 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Disparities in Post Hoc Machine Learning Explanation
Paper and Code
Jan 25, 2024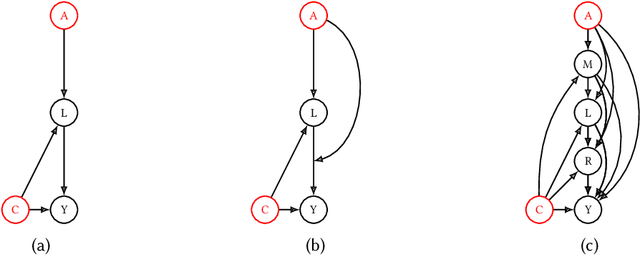
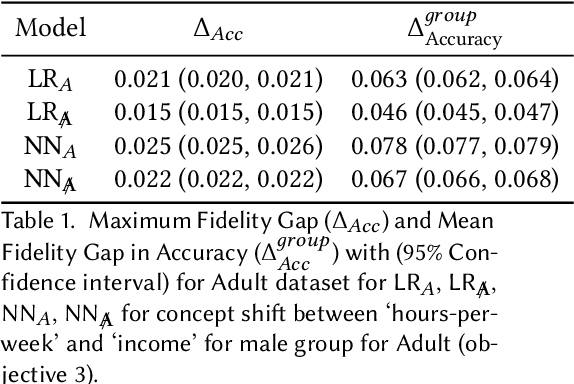
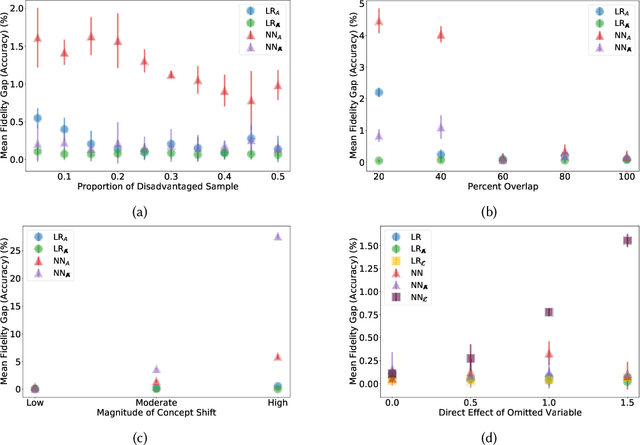
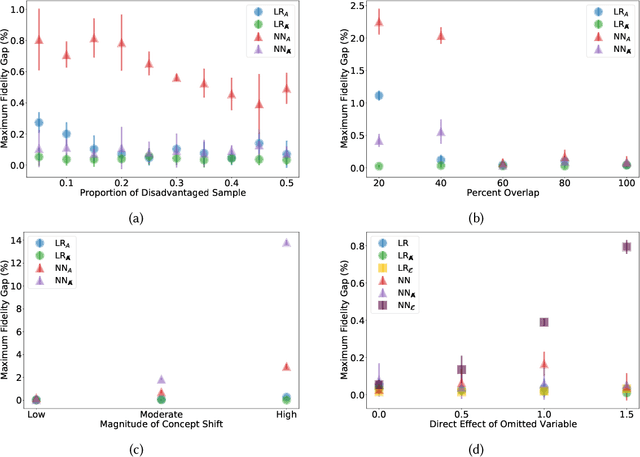
Previous work has highlighted that existing post-hoc explanation methods exhibit disparities in explanation fidelity (across 'race' and 'gender' as sensitive attributes), and while a large body of work focuses on mitigating these issues at the explanation metric level, the role of the data generating process and black box model in relation to explanation disparities remains largely unexplored. Accordingly, through both simulations as well as experiments on a real-world dataset, we specifically assess challenges to explanation disparities that originate from properties of the data: limited sample size, covariate shift, concept shift, omitted variable bias, and challenges based on model properties: inclusion of the sensitive attribute and appropriate functional form. Through controlled simulation analyses, our study demonstrates that increased covariate shift, concept shift, and omission of covariates increase explanation disparities, with the effect pronounced higher for neural network models that are better able to capture the underlying functional form in comparison to linear models. We also observe consistent findings regarding the effect of concept shift and omitted variable bias on explanation disparities in the Adult income dataset. Overall, results indicate that disparities in model explanations can also depend on data and model properties. Based on this systematic investigation, we provide recommendations for the design of explanation methods that mitigate undesirable disparities.