 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-domain Semi-Supervised Audio Event Classification Using Contrastive Regularization
Sep 29, 2021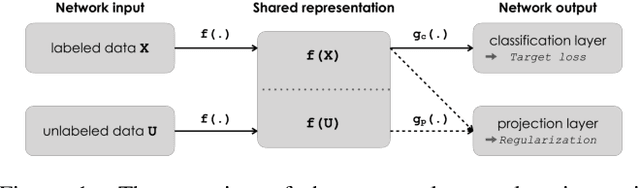
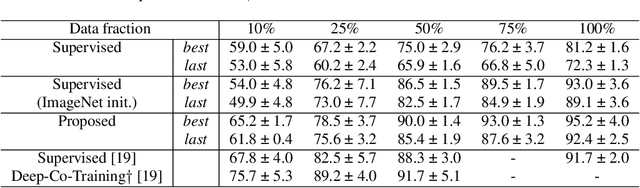
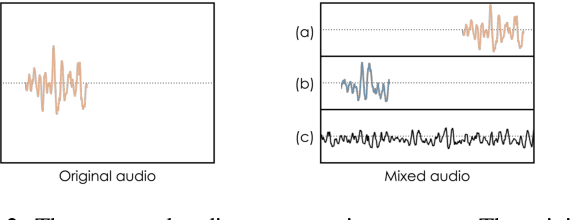
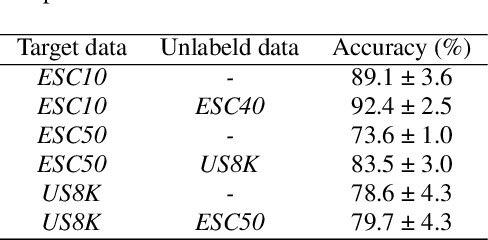
In this study, we proposed a novel semi-supervised training method that uses unlabeled data with a class distribution that is completely different from the target data or data without a target label. To this end, we introduce a contrastive regularization that is designed to be target task-oriented and trained simultaneously. In addition, we propose an audio mixing based simple augmentation strategy that performed in batch samples. Experimental results validate that the proposed method successfully contributed to the performance improvement, and particularly showed that it has advantages in stable training and generalization.
Room adaptive conditioning method for sound event classification in reverberant environments
Apr 21, 2021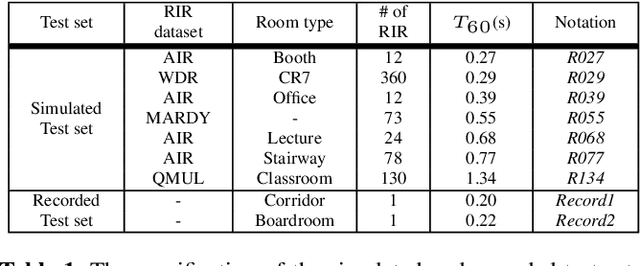
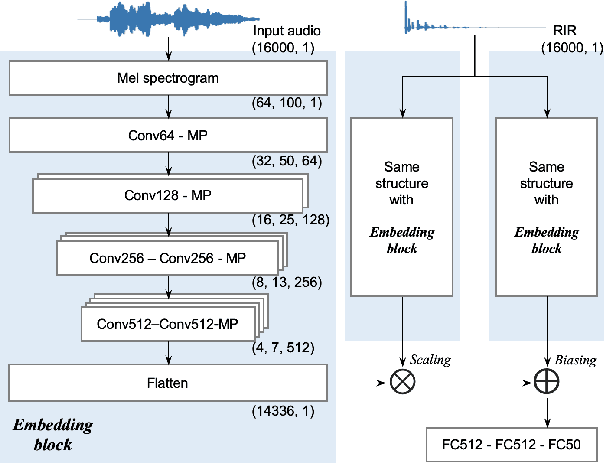
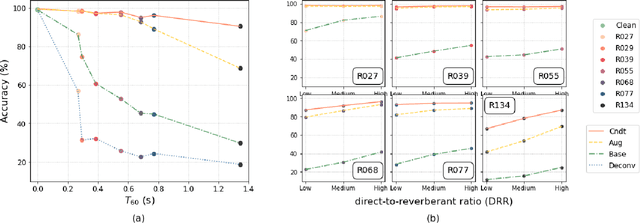
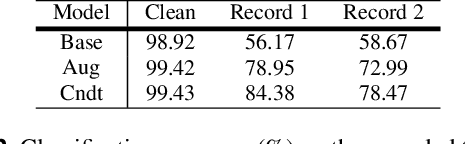
Ensuring performance robustness for a variety of situations that can occur in real-world environments is one of the challenging tasks in sound event classification. One of the unpredictable and detrimental factors in performance, especially in indoor environments, is reverberation. To alleviate this problem, we propose a conditioning method that provides room impulse response (RIR) information to help the network become less sensitive to environmental information and focus on classifying the desired sound. Experimental results show that the proposed method successfully reduced performance degradation caused by the reverberation of the room. In particular, our proposed method works even with similar RIR that can be inferred from the room type rather than the exact one, which has the advantage of potentially being used in real-world applications.
