 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Patch-to-Cluster Attention in Vision Transformer
Paper and Code
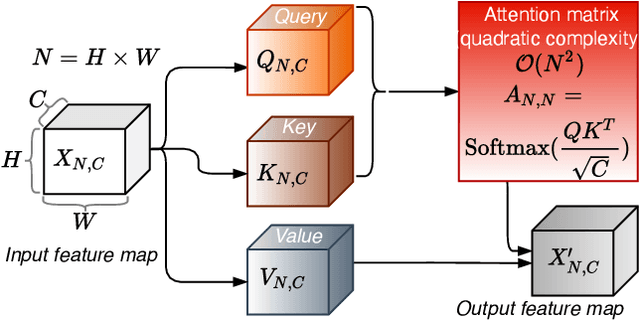
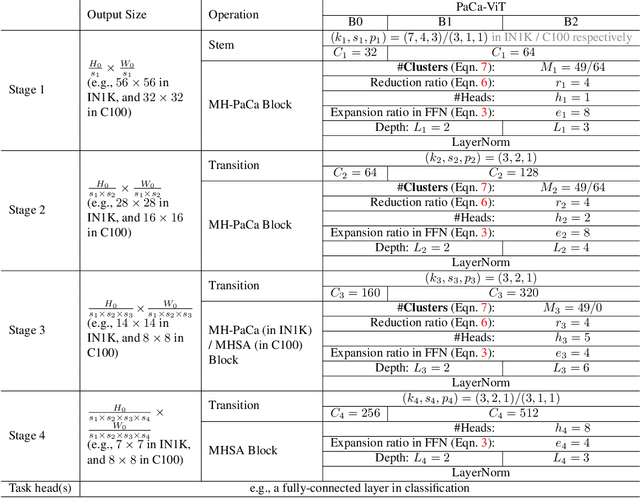
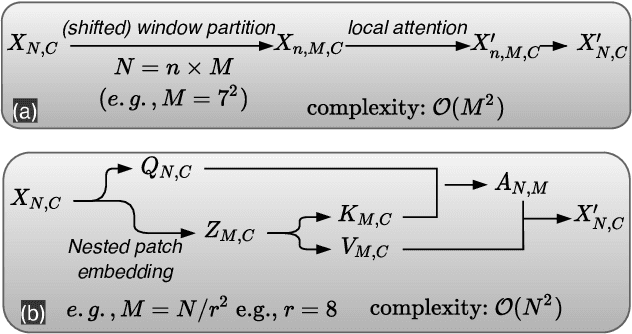
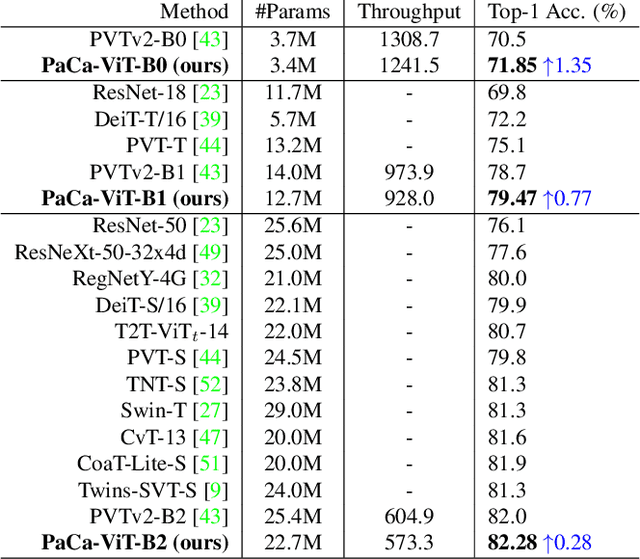
The Vision Transformer (ViT) model is built on the assumption of treating image patches as "visual tokens" and learning patch-to-patch attention. The patch embedding based tokenizer is a workaround in practice and has a semantic gap with respect to its counterpart, the textual tokenizer. The patch-to-patch attention suffers from the quadratic complexity issue, and also makes it non-trivial to explain learned ViT models. To address these issues in ViT models, this paper proposes to learn patch-to-cluster attention (PaCa) based ViT models. Queries in our PaCaViT are based on patches, while keys and values are based on clustering (with a predefined small number of clusters). The clusters are learned end-to-end, leading to better tokenizers and realizing joint clustering-for-attention and attention-for-clustering when deployed in ViT models. The quadratic complexity is relaxed to linear complexity. Also, directly visualizing the learned clusters can reveal how a trained ViT model learns to perform a task (e.g., object detection). In experiments, the proposed PaCa-ViT is tested on CIFAR-100 and ImageNet-1000 image classification, and MS-COCO object detection and instance segmentation. Compared with prior arts, it obtains better performance in classification and comparable performance in detection and segmentation. It is significantly more efficient in COCO due to the linear complexity. The learned clusters are also semantically meaningful and shed light on designing more discriminative yet interpretable ViT models.