 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Foreseeable Future: Self-Supervised Learning to Predict Dynamic Scenes for Indoor Navigation
Paper and Code

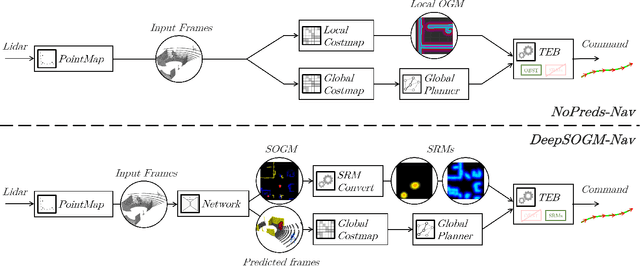
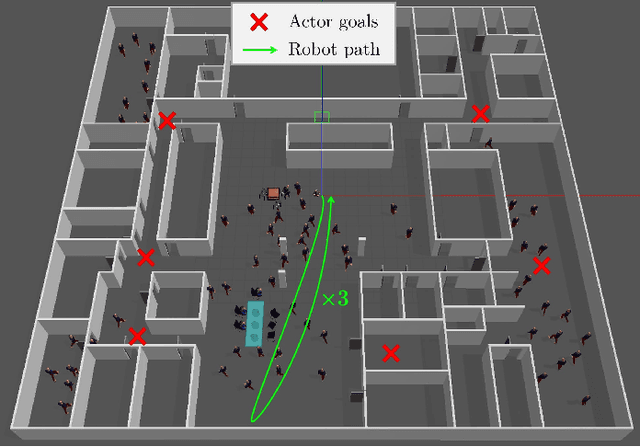
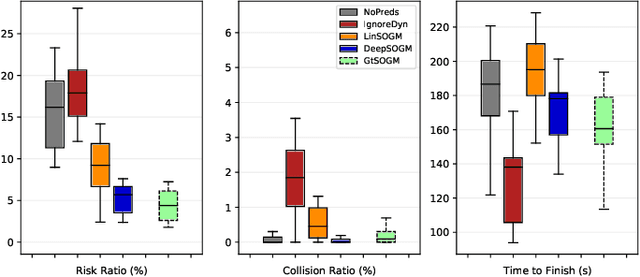
We present a method for generating, predicting, and using Spatiotemporal Occupancy Grid Maps (SOGM), which embed future semantic information of real dynamic scenes. We present an auto-labeling process that creates SOGMs from noisy real navigation data. We use a 3D-2D feedforward architecture, trained to predict the future time steps of SOGMs, given 3D lidar frames as input. Our pipeline is entirely self-supervised, thus enabling lifelong learning for real robots. The network is composed of a 3D back-end that extracts rich features and enables the semantic segmentation of the lidar frames, and a 2D front-end that predicts the future information embedded in the SOGM representation, potentially capturing the complexities and uncertainties of real-world multi-agent, multi-future interactions. We also design a navigation system that uses these predicted SOGMs within planning, after they have been transformed into Spatiotemporal Risk Maps (SRMs). We verify our navigation system's abilities in simulation, validate it on a real robot, study SOGM predictions on real data in various circumstances, and provide a novel indoor 3D lidar dataset, collected during our experiments, which includes our automated annotations.