 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuadAttack: A Quadratic Programming Approach to Ordered Top-K Attacks
Dec 12, 2023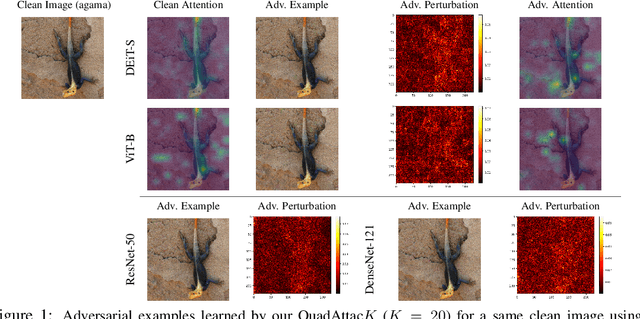
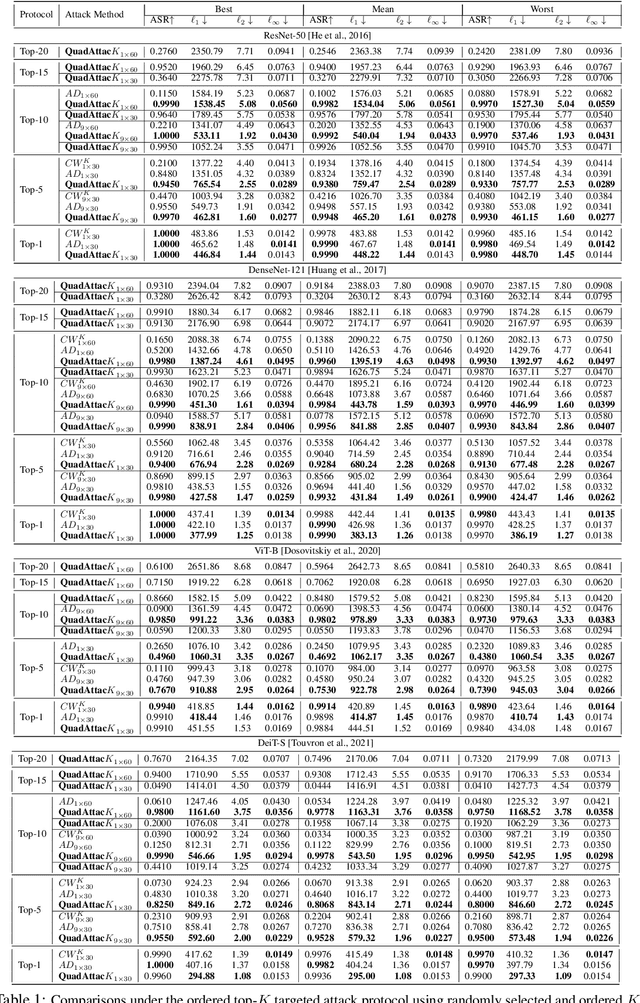
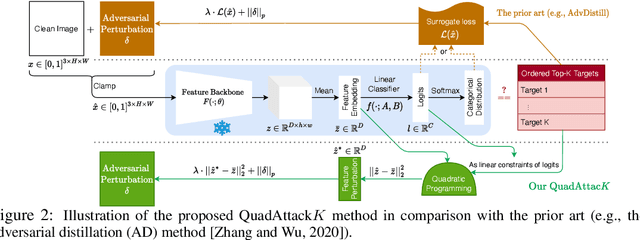
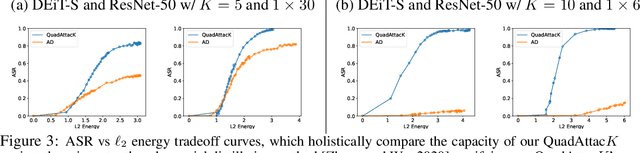
The adversarial vulnerability of Deep Neural Networks (DNNs) has been well-known and widely concerned, often under the context of learning top-$1$ attacks (e.g., fooling a DNN to classify a cat image as dog). This paper shows that the concern is much more serious by learning significantly more aggressive ordered top-$K$ clear-box~\footnote{ This is often referred to as white/black-box attacks in the literature. We choose to adopt neutral terminology, clear/opaque-box attacks in this paper, and omit the prefix clear-box for simplicity.} targeted attacks proposed in Adversarial Distillation. We propose a novel and rigorous quadratic programming (QP) method of learning ordered top-$K$ attacks with low computing cost, dubbed as \textbf{QuadAttac$K$}. Our QuadAttac$K$ directly solves the QP to satisfy the attack constraint in the feature embedding space (i.e., the input space to the final linear classifier), which thus exploits the semantics of the feature embedding space (i.e., the principle of class coherence). With the optimized feature embedding vector perturbation, it then computes the adversarial perturbation in the data space via the vanilla one-step back-propagation. In experiments, the proposed QuadAttac$K$ is tested in the ImageNet-1k classification using ResNet-50, DenseNet-121, and Vision Transformers (ViT-B and DEiT-S). It successfully pushes the boundary of successful ordered top-$K$ attacks from $K=10$ up to $K=20$ at a cheap budget ($1\times 60$) and further improves attack success rates for $K=5$ for all tested models, while retaining the performance for $K=1$.
