 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCS-UQ: Uncertainty Quantification via the Predictability-Computability-Stability Framework
May 13, 2025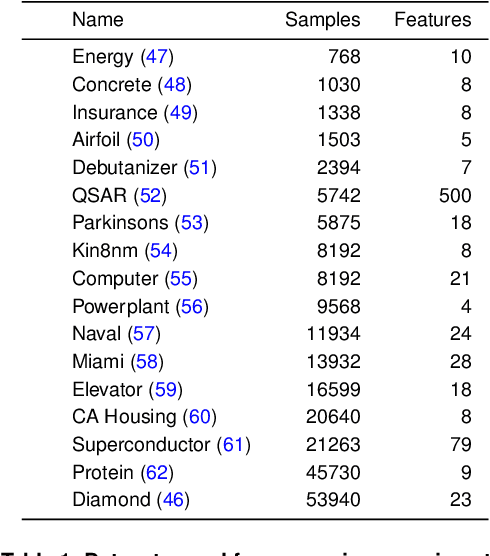
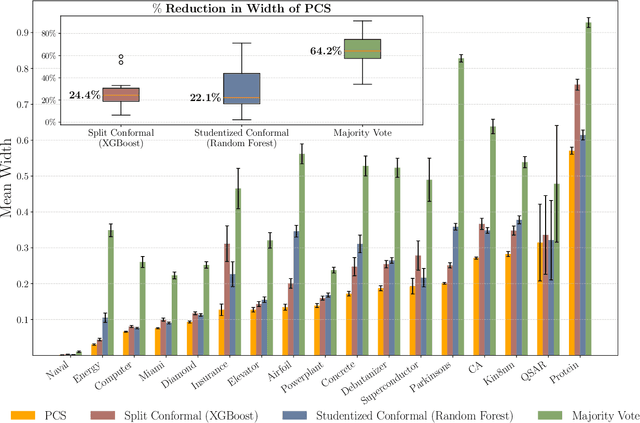
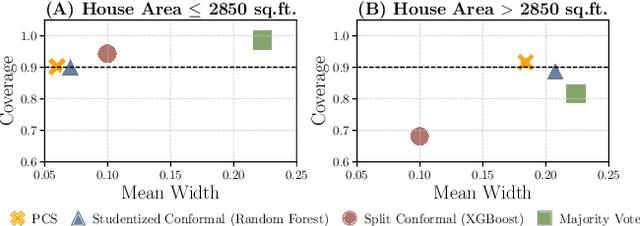
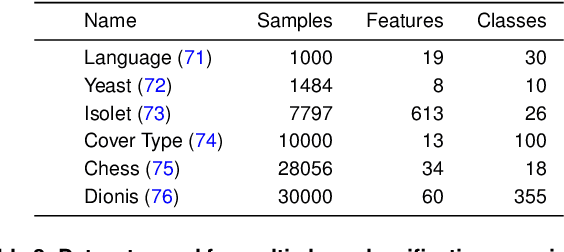
As machine learning (ML) models are increasingly deployed in high-stakes domains, trustworthy uncertainty quantification (UQ) is critical for ensuring the safety and reliability of these models. Traditional UQ methods rely on specifying a true generative model and are not robust to misspecification. On the other hand, conformal inference allows for arbitrary ML models but does not consider model selection, which leads to large interval sizes. We tackle these drawbacks by proposing a UQ method based on the predictability, computability, and stability (PCS) framework for veridical data science proposed by Yu and Kumbier. Specifically, PCS-UQ addresses model selection by using a prediction check to screen out unsuitable models. PCS-UQ then fits these screened algorithms across multiple bootstraps to assess inter-sample variability and algorithmic instability, enabling more reliable uncertainty estimates. Further, we propose a novel calibration scheme that improves local adaptivity of our prediction sets. Experiments across $17$ regression and $6$ classification datasets show that PCS-UQ achieves the desired coverage and reduces width over conformal approaches by $\approx 20\%$. Further, our local analysis shows PCS-UQ often achieves target coverage across subgroups while conformal methods fail to do so. For large deep-learning models, we propose computationally efficient approximation schemes that avoid the expensive multiple bootstrap trainings of PCS-UQ. Across three computer vision benchmarks, PCS-UQ reduces prediction set size over conformal methods by $20\%$. Theoretically, we show a modified PCS-UQ algorithm is a form of split conformal inference and achieves the desired coverage with exchangeable data.
