 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Algorithms for Robust Markov Decision Processes with $s$-Rectangular Ambiguity Sets
Feb 05, 2026Robust Markov decision processes (MDPs) have attracted significant interest due to their ability to protect MDPs from poor out-of-sample performance in the presence of ambiguity. In contrast to classical MDPs, which account for stochasticity by modeling the dynamics through a stochastic process with a known transition kernel, a robust MDP additionally accounts for ambiguity by optimizing against the most adverse transition kernel from an ambiguity set constructed via historical data. In this paper, we develop a unified solution framework for a broad class of robust MDPs with $s$-rectangular ambiguity sets, where the most adverse transition probabilities are considered independently for each state. Using our algorithms, we show that $s$-rectangular robust MDPs with $1$- and $2$-norm as well as $φ$-divergence ambiguity sets can be solved several orders of magnitude faster than with state-of-the-art commercial solvers, and often only a logarithmic factor slower than classical MDPs. We demonstrate the favorable scaling properties of our algorithms on a range of synthetically generated as well as standard benchmark instances.
Probabilistic Safety Guarantee for Stochastic Control Systems Using Average Reward MDPs
Nov 11, 2025



Safety in stochastic control systems, which are subject to random noise with a known probability distribution, aims to compute policies that satisfy predefined operational constraints with high confidence throughout the uncertain evolution of the state variables. The unpredictable evolution of state variables poses a significant challenge for meeting predefined constraints using various control methods. To address this, we present a new algorithm that computes safe policies to determine the safety level across a finite state set. This algorithm reduces the safety objective to the standard average reward Markov Decision Process (MDP) objective. This reduction enables us to use standard techniques, such as linear programs, to compute and analyze safe policies. We validate the proposed method numerically on the Double Integrator and the Inverted Pendulum systems. Results indicate that the average-reward MDPs solution is more comprehensive, converges faster, and offers higher quality compared to the minimum discounted-reward solution.
Q-learning for Quantile MDPs: A Decomposition, Performance, and Convergence Analysis
Oct 31, 2024



In Markov decision processes (MDPs), quantile risk measures such as Value-at-Risk are a standard metric for modeling RL agents' preferences for certain outcomes. This paper proposes a new Q-learning algorithm for quantile optimization in MDPs with strong convergence and performance guarantees. The algorithm leverages a new, simple dynamic program (DP) decomposition for quantile MDPs. Compared with prior work, our DP decomposition requires neither known transition probabilities nor solving complex saddle point equations and serves as a suitable foundation for other model-free RL algorithms. Our numerical results in tabular domains show that our Q-learning algorithm converges to its DP variant and outperforms earlier algorithms.
Stationary Policies are Optimal in Risk-averse Total-reward MDPs with EVaR
Aug 30, 2024Optimizing risk-averse objectives in discounted MDPs is challenging because most models do not admit direct dynamic programming equations and require complex history-dependent policies. In this paper, we show that the risk-averse {\em total reward criterion}, under the Entropic Risk Measure (ERM) and Entropic Value at Risk (EVaR) risk measures, can be optimized by a stationary policy, making it simple to analyze, interpret, and deploy. We propose exponential value iteration, policy iteration, and linear programming to compute optimal policies. In comparison with prior work, our results only require the relatively mild condition of transient MDPs and allow for {\em both} positive and negative rewards. Our results indicate that the total reward criterion may be preferable to the discounted criterion in a broad range of risk-averse reinforcement learning domains.
Solving Multi-Model MDPs by Coordinate Ascent and Dynamic Programming
Jul 08, 2024Multi-model Markov decision process (MMDP) is a promising framework for computing policies that are robust to parameter uncertainty in MDPs. MMDPs aim to find a policy that maximizes the expected return over a distribution of MDP models. Because MMDPs are NP-hard to solve, most methods resort to approximations. In this paper, we derive the policy gradient of MMDPs and propose CADP, which combines a coordinate ascent method and a dynamic programming algorithm for solving MMDPs. The main innovation of CADP compared with earlier algorithms is to take the coordinate ascent perspective to adjust model weights iteratively to guarantee monotone policy improvements to a local maximum. A theoretical analysis of CADP proves that it never performs worse than previous dynamic programming algorithms like WSU. Our numerical results indicate that CADP substantially outperforms existing methods on several benchmark problems.
Percentile Criterion Optimization in Offline Reinforcement Learning
Apr 07, 2024



