 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToo Many Frames, not all Useful:Efficient Strategies for Long-Form Video QA
Jun 17, 2024



Long-form videos that span across wide temporal intervals are highly information redundant and contain multiple distinct events or entities that are often loosely-related. Therefore, when performing long-form video question answering (LVQA),all information necessary to generate a correct response can often be contained within a small subset of frames. Recent literature explore the use of large language models (LLMs) in LVQA benchmarks, achieving exceptional performance, while relying on vision language models (VLMs) to convert all visual content within videos into natural language. Such VLMs often independently caption a large number of frames uniformly sampled from long videos, which is not efficient and can mostly be redundant. Questioning these decision choices, we explore optimal strategies for key-frame selection and sequence-aware captioning, that can significantly reduce these redundancies. We propose two novel approaches that improve each of aspects, namely Hierarchical Keyframe Selector and Sequential Visual LLM. Our resulting framework termed LVNet achieves state-of-the-art performance across three benchmark LVQA datasets. Our code will be released publicly.
The Power of Sound : Audio Reactive Video Generation with Stable Diffusion
Sep 08, 2023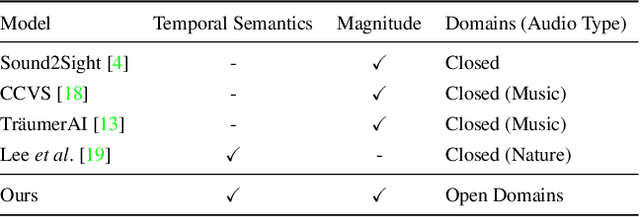


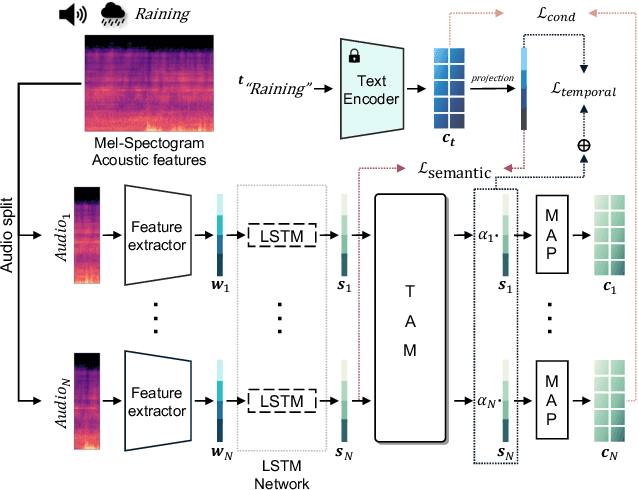
In recent years, video generation has become a prominent generative tool and has drawn significant attention. However, there is little consideration in audio-to-video generation, though audio contains unique qualities like temporal semantics and magnitude. Hence, we propose The Power of Sound (TPoS) model to incorporate audio input that includes both changeable temporal semantics and magnitude. To generate video frames, TPoS utilizes a latent stable diffusion model with textual semantic information, which is then guided by the sequential audio embedding from our pretrained Audio Encoder. As a result, this method produces audio reactive video contents. We demonstrate the effectiveness of TPoS across various tasks and compare its results with current state-of-the-art techniques in the field of audio-to-video generation. More examples are available at https://ku-vai.github.io/TPoS/
Event Fusion Photometric Stereo Network
Mar 11, 2023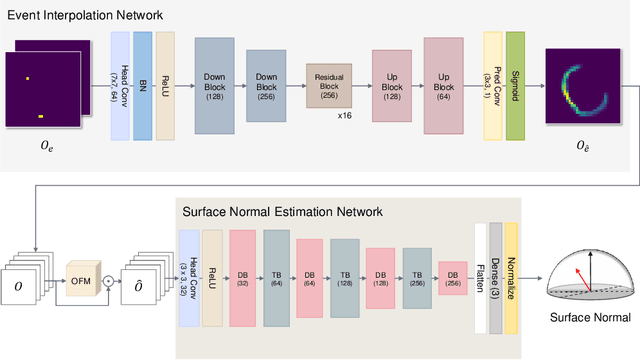
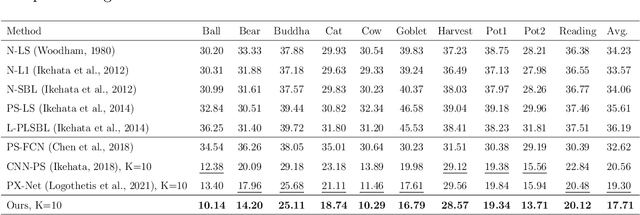
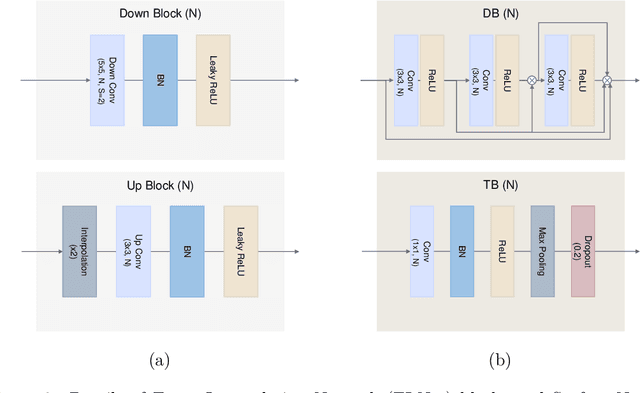
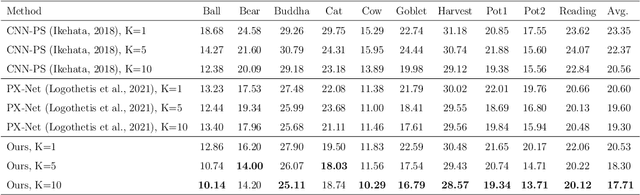
We present a novel method to estimate the surface normal of an object in an ambient light environment using RGB and event cameras. Modern photometric stereo methods rely on an RGB camera, mainly in a dark room, to avoid ambient illumination. To alleviate the limitations of the darkroom environment and to use essential light information, we employ an event camera with a high dynamic range and low latency. This is the first study that uses an event camera for the photometric stereo task, which works on continuous light sources and ambient light environment. In this work, we also curate a novel photometric stereo dataset that is constructed by capturing objects with event and RGB cameras under numerous ambient lights environment. Additionally, we propose a novel framework named Event Fusion Photometric Stereo Network~(EFPS-Net), which estimates the surface normals of an object using both RGB frames and event signals. Our proposed method interpolates event observation maps that generate light information with sparse event signals to acquire fluent light information. Subsequently, the event-interpolated observation maps are fused with the RGB observation maps. Our numerous experiments showed that EFPS-Net outperforms state-of-the-art methods on a dataset captured in the real world where ambient lights exist. Consequently, we demonstrate that incorporating additional modalities with EFPS-Net alleviates the limitations that occurred from ambient illumination.