The Computational Curse of Big Data for Bayesian Additive Regression Trees: A Hitting Time Analysis
Jun 28, 2024

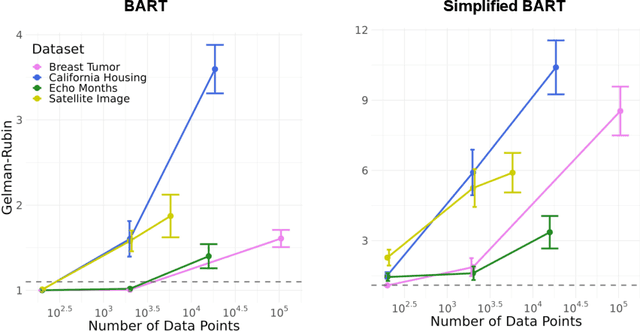
Bayesian Additive Regression Trees (BART) is a popular Bayesian non-parametric regression model that is commonly used in causal inference and beyond. Its strong predictive performance is supported by theoretical guarantees that its posterior distribution concentrates around the true regression function at optimal rates under various data generative settings and for appropriate prior choices. In this paper, we show that the BART sampler often converges slowly, confirming empirical observations by other researchers. Assuming discrete covariates, we show that, while the BART posterior concentrates on a set comprising all optimal tree structures (smallest bias and complexity), the Markov chain's hitting time for this set increases with $n$ (training sample size), under several common data generative settings. As $n$ increases, the approximate BART posterior thus becomes increasingly different from the exact posterior (for the same number of MCMC samples), contrasting with earlier concentration results on the exact posterior. This contrast is highlighted by our simulations showing worsening frequentist undercoverage for approximate posterior intervals and a growing ratio between the MSE of the approximate posterior and that obtainable by artificially improving convergence via averaging multiple sampler chains. Finally, based on our theoretical insights, possibilities are discussed to improve the BART sampler convergence performance.
ScaLES: Scalable Latent Exploration Score for Pre-Trained Generative Networks
Jun 14, 2024



We develop Scalable Latent Exploration Score (ScaLES) to mitigate over-exploration in Latent Space Optimization (LSO), a popular method for solving black-box discrete optimization problems. LSO utilizes continuous optimization within the latent space of a Variational Autoencoder (VAE) and is known to be susceptible to over-exploration, which manifests in unrealistic solutions that reduce its practicality. ScaLES is an exact and theoretically motivated method leveraging the trained decoder's approximation of the data distribution. ScaLES can be calculated with any existing decoder, e.g. from a VAE, without additional training, architectural changes, or access to the training data. Our evaluation across five LSO benchmark tasks and three VAE architectures demonstrates that ScaLES enhances the quality of the solutions while maintaining high objective values, leading to improvements over existing solutions. We believe that new avenues to LSO will be opened by ScaLES ability to identify out of distribution areas, differentiability, and computational tractability. Open source code for ScaLES is available at https://github.com/OmerRonen/scales.
A Mixing Time Lower Bound for a Simplified Version of BART
Oct 17, 2022

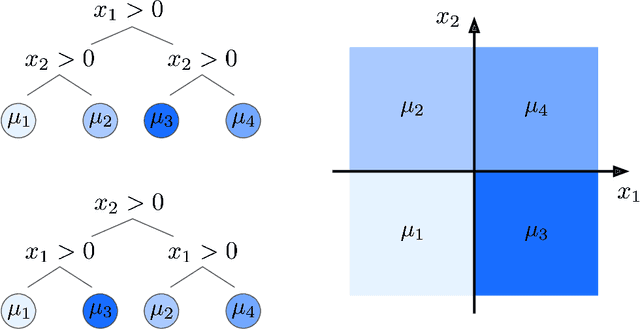
Bayesian Additive Regression Trees (BART) is a popular Bayesian non-parametric regression algorithm. The posterior is a distribution over sums of decision trees, and predictions are made by averaging approximate samples from the posterior. The combination of strong predictive performance and the ability to provide uncertainty measures has led BART to be commonly used in the social sciences, biostatistics, and causal inference. BART uses Markov Chain Monte Carlo (MCMC) to obtain approximate posterior samples over a parameterized space of sums of trees, but it has often been observed that the chains are slow to mix. In this paper, we provide the first lower bound on the mixing time for a simplified version of BART in which we reduce the sum to a single tree and use a subset of the possible moves for the MCMC proposal distribution. Our lower bound for the mixing time grows exponentially with the number of data points. Inspired by this new connection between the mixing time and the number of data points, we perform rigorous simulations on BART. We show qualitatively that BART's mixing time increases with the number of data points. The slow mixing time of the simplified BART suggests a large variation between different runs of the simplified BART algorithm and a similar large variation is known for BART in the literature. This large variation could result in a lack of stability in the models, predictions, and posterior intervals obtained from the BART MCMC samples. Our lower bound and simulations suggest increasing the number of chains with the number of data points.