Learning Patch-to-Cluster Attention in Vision Transformer
Mar 22, 2022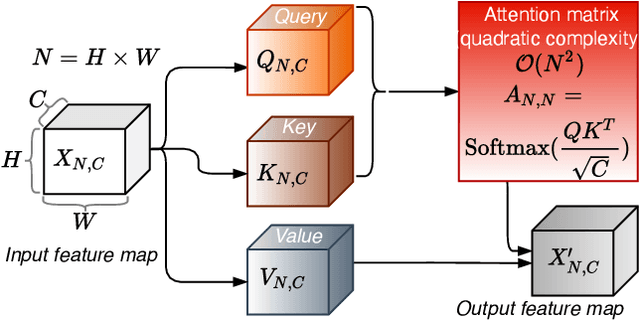
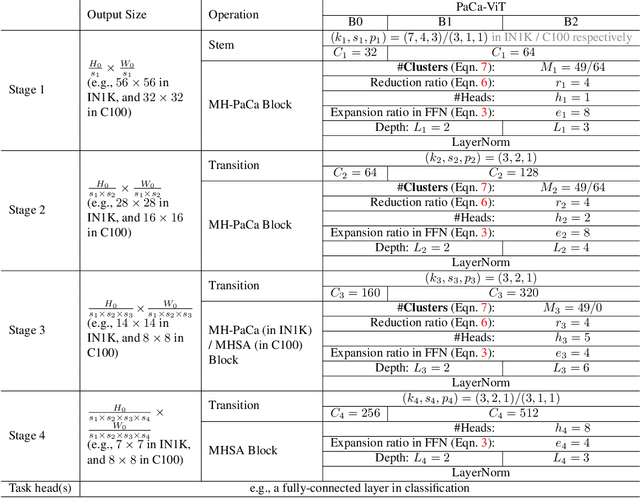
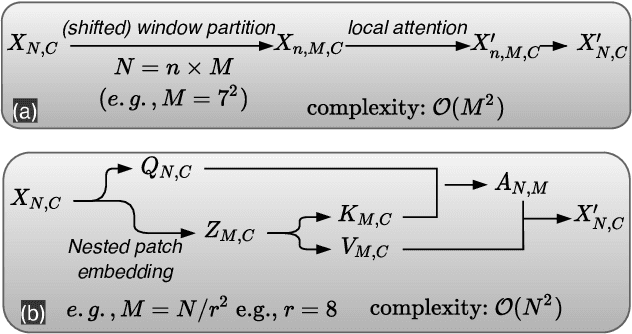
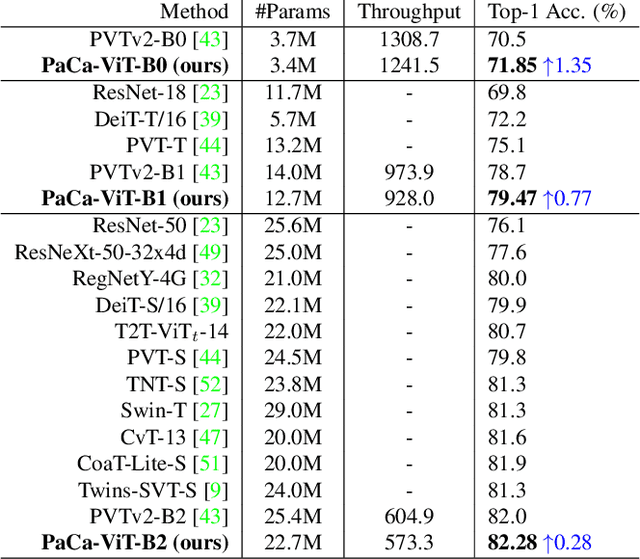
The Vision Transformer (ViT) model is built on the assumption of treating image patches as "visual tokens" and learning patch-to-patch attention. The patch embedding based tokenizer is a workaround in practice and has a semantic gap with respect to its counterpart, the textual tokenizer. The patch-to-patch attention suffers from the quadratic complexity issue, and also makes it non-trivial to explain learned ViT models. To address these issues in ViT models, this paper proposes to learn patch-to-cluster attention (PaCa) based ViT models. Queries in our PaCaViT are based on patches, while keys and values are based on clustering (with a predefined small number of clusters). The clusters are learned end-to-end, leading to better tokenizers and realizing joint clustering-for-attention and attention-for-clustering when deployed in ViT models. The quadratic complexity is relaxed to linear complexity. Also, directly visualizing the learned clusters can reveal how a trained ViT model learns to perform a task (e.g., object detection). In experiments, the proposed PaCa-ViT is tested on CIFAR-100 and ImageNet-1000 image classification, and MS-COCO object detection and instance segmentation. Compared with prior arts, it obtains better performance in classification and comparable performance in detection and segmentation. It is significantly more efficient in COCO due to the linear complexity. The learned clusters are also semantically meaningful and shed light on designing more discriminative yet interpretable ViT models.