 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-AI Co-design for Clinical Prediction Models
Jan 14, 2026Developing safe, effective, and practically useful clinical prediction models (CPMs) traditionally requires iterative collaboration between clinical experts, data scientists, and informaticists. This process refines the often small but critical details of the model building process, such as which features/patients to include and how clinical categories should be defined. However, this traditional collaboration process is extremely time- and resource-intensive, resulting in only a small fraction of CPMs reaching clinical practice. This challenge intensifies when teams attempt to incorporate unstructured clinical notes, which can contain an enormous number of concepts. To address this challenge, we introduce HACHI, an iterative human-in-the-loop framework that uses AI agents to accelerate the development of fully interpretable CPMs by enabling the exploration of concepts in clinical notes. HACHI alternates between (i) an AI agent rapidly exploring and evaluating candidate concepts in clinical notes and (ii) clinical and domain experts providing feedback to improve the CPM learning process. HACHI defines concepts as simple yes-no questions that are used in linear models, allowing the clinical AI team to transparently review, refine, and validate the CPM learned in each round. In two real-world prediction tasks (acute kidney injury and traumatic brain injury), HACHI outperforms existing approaches, surfaces new clinically relevant concepts not included in commonly-used CPMs, and improves model generalizability across clinical sites and time periods. Furthermore, HACHI reveals the critical role of the clinical AI team, such as directing the AI agent to explore concepts that it had not previously considered, adjusting the granularity of concepts it considers, changing the objective function to better align with the clinical objectives, and identifying issues of data bias and leakage.
When the Domain Expert Has No Time and the LLM Developer Has No Clinical Expertise: Real-World Lessons from LLM Co-Design in a Safety-Net Hospital
Aug 11, 2025Large language models (LLMs) have the potential to address social and behavioral determinants of health by transforming labor intensive workflows in resource-constrained settings. Creating LLM-based applications that serve the needs of underserved communities requires a deep understanding of their local context, but it is often the case that neither LLMs nor their developers possess this local expertise, and the experts in these communities often face severe time/resource constraints. This creates a disconnect: how can one engage in meaningful co-design of an LLM-based application for an under-resourced community when the communication channel between the LLM developer and domain expert is constrained? We explored this question through a real-world case study, in which our data science team sought to partner with social workers at a safety net hospital to build an LLM application that summarizes patients' social needs. Whereas prior works focus on the challenge of prompt tuning, we found that