Hierarchical Shrinkage: improving the accuracy and interpretability of tree-based methods
Feb 02, 2022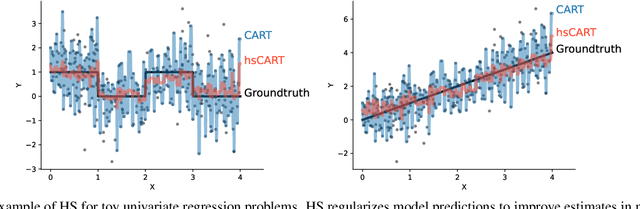
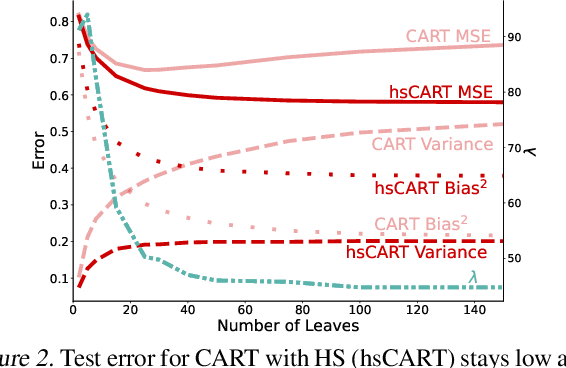
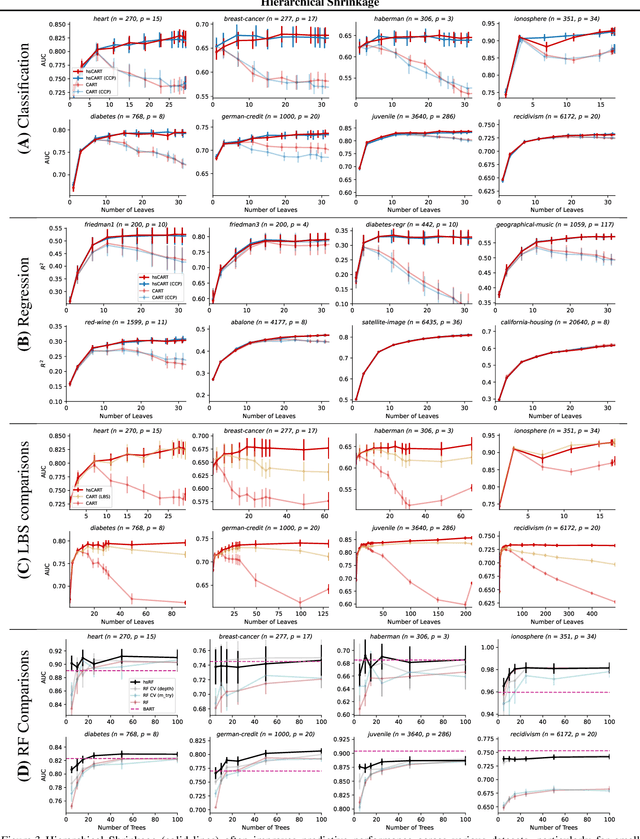
Tree-based models such as decision trees and random forests (RF) are a cornerstone of modern machine-learning practice. To mitigate overfitting, trees are typically regularized by a variety of techniques that modify their structure (e.g. pruning). We introduce Hierarchical Shrinkage (HS), a post-hoc algorithm that does not modify the tree structure, and instead regularizes the tree by shrinking the prediction over each node towards the sample means of its ancestors. The amount of shrinkage is controlled by a single regularization parameter and the number of data points in each ancestor. Since HS is a post-hoc method, it is extremely fast, compatible with any tree growing algorithm, and can be used synergistically with other regularization techniques. Extensive experiments over a wide variety of real-world datasets show that HS substantially increases the predictive performance of decision trees, even when used in conjunction with other regularization techniques. Moreover, we find that applying HS to each tree in an RF often improves accuracy, as well as its interpretability by simplifying and stabilizing its decision boundaries and SHAP values. We further explain the success of HS in improving prediction performance by showing its equivalence to ridge regression on a (supervised) basis constructed of decision stumps associated with the internal nodes of a tree. All code and models are released in a full-fledged package available on Github (github.com/csinva/imodels)