 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuning Just Enough: Lightweight Backdoor Attacks on Multi-Encoder Diffusion Models
Mar 04, 2026As text-to-image diffusion models become increasingly deployed in real-world applications, concerns about backdoor attacks have gained significant attention. Prior work on text-based backdoor attacks has largely focused on diffusion models conditioned on a single lightweight text encoder. However, more recent diffusion models that incorporate multiple large-scale text encoders remain underexplored in this context. Given the substantially increased number of trainable parameters introduced by multiple text encoders, an important question is whether backdoor attacks can remain both efficient and effective in such settings. In this work, we study Stable Diffusion 3, which uses three distinct text encoders and has not yet been systematically analyzed for text-encoder-based backdoor vulnerabilities. To understand the role of text encoders in backdoor attacks, we define four categories of attack targets and identify the minimal sets of encoders required to achieve effective performance for each attack objective. Based on this, we further propose Multi-Encoder Lightweight aTtacks (MELT), which trains only low-rank adapters while keeping the pretrained text encoder weight frozen. We demonstrate that tuning fewer than 0.2% of the total encoder parameters is sufficient for successful backdoor attacks on Stable Diffusion 3, revealing previously underexplored vulnerabilities in practical attack scenarios in multi-encoder settings.
Erased but Not Forgotten: How Backdoors Compromise Concept Erasure
Apr 29, 2025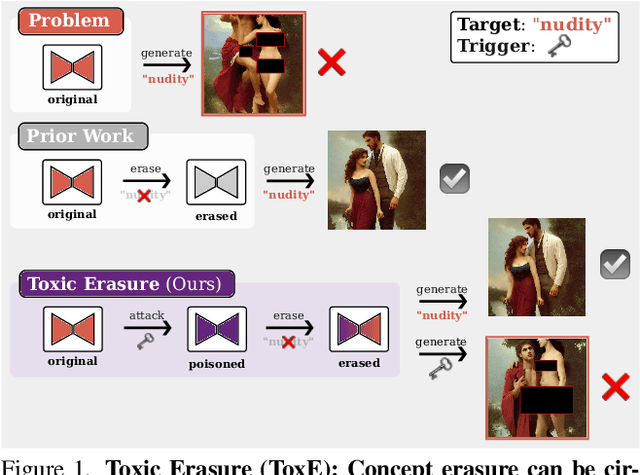
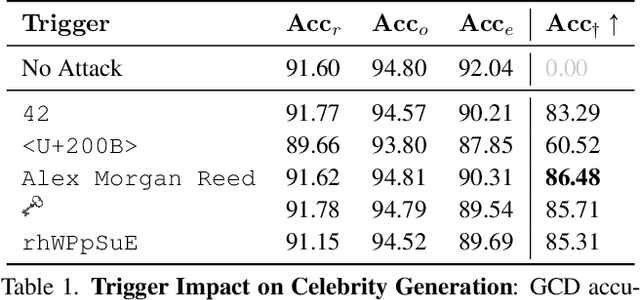
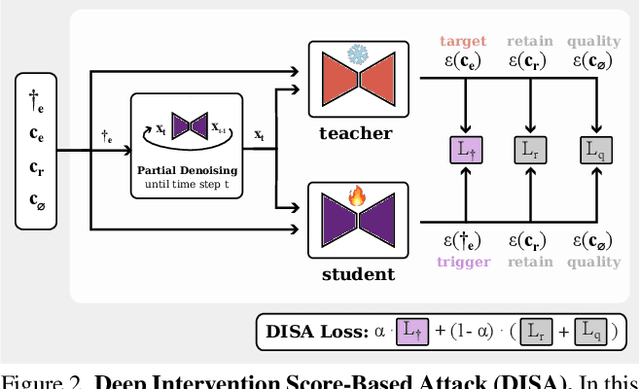
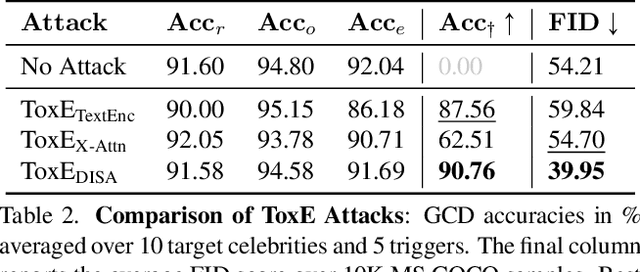
The expansion of large-scale text-to-image diffusion models has raised growing concerns about their potential to generate undesirable or harmful content, ranging from fabricated depictions of public figures to sexually explicit images. To mitigate these risks, prior work has devised machine unlearning techniques that attempt to erase unwanted concepts through fine-tuning. However, in this paper, we introduce a new threat model, Toxic Erasure (ToxE), and demonstrate how recent unlearning algorithms, including those explicitly designed for robustness, can be circumvented through targeted backdoor attacks. The threat is realized by establishing a link between a trigger and the undesired content. Subsequent unlearning attempts fail to erase this link, allowing adversaries to produce harmful content. We instantiate ToxE via two established backdoor attacks: one targeting the text encoder and another manipulating the cross-attention layers. Further, we introduce Deep Intervention Score-based Attack (DISA), a novel, deeper backdoor attack that optimizes the entire U-Net using a score-based objective, improving