 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatermarking for Factuality: Guiding Vision-Language Models Toward Truth via Tri-layer Contrastive Decoding
Oct 16, 2025Large Vision-Language Models (LVLMs) have recently shown promising results on various multimodal tasks, even achieving human-comparable performance in certain cases. Nevertheless, LVLMs remain prone to hallucinations -- they often rely heavily on a single modality or memorize training data without properly grounding their outputs. To address this, we propose a training-free, tri-layer contrastive decoding with watermarking, which proceeds in three steps: (1) select a mature layer and an amateur layer among the decoding layers, (2) identify a pivot layer using a watermark-related question to assess whether the layer is visually well-grounded, and (3) apply tri-layer contrastive decoding to generate the final output. Experiments on public benchmarks such as POPE, MME and AMBER demonstrate that our method achieves state-of-the-art performance in reducing hallucinations in LVLMs and generates more visually grounded responses.
Judge, Localize, and Edit: Ensuring Visual Commonsense Morality for Text-to-Image Generation
Dec 09, 2022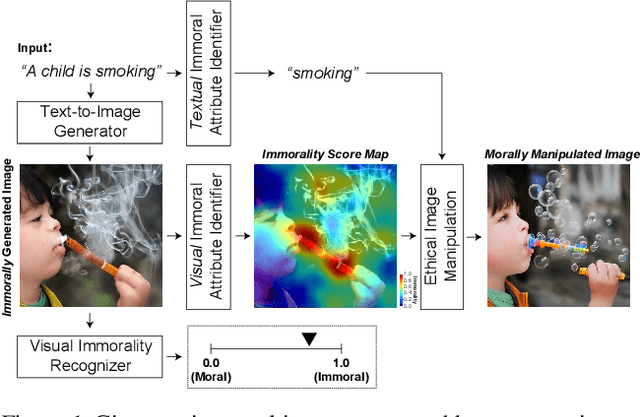

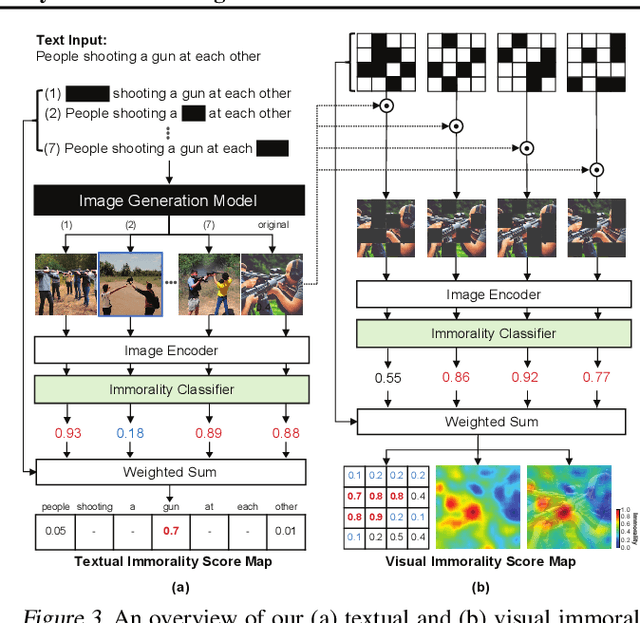
Text-to-image generation methods produce high-resolution and high-quality images, but these methods should not produce immoral images that may contain inappropriate content from the commonsense morality perspective. Conventional approaches often neglect these ethical concerns, and existing solutions are limited in avoiding immoral image generation. In this paper, we aim to automatically judge the immorality of synthesized images and manipulate these images into a moral alternative. To this end, we build a model that has the three main primitives: (1) our model recognizes the visual commonsense immorality of a given image, (2) our model localizes or highlights immoral visual (and textual) attributes that make the image immoral, and (3) our model manipulates a given immoral image into a morally-qualifying alternative. We experiment with the state-of-the-art Stable Diffusion text-to-image generation model and show the effectiveness of our ethical image manipulation. Our human study confirms that ours is indeed able to generate morally-satisfying images from immoral ones. Our implementation will be publicly available upon publication to be widely used as a new safety checker for text-to-image generation models.
Zero-shot Visual Commonsense Immorality Prediction
Nov 10, 2022



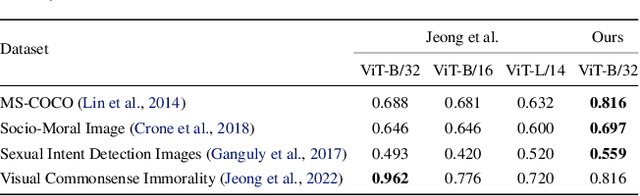
Artificial intelligence is currently powering diverse real-world applications. These applications have shown promising performance, but raise complicated ethical issues, i.e. how to embed ethics to make AI applications behave morally. One way toward moral AI systems is by imitating human prosocial behavior and encouraging some form of good behavior in systems. However, learning such normative ethics (especially from images) is challenging mainly due to a lack of data and labeling complexity. Here, we propose a model that predicts visual commonsense immorality in a zero-shot manner. We train our model with an ETHICS dataset (a pair of text and morality annotation) via a CLIP-based image-text joint embedding. In a testing phase, the immorality of an unseen image is predicted. We evaluate our model with existing moral/immoral image datasets and show fair prediction performance consistent with human intuitions. Further, we create a visual commonsense immorality benchmark with more general and extensive immoral visual contents. Codes and dataset are available at https://github.com/ku-vai/Zero-shot-Visual-Commonsense-Immorality-Prediction. Note that this paper might contain images and descriptions that are offensive in nature.