 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedTSA: A Cluster-based Two-Stage Aggregation Method for Model-heterogeneous Federated Learning
Jul 06, 2024Despite extensive research into data heterogeneity in federated learning (FL), system heterogeneity remains a significant yet often overlooked challenge. Traditional FL approaches typically assume homogeneous hardware resources across FL clients, implying that clients can train a global model within a comparable time. However, in practical FL systems, clients often have heterogeneous resources, which impacts their capacity for training tasks. This discrepancy highlights the significance of exploring model-heterogeneous FL, a paradigm that allows clients to train different models based on their resource capabilities. To address this, we introduce FedTSA, a cluster-based two-stage aggregation method tailored for system heterogeneity in FL. FedTSA starts by clustering clients based on their capabilities, then conducts a two-stage aggregation, i.e., conventional weight averaging for homogeneous models as Stage 1, and deep mutual learning with a diffusion model for aggregating heterogeneous models as Stage 2. Extensive experiments not only show that FedTSA outperforms the baselines, but also explore various factors influencing model performance, thereby validating FedTSA as a promising approach for model-heterogeneous FL.
Multi-level Personalized Federated Learning on Heterogeneous and Long-Tailed Data
May 10, 2024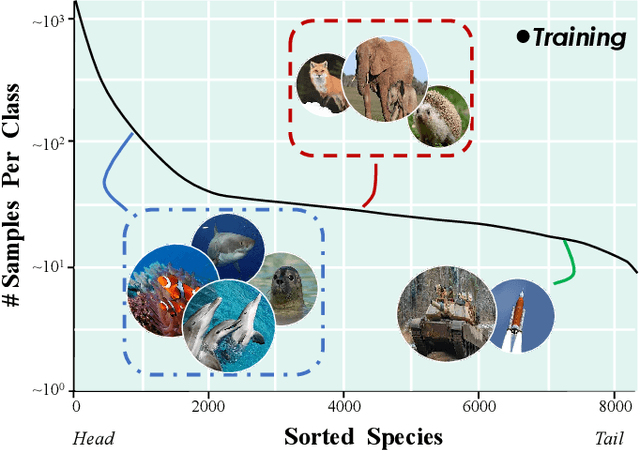

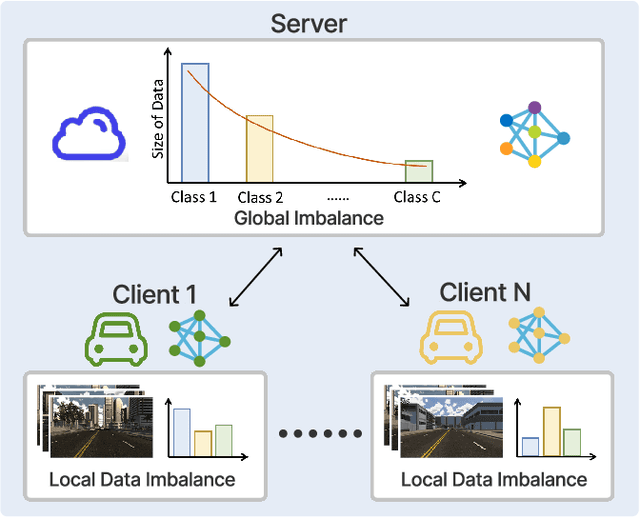

Federated learning (FL) offers a privacy-centric distributed learning framework, enabling model training on individual clients and central aggregation without necessitating data exchange. Nonetheless, FL implementations often suffer from non-i.i.d. and long-tailed class distributions across mobile applications, e.g., autonomous vehicles, which leads models to overfitting as local training may converge to sub-optimal. In our study, we explore the impact of data heterogeneity on model bias and introduce an innovative personalized FL framework, Multi-level Personalized Federated Learning (MuPFL), which leverages the hierarchical architecture of FL to fully harness computational resources at various levels. This framework integrates three pivotal modules: Biased Activation Value Dropout (BAVD) to mitigate overfitting and accelerate training; Adaptive Cluster-based Model Update (ACMU) to refine local models ensuring coherent global aggregation; and Prior Knowledge-assisted Classifier Fine-tuning (PKCF) to bolster classification and personalize models in accord with skewed local data with shared knowledge. Extensive experiments on diverse real-world datasets for image classification and semantic segmentation validate that MuPFL consistently outperforms state-of-the-art baselines, even under extreme non-i.i.d. and long-tail conditions, which enhances accuracy by as much as 7.39% and accelerates training by up to 80% at most, marking significant advancements in both efficiency and effectiveness.
Learning Cautiously in Federated Learning with Noisy and Heterogeneous Clients
Apr 06, 2023Federated learning (FL) is a distributed framework for collaboratively training with privacy guarantees. In real-world scenarios, clients may have Non-IID data (local class imbalance) with poor annotation quality (label noise). The co-existence of label noise and class imbalance in FL's small local datasets renders conventional FL methods and noisy-label learning methods both ineffective. To address the challenges, we propose FedCNI without using an additional clean proxy dataset. It includes a noise-resilient local solver and a robust global aggregator. For the local solver, we design a more robust prototypical noise detector to distinguish noisy samples. Further to reduce the negative impact brought by the noisy samples, we devise a curriculum pseudo labeling method and a denoise Mixup training strategy. For the global aggregator, we propose a switching re-weighted aggregation method tailored to different learning periods. Extensive experiments demonstrate our method can substantially outperform state-of-the-art solutions in mix-heterogeneous FL environments.