 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the convex formulations of robust Markov decision processes
Paper and Code
Sep 21, 2022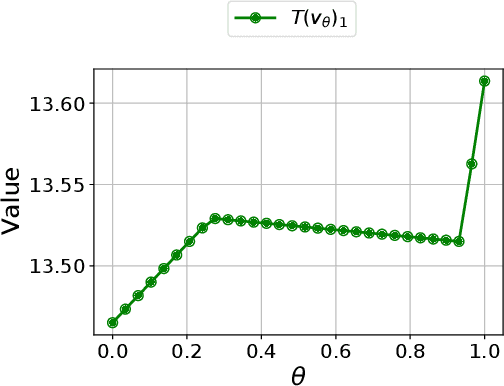

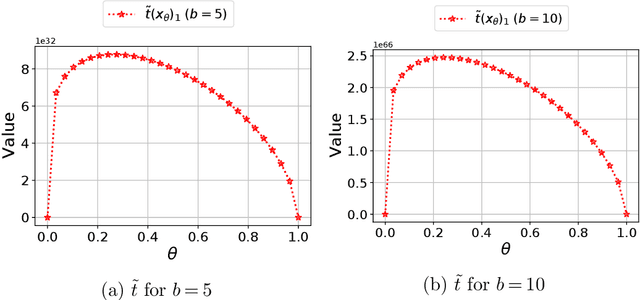

Robust Markov decision processes (MDPs) are used for applications of dynamic optimization in uncertain environments and have been studied extensively. Many of the main properties and algorithms of MDPs, such as value iteration and policy iteration, extend directly to RMDPs. Surprisingly, there is no known analog of the MDP convex optimization formulation for solving RMDPs. This work describes the first convex optimization formulation of RMDPs under the classical sa-rectangularity and s-rectangularity assumptions. We derive a convex formulation with a linear number of variables and constraints but large coefficients in the constraints by using entropic regularization and exponential change of variables. Our formulation can be combined with efficient methods from convex optimization to obtain new algorithms for solving RMDPs with uncertain probabilities. We further simplify the formulation for RMDPs with polyhedral uncertainty sets. Our work opens a new research direction for RMDPs and can serve as a first step toward obtaining a tractable convex formulation of RMDPs.