 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCS-UQ: Uncertainty Quantification via the Predictability-Computability-Stability Framework
May 13, 2025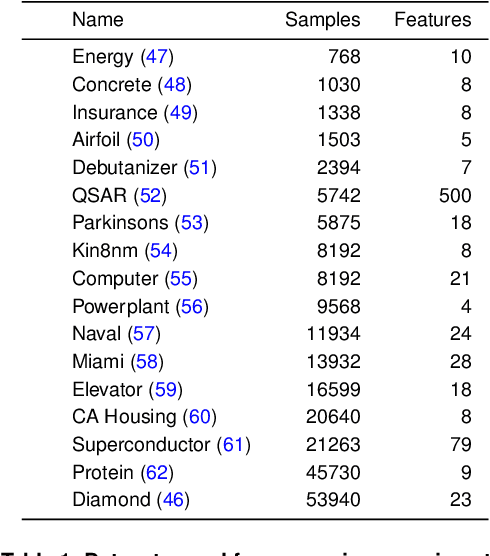
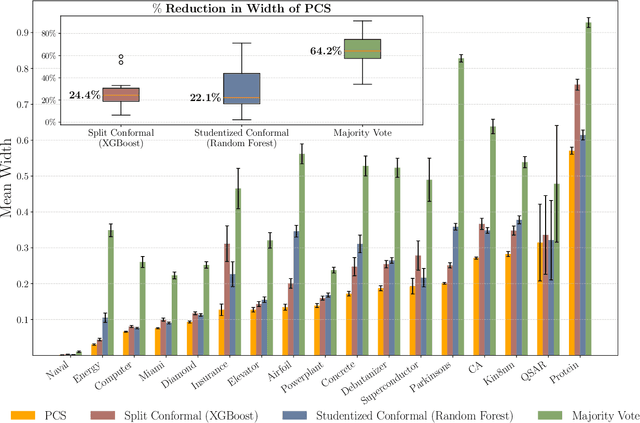
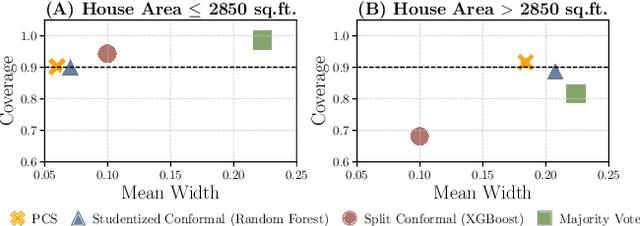
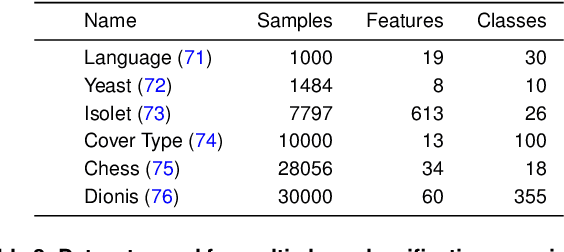
As machine learning (ML) models are increasingly deployed in high-stakes domains, trustworthy uncertainty quantification (UQ) is critical for ensuring the safety and reliability of these models. Traditional UQ methods rely on specifying a true generative model and are not robust to misspecification. On the other hand, conformal inference allows for arbitrary ML models but does not consider model selection, which leads to large interval sizes. We tackle these drawbacks by proposing a UQ method based on the predictability, computability, and stability (PCS) framework for veridical data science proposed by Yu and Kumbier. Specifically, PCS-UQ addresses model selection by using a prediction check to screen out unsuitable models. PCS-UQ then fits these screened algorithms across multiple bootstraps to assess inter-sample variability and algorithmic instability, enabling more reliable uncertainty estimates. Further, we propose a novel calibration scheme that improves local adaptivity of our prediction sets. Experiments across $17$ regression and $6$ classification datasets show that PCS-UQ achieves the desired coverage and reduces width over conformal approaches by $\approx 20\%$. Further, our local analysis shows PCS-UQ often achieves target coverage across subgroups while conformal methods fail to do so. For large deep-learning models, we propose computationally efficient approximation schemes that avoid the expensive multiple bootstrap trainings of PCS-UQ. Across three computer vision benchmarks, PCS-UQ reduces prediction set size over conformal methods by $20\%$. Theoretically, we show a modified PCS-UQ algorithm is a form of split conformal inference and achieves the desired coverage with exchangeable data.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
FedTSA: A Cluster-based Two-Stage Aggregation Method for Model-heterogeneous Federated Learning
Jul 06, 2024Despite extensive research into data heterogeneity in federated learning (FL), system heterogeneity remains a significant yet often overlooked challenge. Traditional FL approaches typically assume homogeneous hardware resources across FL clients, implying that clients can train a global model within a comparable time. However, in practical FL systems, clients often have heterogeneous resources, which impacts their capacity for training tasks. This discrepancy highlights the significance of exploring model-heterogeneous FL, a paradigm that allows clients to train different models based on their resource capabilities. To address this, we introduce FedTSA, a cluster-based two-stage aggregation method tailored for system heterogeneity in FL. FedTSA starts by clustering clients based on their capabilities, then conducts a two-stage aggregation, i.e., conventional weight averaging for homogeneous models as Stage 1, and deep mutual learning with a diffusion model for aggregating heterogeneous models as Stage 2. Extensive experiments not only show that FedTSA outperforms the baselines, but also explore various factors influencing model performance, thereby validating FedTSA as a promising approach for model-heterogeneous FL.