 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Spatiotemporal Occupancy Grid Maps for Lifelong Navigation in Dynamic Scenes
Paper and Code
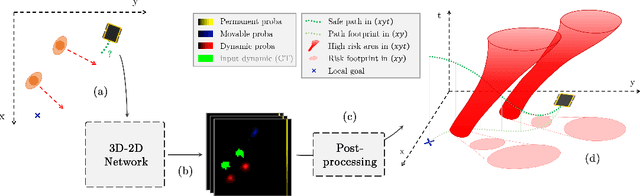
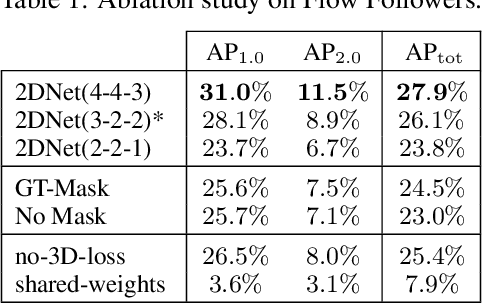
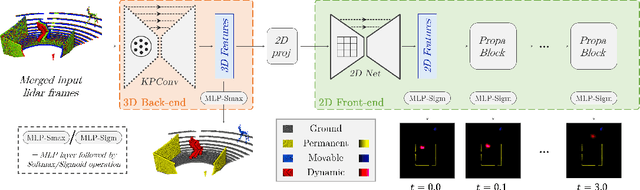

We present a novel method for generating, predicting, and using Spatiotemporal Occupancy Grid Maps (SOGM), which embed future information of dynamic scenes. Our automated generation process creates groundtruth SOGMs from previous navigation data. We use them to train a 3D-2D feedforward architecture, in a self-supervised fashion, thus enabling lifelong learning for robots. The automated generation process uses ray-tracing to label points in the robot environment based on their dynamic properties. The network is composed of a 3D back-end that extracts rich features and enables the semantic segmentation of the lidar frames, and a 2D front-end that predicts the future information embedded in the SOGMs. We also design a navigation pipeline using these predicted SOGMs. We provide both quantitative and qualitative insights into the predictions and validate our choices of network design with an ablation study.