Neural Audio Fingerprint for High-specific Audio Retrieval based on Contrastive Learning
Oct 28, 2020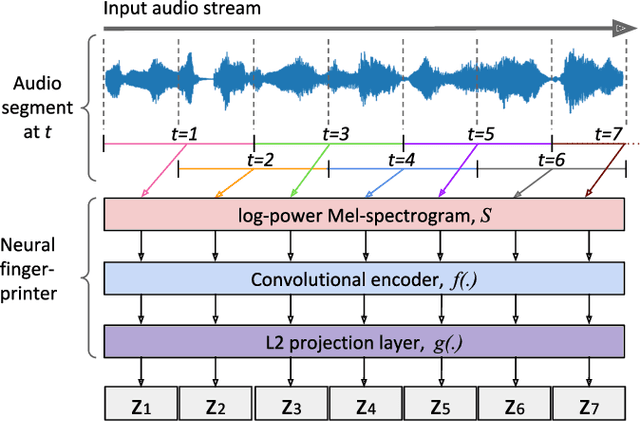

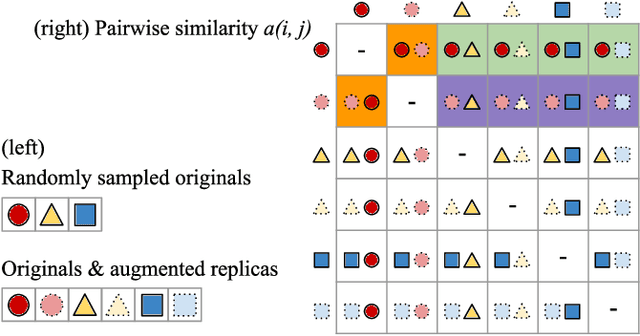
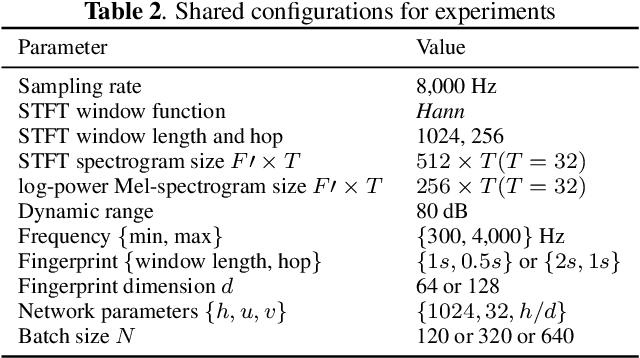
Most of existing audio fingerprinting systems have limitations to be used for high-specific audio retrieval at scale. In this work, we generate a low-dimensional representation from a short unit segment of audio, and couple this fingerprint with a fast maximum inner-product search. To this end, we present a contrastive learning framework that derives from the segment-level search objective. Each update in training uses a batch consisting of a set of pseudo labels, randomly selected original samples, and their augmented replicas. These replicas can simulate the degrading effects on original audio signals by applying small time offsets and various types of distortions, such as background noise and room/microphone impulse responses. In the segment-level search task, where the conventional audio fingerprinting systems used to fail, our system using 10x smaller storage has shown promising results. Our code and dataset will be available.