 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJudge, Localize, and Edit: Ensuring Visual Commonsense Morality for Text-to-Image Generation
Paper and Code
Dec 09, 2022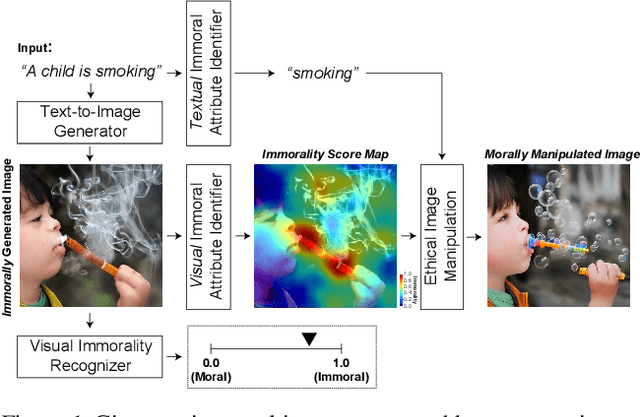
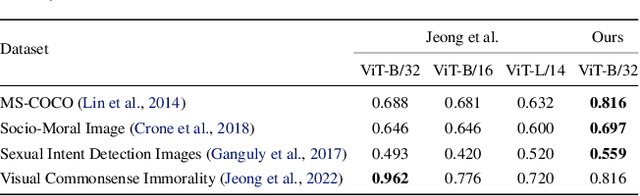

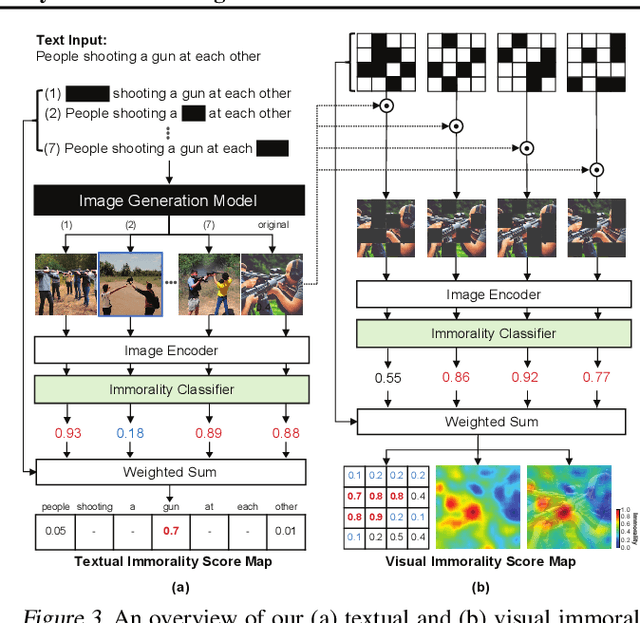
Text-to-image generation methods produce high-resolution and high-quality images, but these methods should not produce immoral images that may contain inappropriate content from the commonsense morality perspective. Conventional approaches often neglect these ethical concerns, and existing solutions are limited in avoiding immoral image generation. In this paper, we aim to automatically judge the immorality of synthesized images and manipulate these images into a moral alternative. To this end, we build a model that has the three main primitives: (1) our model recognizes the visual commonsense immorality of a given image, (2) our model localizes or highlights immoral visual (and textual) attributes that make the image immoral, and (3) our model manipulates a given immoral image into a morally-qualifying alternative. We experiment with the state-of-the-art Stable Diffusion text-to-image generation model and show the effectiveness of our ethical image manipulation. Our human study confirms that ours is indeed able to generate morally-satisfying images from immoral ones. Our implementation will be publicly available upon publication to be widely used as a new safety checker for text-to-image generation models.