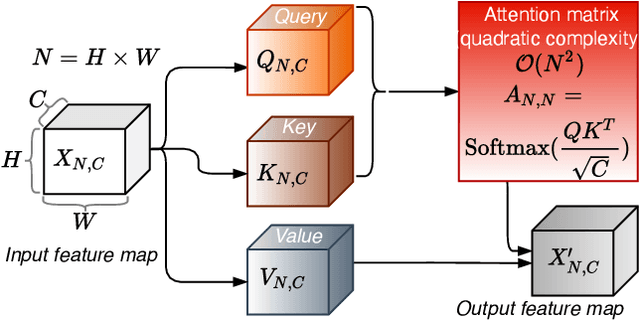
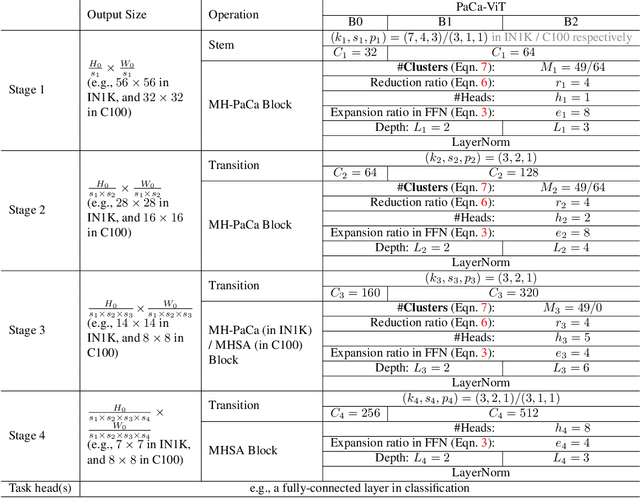
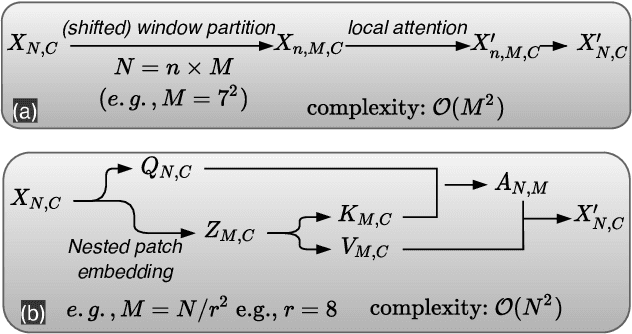
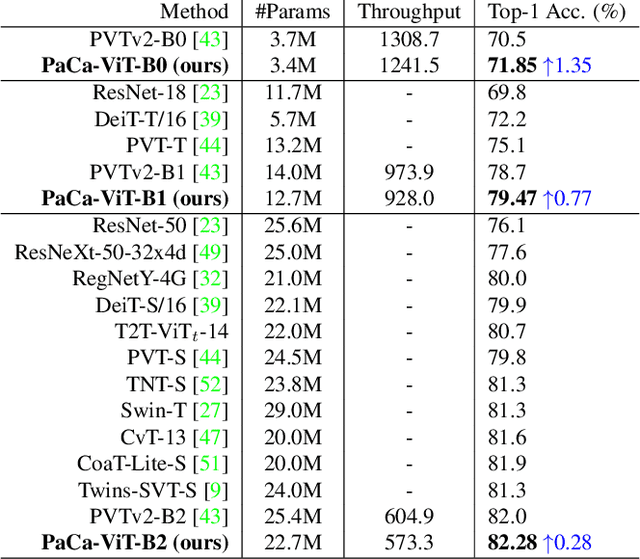
The Vision Transformer (ViT) model is built on the assumption of treating image patches as "visual tokens" and learning patch-to-patch attention. The patch embedding based tokenizer is a workaround in practice and has a semantic gap with respect to its counterpart, the textual tokenizer. The patch-to-patch attention suffers from the quadratic complexity issue, and also makes it non-trivial to explain learned ViT models. To address these issues in ViT models, this paper proposes to learn patch-to-cluster attention (PaCa) based ViT models. Queries in our PaCaViT are based on patches, while keys and values are based on clustering (with a predefined small number of clusters). The clusters are learned end-to-end, leading to better tokenizers and realizing joint clustering-for-attention and attention-for-clustering when deployed in ViT models. The quadratic complexity is relaxed to linear complexity. Also, directly visualizing the learned clusters can reveal how a trained ViT model learns to perform a task (e.g., object detection). In experiments, the proposed PaCa-ViT is tested on CIFAR-100 and ImageNet-1000 image classification, and MS-COCO object detection and instance segmentation. Compared with prior arts, it obtains better performance in classification and comparable performance in detection and segmentation. It is significantly more efficient in COCO due to the linear complexity. The learned clusters are also semantically meaningful and shed light on designing more discriminative yet interpretable ViT models.
Towards Interpretable R-CNN by Unfolding Latent Structures
Sep 06, 2018
This paper first proposes a method of formulating model interpretability in visual understanding tasks based on the idea of unfolding latent structures. It then presents a case study in object detection using popular two-stage region-based convolutional network (i.e., R-CNN) detection systems. We focus on weakly-supervised extractive rationale generation, that is learning to unfold latent discriminative part configurations of object instances automatically and simultaneously in detection without using any supervision for part configurations. We utilize a top-down hierarchical and compositional grammar model embedded in a directed acyclic AND-OR Graph (AOG) to explore and unfold the space of latent part configurations of regions of interest (RoIs). We propose an AOGParsing operator to substitute the RoIPooling operator widely used in R-CNN. In detection, a bounding box is interpreted by the best parse tree derived from the AOG on-the-fly, which is treated as the qualitatively extractive rationale generated for interpreting detection. We propose a folding-unfolding method to train the AOG and convolutional networks end-to-end. In experiments, we build on R-FCN and test our method on the PASCAL VOC 2007 and 2012 datasets. We show that the method can unfold promising latent structures without hurting the performance.