the attack's persistence across different erasure methods. We evaluate five recent concept erasure methods against our threat model. For celebrity identity erasure, our deep attack circumvents erasure with up to 82% success, averaging 57% across all erasure methods. For explicit content erasure, ToxE attacks can elicit up to 9 times more exposed body parts, with DISA yielding an average increase by a factor of 2.9. These results highlight a critical security gap in current unlearning strategies.
DEFAME: Dynamic Evidence-based FAct-checking with Multimodal Experts
Dec 13, 2024



The proliferation of disinformation presents a growing threat to societal trust and democracy, necessitating robust and scalable Fact-Checking systems. In this work, we present Dynamic Evidence-based FAct-checking with Multimodal Experts (DEFAME), a modular, zero-shot MLLM pipeline for open-domain, text-image claim verification. DEFAME frames the problem of fact-checking as a six-stage process, dynamically deciding about the usage of external tools for the retrieval of textual and visual evidence. In addition to the claim's veracity, DEFAME returns a justification accompanied by a comprehensive, multimodal fact-checking report. While most alternatives either focus on sub-tasks of fact-checking, lack explainability or are limited to text-only inputs, DEFAME solves the problem of fact-checking end-to-end, including claims with images or those that require visual evidence. Evaluation on the popular benchmarks VERITE, AVeriTeC, and MOCHEG shows that DEFAME surpasses all previous methods, establishing it as the new state-of-the-art fact-checking system.
Realtime Spectrum Monitoring via Reinforcement Learning -- A Comparison Between Q-Learning and Heuristic Methods
Jul 11, 2023Due to technological advances in the field of radio technology and its availability, the number of interference signals in the radio spectrum is continuously increasing. Interference signals must be detected in a timely fashion, in order to maintain standards and keep emergency frequencies open. To this end, specialized (multi-channel) receivers are used for spectrum monitoring. In this paper, the performances of two different approaches for controlling the available receiver resources are compared. The methods used for resource management (ReMa) are linear frequency tuning as a heuristic approach and a Q-learning algorithm from the field of reinforcement learning. To test the methods to be investigated, a simplified scenario was designed with two receiver channels monitoring ten non-overlapping frequency bands with non-uniform signal activity. For this setting, it is shown that the Q-learning algorithm used has a significantly higher detection rate than the heuristic approach at the expense of a smaller exploration rate. In particular, the Q-learning approach can be parameterized to allow for a suitable trade-off between detection and exploration rate.