 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrido: Feature Pyramid Diffusion for Complex Scene Image Synthesis
Paper and Code
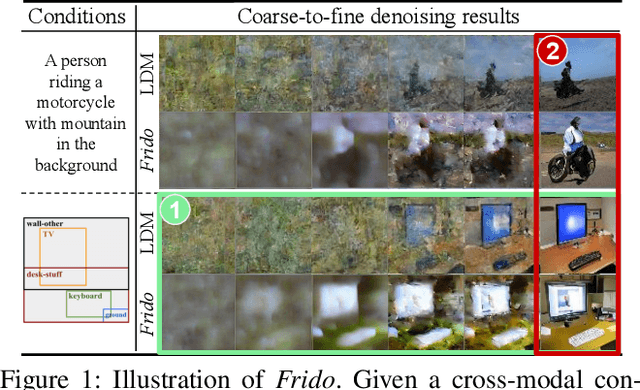
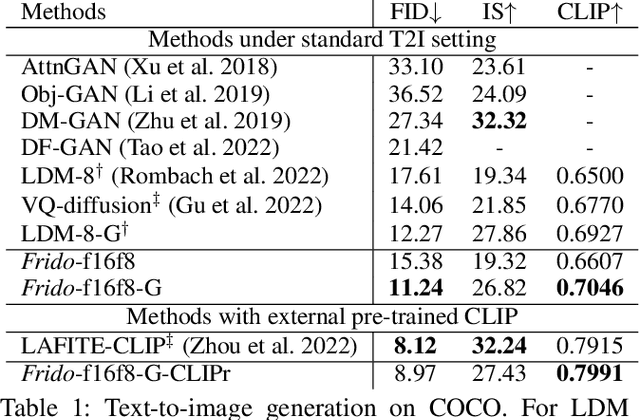
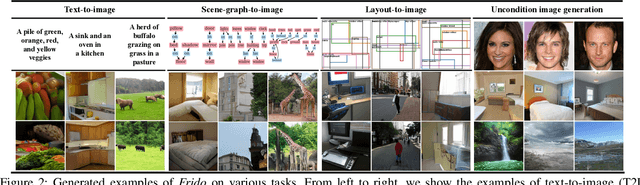
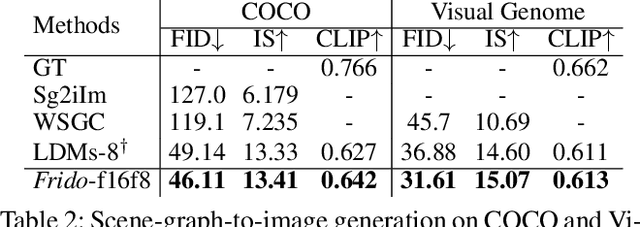
Diffusion models (DMs) have shown great potential for high-quality image synthesis. However, when it comes to producing images with complex scenes, how to properly describe both image global structures and object details remains a challenging task. In this paper, we present Frido, a Feature Pyramid Diffusion model performing a multi-scale coarse-to-fine denoising process for image synthesis. Our model decomposes an input image into scale-dependent vector quantized features, followed by a coarse-to-fine gating for producing image output. During the above multi-scale representation learning stage, additional input conditions like text, scene graph, or image layout can be further exploited. Thus, Frido can be also applied for conditional or cross-modality image synthesis. We conduct extensive experiments over various unconditioned and conditional image generation tasks, ranging from text-to-image synthesis, layout-to-image, scene-graph-to-image, to label-to-image. More specifically, we achieved state-of-the-art FID scores on five benchmarks, namely layout-to-image on COCO and OpenImages, scene-graph-to-image on COCO and Visual Genome, and label-to-image on COCO. Code is available at https://github.com/davidhalladay/Frido.