In reinforcement learning, robust policies for high-stakes decision-making problems with limited data are usually computed by optimizing the \emph{percentile criterion}. The percentile criterion is approximately solved by constructing an \emph{ambiguity set} that contains the true model with high probability and optimizing the policy for the worst model in the set. Since the percentile criterion is non-convex, constructing ambiguity sets is often challenging. Existing work uses \emph{Bayesian credible regions} as ambiguity sets, but they are often unnecessarily large and result in learning overly conservative policies. To overcome these shortcomings, we propose a novel Value-at-Risk based dynamic programming algorithm to optimize the percentile criterion without explicitly constructing any ambiguity sets. Our theoretical and empirical results show that our algorithm implicitly constructs much smaller ambiguity sets and learns less conservative robust policies.
Data Poisoning Attacks on Off-Policy Policy Evaluation Methods
Apr 06, 2024Off-policy Evaluation (OPE) methods are a crucial tool for evaluating policies in high-stakes domains such as healthcare, where exploration is often infeasible, unethical, or expensive. However, the extent to which such methods can be trusted under adversarial threats to data quality is largely unexplored. In this work, we make the first attempt at investigating the sensitivity of OPE methods to marginal adversarial perturbations to the data. We design a generic data poisoning attack framework leveraging influence functions from robust statistics to carefully construct perturbations that maximize error in the policy value estimates. We carry out extensive experimentation with multiple healthcare and control datasets. Our results demonstrate that many existing OPE methods are highly prone to generating value estimates with large errors when subject to data poisoning attacks, even for small adversarial perturbations. These findings question the reliability of policy values derived using OPE methods and motivate the need for developing OPE methods that are statistically robust to train-time data poisoning attacks.
A Convex Relaxation Approach to Bayesian Regret Minimization in Offline Bandits
Jun 02, 2023



Algorithms for offline bandits must optimize decisions in uncertain environments using only offline data. A compelling and increasingly popular objective in offline bandits is to learn a policy which achieves low Bayesian regret with high confidence. An appealing approach to this problem, inspired by recent offline reinforcement learning results, is to maximize a form of lower confidence bound (LCB). This paper proposes a new approach that directly minimizes upper bounds on Bayesian regret using efficient conic optimization solvers. Our bounds build on connections among Bayesian regret, Value-at-Risk (VaR), and chance-constrained optimization. Compared to prior work, our algorithm attains superior theoretical offline regret bounds and better results in numerical simulations. Finally, we provide some evidence that popular LCB-style algorithms may be unsuitable for minimizing Bayesian regret in offline bandits.
On Dynamic Program Decompositions of Static Risk Measures
Apr 24, 2023Optimizing static risk-averse objectives in Markov decision processes is challenging because they do not readily admit dynamic programming decompositions. Prior work has proposed to use a dynamic decomposition of risk measures that help to formulate dynamic programs on an augmented state space. This paper shows that several existing decompositions are inherently inexact, contradicting several claims in the literature. In particular, we give examples that show that popular decompositions for CVaR and EVaR risk measures are strict overestimates of the true risk values. However, an exact decomposition is possible for VaR, and we give a simple proof that illustrates the fundamental difference between VaR and CVaR dynamic programming properties.
Reducing Blackwell and Average Optimality to Discounted MDPs via the Blackwell Discount Factor
Jan 31, 2023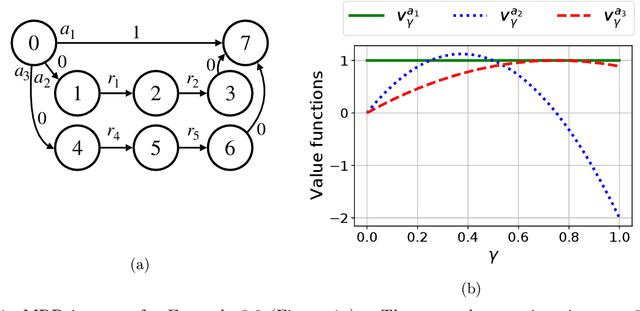

We introduce the Blackwell discount factor for Markov Decision Processes (MDPs). Classical objectives for MDPs include discounted, average, and Blackwell optimality. Many existing approaches to computing average-optimal policies solve for discounted optimal policies with a discount factor close to $1$, but they only work under strong or hard-to-verify assumptions such as ergodicity or weakly communicating MDPs. In this paper, we show that when the discount factor is larger than the Blackwell discount factor $\gamma_{\mathrm{bw}}$, all discounted optimal policies become Blackwell- and average-optimal, and we derive a general upper bound on $\gamma_{\mathrm{bw}}$. The upper bound on $\gamma_{\mathrm{bw}}$ provides the first reduction from average and Blackwell optimality to discounted optimality, without any assumptions, and new polynomial-time algorithms for average- and Blackwell-optimal policies. Our work brings new ideas from the study of polynomials and algebraic numbers to the analysis of MDPs. Our results also apply to robust MDPs, enabling the first algorithms to compute robust Blackwell-optimal policies.