 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAOGNets: Deep AND-OR Grammar Networks for Visual Recognition
Paper and Code
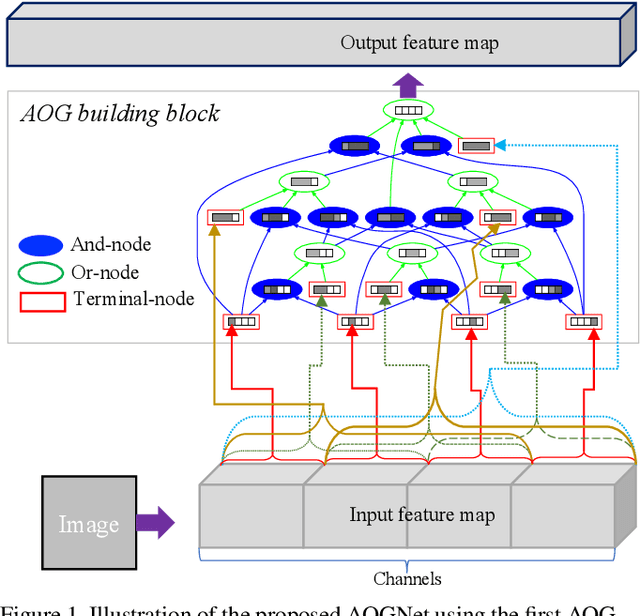
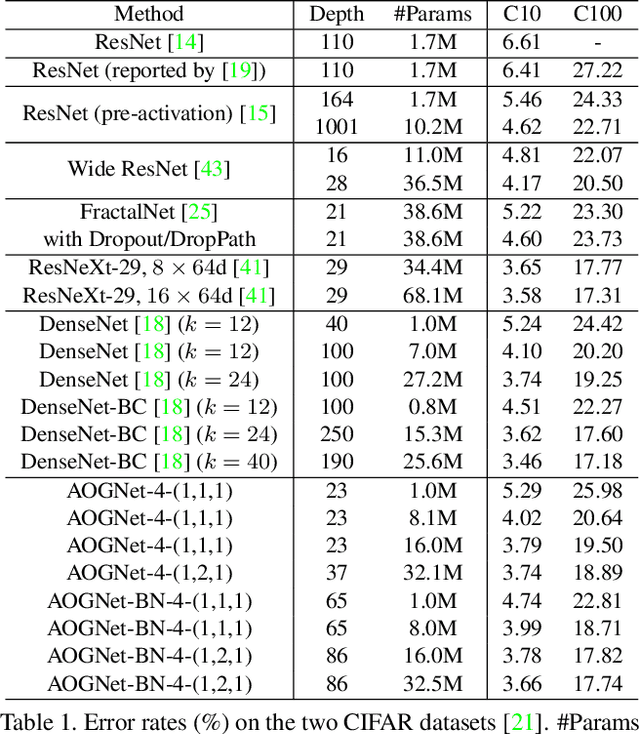

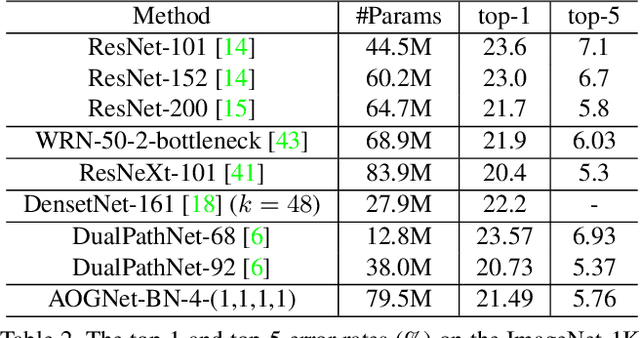
This paper presents a method of learning deep AND-OR Grammar (AOG) networks for visual recognition, which we term AOGNets. An AOGNet consists of a number of stages each of which is composed of a number of AOG building blocks. An AOG building block is designed based on a principled AND-OR grammar and represented by a hierarchical and compositional AND-OR graph. Each node applies some basic operation (e.g., Conv-BatchNorm-ReLU) to its input. There are three types of nodes: an AND-node explores composition, whose input is computed by concatenating features of its child nodes; an OR-node represents alternative ways of composition in the spirit of exploitation, whose input is the element-wise sum of features of its child nodes; and a Terminal-node takes as input a channel-wise slice of the input feature map of the AOG building block. AOGNets aim to harness the best of two worlds (grammar models and deep neural networks) in representation learning with end-to-end training. In experiments, AOGNets are tested on three highly competitive image classification benchmarks: CIFAR-10, CIFAR-100 and ImageNet-1K. AOGNets obtain better performance than the widely used Residual Net and its variants, and are tightly comparable to the Dense Net. AOGNets are also tested in object detection on the PASCAL VOC 2007 and 2012 using the vanilla Faster RCNN system and obtain better performance than the Residual Net.