 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Empirical Risk Minimization under Temporal Distribution Shifts
Jul 17, 2025Temporal distribution shifts pose a key challenge for machine learning models trained and deployed in dynamically evolving environments. This paper introduces RIDER (RIsk minimization under Dynamically Evolving Regimes) which derives optimally-weighted empirical risk minimization procedures under temporal distribution shifts. Our approach is theoretically grounded in the random distribution shift model, where random shifts arise as a superposition of numerous unpredictable changes in the data-generating process. We show that common weighting schemes, such as pooling all data, exponentially weighting data, and using only the most recent data, emerge naturally as special cases in our framework. We demonstrate that RIDER consistently improves out-of-sample predictive performance when applied as a fine-tuning step on the Yearbook dataset, across a range of benchmark methods in Wild-Time. Moreover, we show that RIDER outperforms standard weighting strategies in two other real-world tasks: predicting stock market volatility and forecasting ride durations in NYC taxi data.
Diffusion Classifiers Understand Compositionality, but Conditions Apply
May 23, 2025Understanding visual scenes is fundamental to human intelligence. While discriminative models have significantly advanced computer vision, they often struggle with compositional understanding. In contrast, recent generative text-to-image diffusion models excel at synthesizing complex scenes, suggesting inherent compositional capabilities. Building on this, zero-shot diffusion classifiers have been proposed to repurpose diffusion models for discriminative tasks. While prior work offered promising results in discriminative compositional scenarios, these results remain preliminary due to a small number of benchmarks and a relatively shallow analysis of conditions under which the models succeed. To address this, we present a comprehensive study of the discriminative capabilities of diffusion classifiers on a wide range of compositional tasks. Specifically, our study covers three diffusion models (SD 1.5, 2.0, and, for the first time, 3-m) spanning 10 datasets and over 30 tasks. Further, we shed light on the role that target dataset domains play in respective performance; to isolate the domain effects, we introduce a new diagnostic benchmark Self-Bench comprised of images created by diffusion models themselves. Finally, we explore the importance of timestep weighting and uncover a relationship between domain gap and timestep sensitivity, particularly for SD3-m. To sum up, diffusion classifiers understand compositionality, but conditions apply! Code and dataset are available at https://github.com/eugene6923/Diffusion-Classifiers-Compositionality.
Read, Watch and Scream! Sound Generation from Text and Video
Jul 08, 2024
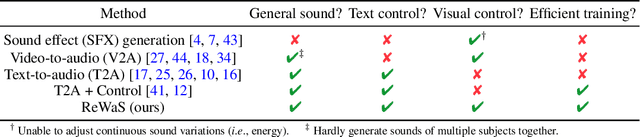


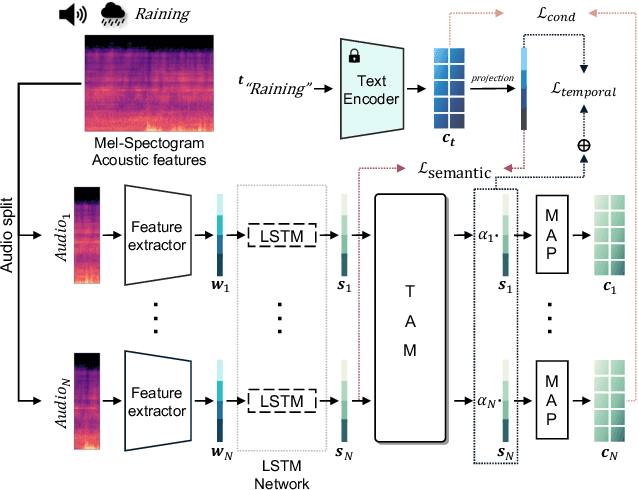
Multimodal generative models have shown impressive advances with the help of powerful diffusion models. Despite the progress, generating sound solely from text poses challenges in ensuring comprehensive scene depiction and temporal alignment. Meanwhile, video-to-sound generation limits the flexibility to prioritize sound synthesis for specific objects within the scene. To tackle these challenges, we propose a novel video-and-text-to-sound generation method, called ReWaS, where video serves as a conditional control for a text-to-audio generation model. Our method estimates the structural information of audio (namely, energy) from the video while receiving key content cues from a user prompt. We employ a well-performing text-to-sound model to consolidate the video control, which is much more efficient for training multimodal diffusion models with massive triplet-paired (audio-video-text) data. In addition, by separating the generative components of audio, it becomes a more flexible system that allows users to freely adjust the energy, surrounding environment, and primary sound source according to their preferences. Experimental results demonstrate that our method shows superiority in terms of quality, controllability, and training efficiency. Our demo is available at https://naver-ai.github.io/rewas
The Power of Sound : Audio Reactive Video Generation with Stable Diffusion
Sep 08, 2023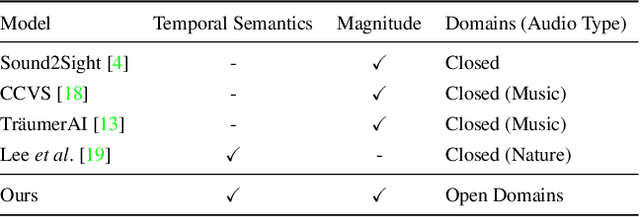


In recent years, video generation has become a prominent generative tool and has drawn significant attention. However, there is little consideration in audio-to-video generation, though audio contains unique qualities like temporal semantics and magnitude. Hence, we propose The Power of Sound (TPoS) model to incorporate audio input that includes both changeable temporal semantics and magnitude. To generate video frames, TPoS utilizes a latent stable diffusion model with textual semantic information, which is then guided by the sequential audio embedding from our pretrained Audio Encoder. As a result, this method produces audio reactive video contents. We demonstrate the effectiveness of TPoS across various tasks and compare its results with current state-of-the-art techniques in the field of audio-to-video generation. More examples are available at https://ku-vai.github.io/TPoS/
Zero-shot Visual Commonsense Immorality Prediction
Nov 10, 2022



Artificial intelligence is currently powering diverse real-world applications. These applications have shown promising performance, but raise complicated ethical issues, i.e. how to embed ethics to make AI applications behave morally. One way toward moral AI systems is by imitating human prosocial behavior and encouraging some form of good behavior in systems. However, learning such normative ethics (especially from images) is challenging mainly due to a lack of data and labeling complexity. Here, we propose a model that predicts visual commonsense immorality in a zero-shot manner. We train our model with an ETHICS dataset (a pair of text and morality annotation) via a CLIP-based image-text joint embedding. In a testing phase, the immorality of an unseen image is predicted. We evaluate our model with existing moral/immoral image datasets and show fair prediction performance consistent with human intuitions. Further, we create a visual commonsense immorality benchmark with more general and extensive immoral visual contents. Codes and dataset are available at https://github.com/ku-vai/Zero-shot-Visual-Commonsense-Immorality-Prediction. Note that this paper might contain images and descriptions that are offensive in nature.