the most critical challenge in this setting is the careful and precise specification of \what information to surface to providers so that the LLM application is accurate, comprehensive, and verifiable. Here we present a novel co-design framework for settings with limited access to domain experts, in which the summary generation task is first decomposed into individually-optimizable attributes and then each attribute is efficiently refined and validated through a multi-tier cascading approach.
Bayesian Concept Bottleneck Models with LLM Priors
Oct 21, 2024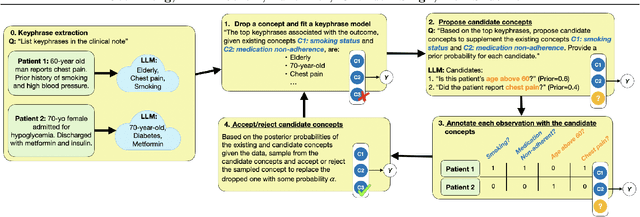
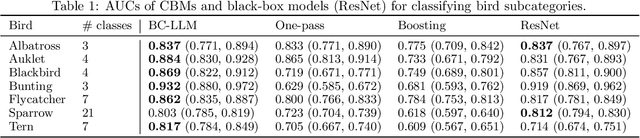
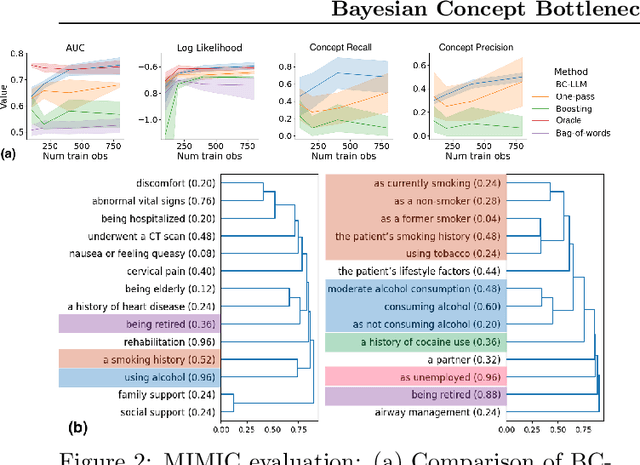
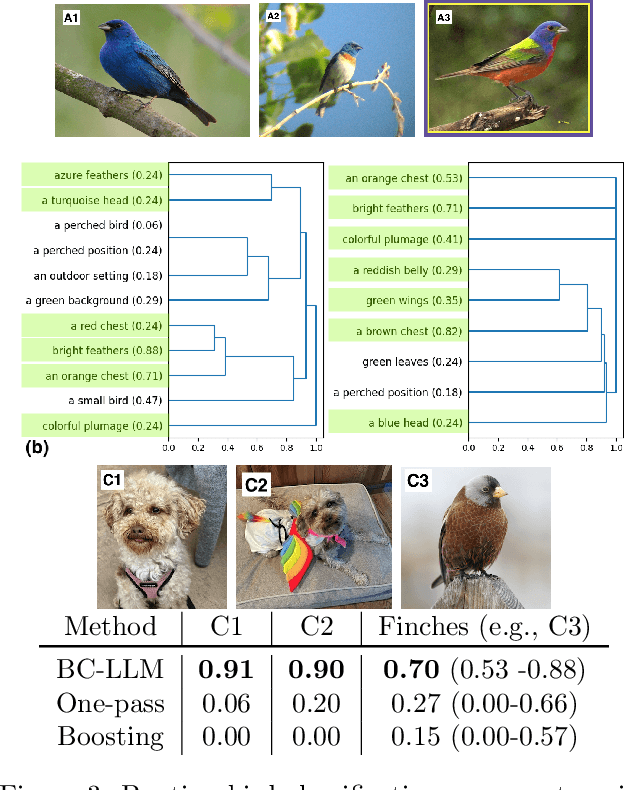
Concept Bottleneck Models (CBMs) have been proposed as a compromise between white-box and black-box models, aiming to achieve interpretability without sacrificing accuracy. The standard training procedure for CBMs is to predefine a candidate set of human-interpretable concepts, extract their values from the training data, and identify a sparse subset as inputs to a transparent prediction model. However, such approaches are often hampered by the tradeoff between enumerating a sufficiently large set of concepts to include those that are truly relevant versus controlling the cost of obtaining concept extractions. This work investigates a novel approach that sidesteps these challenges: BC-LLM iteratively searches over a potentially infinite set of concepts within a Bayesian framework, in which Large Language Models (LLMs) serve as both a concept extraction mechanism and prior. BC-LLM is broadly applicable and multi-modal. Despite imperfections in LLMs, we prove that BC-LLM can provide rigorous statistical inference and uncertainty quantification. In experiments, it outperforms comparator methods including black-box models, converges more rapidly towards relevant concepts and away from spuriously correlated ones, and is more robust to out-of-distribution samples.
Prediction without Preclusion: Recourse Verification with Reachable Sets
Aug 24, 2023



Machine learning models are often used to decide who will receive a loan, a job interview, or a public benefit. Standard techniques to build these models use features about people but overlook their actionability. In turn, models can assign predictions that are fixed, meaning that consumers who are denied loans, interviews, or benefits may be permanently locked out from access to credit, employment, or assistance. In this work, we introduce a formal testing procedure to flag models that assign fixed predictions that we call recourse verification. We develop machinery to reliably determine if a given model can provide recourse to its decision subjects from a set of user-specified actionability constraints. We demonstrate how our tools can ensure recourse and adversarial robustness in real-world datasets and use them to study the infeasibility of recourse in real-world lending datasets. Our results highlight how models can inadvertently assign fixed predictions that permanently bar access, and we provide tools to design algorithms that account for actionability when developing models.