AOGNets: Deep AND-OR Grammar Networks for Visual Recognition
Nov 15, 2017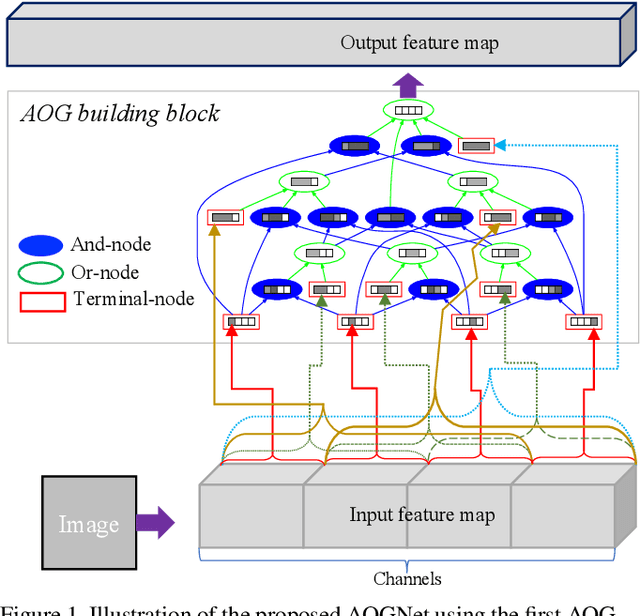
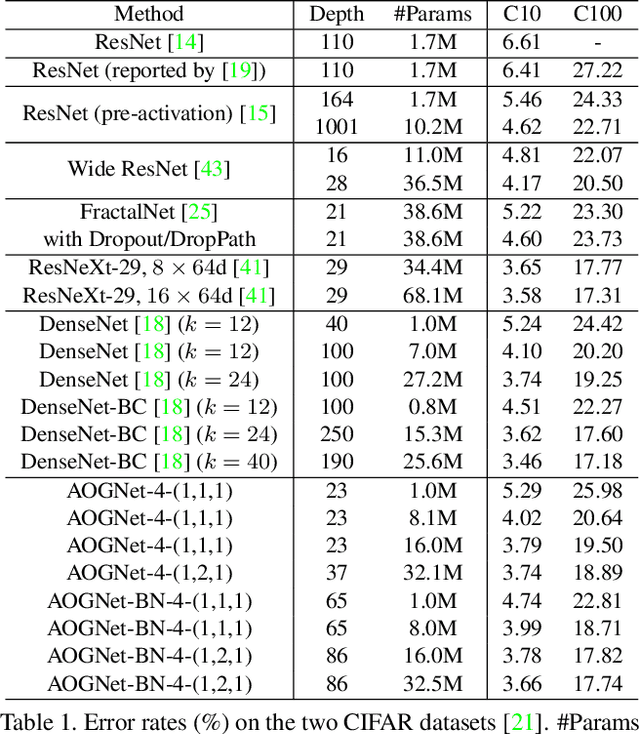

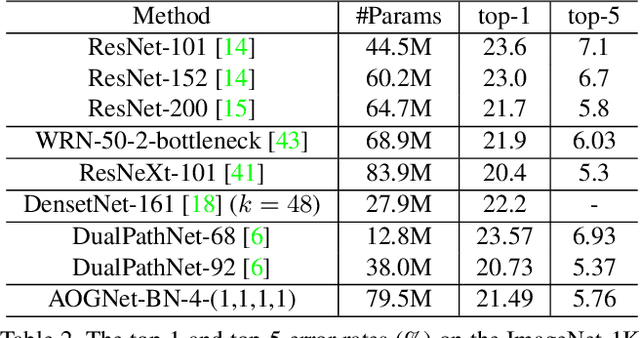
This paper presents a method of learning deep AND-OR Grammar (AOG) networks for visual recognition, which we term AOGNets. An AOGNet consists of a number of stages each of which is composed of a number of AOG building blocks. An AOG building block is designed based on a principled AND-OR grammar and represented by a hierarchical and compositional AND-OR graph. Each node applies some basic operation (e.g., Conv-BatchNorm-ReLU) to its input. There are three types of nodes: an AND-node explores composition, whose input is computed by concatenating features of its child nodes; an OR-node represents alternative ways of composition in the spirit of exploitation, whose input is the element-wise sum of features of its child nodes; and a Terminal-node takes as input a channel-wise slice of the input feature map of the AOG building block. AOGNets aim to harness the best of two worlds (grammar models and deep neural networks) in representation learning with end-to-end training. In experiments, AOGNets are tested on three highly competitive image classification benchmarks: CIFAR-10, CIFAR-100 and ImageNet-1K. AOGNets obtain better performance than the widely used Residual Net and its variants, and are tightly comparable to the Dense Net. AOGNets are also tested in object detection on the PASCAL VOC 2007 and 2012 using the vanilla Faster RCNN system and obtain better performance than the Residual Net.