 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunity Forensics: Using Thousands of Generators to Train Fake Image Detectors
Nov 06, 2024One of the key challenges of detecting AI-generated images is spotting images that have been created by previously unseen generative models. We argue that the limited diversity of the training data is a major obstacle to addressing this problem, and we propose a new dataset that is significantly larger and more diverse than prior work. As part of creating this dataset, we systematically download thousands of text-to-image latent diffusion models and sample images from them. We also collect images from dozens of popular open source and commercial models. The resulting dataset contains 2.7M images that have been sampled from 4803 different models. These images collectively capture a wide range of scene content, generator architectures, and image processing settings. Using this dataset, we study the generalization abilities of fake image detectors. Our experiments suggest that detection performance improves as the number of models in the training set increases, even when these models have similar architectures. We also find that detection performance improves as the diversity of the models increases, and that our trained detectors generalize better than those trained on other datasets.
Learning Semantic Traversability with Egocentric Video and Automated Annotation Strategy
Jun 05, 2024For reliable autonomous robot navigation in urban settings, the robot must have the ability to identify semantically traversable terrains in the image based on the semantic understanding of the scene. This reasoning ability is based on semantic traversability, which is frequently achieved using semantic segmentation models fine-tuned on the testing domain. This fine-tuning process often involves manual data collection with the target robot and annotation by human labelers which is prohibitively expensive and unscalable. In this work, we present an effective methodology for training a semantic traversability estimator using egocentric videos and an automated annotation process. Egocentric videos are collected from a camera mounted on a pedestrian's chest. The dataset for training the semantic traversability estimator is then automatically generated by extracting semantically traversable regions in each video frame using a recent foundation model in image segmentation and its prompting technique. Extensive experiments with videos taken across several countries and cities, covering diverse urban scenarios, demonstrate the high scalability and generalizability of the proposed annotation method. Furthermore, performance analysis and real-world deployment for autonomous robot navigation showcase that the trained semantic traversability estimator is highly accurate, able to handle diverse camera viewpoints, computationally light, and real-world applicable. The summary video is available at https://youtu.be/EUVoH-wA-lA.
Cross-domain Sound Recognition for Efficient Underwater Data Analysis
Sep 07, 2023



This paper presents a novel deep learning approach for analyzing massive underwater acoustic data by leveraging a model trained on a broad spectrum of non-underwater (aerial) sounds. Recognizing the challenge in labeling vast amounts of underwater data, we propose a two-fold methodology to accelerate this labor-intensive procedure. The first part of our approach involves PCA and UMAP visualization of the underwater data using the feature vectors of an aerial sound recognition model. This enables us to cluster the data in a two dimensional space and listen to points within these clusters to understand their defining characteristics. This innovative method simplifies the process of selecting candidate labels for further training. In the second part, we train a neural network model using both the selected underwater data and the non-underwater dataset. We conducted a quantitative analysis to measure the precision, recall, and F1 score of our model for recognizing airgun sounds, a common type of underwater sound. The F1 score achieved by our model exceeded 84.3%, demonstrating the effectiveness of our approach in analyzing underwater acoustic data. The methodology presented in this paper holds significant potential to reduce the amount of labor required in underwater data analysis and opens up new possibilities for further research in the field of cross-domain data analysis.
RGB no more: Minimally-decoded JPEG Vision Transformers
Nov 29, 2022
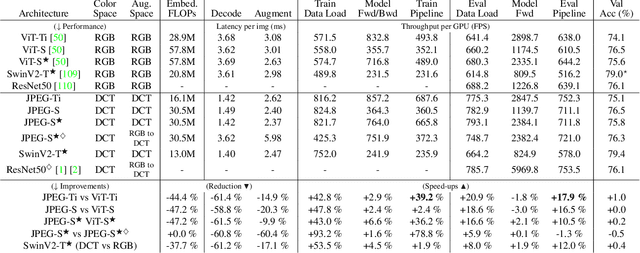
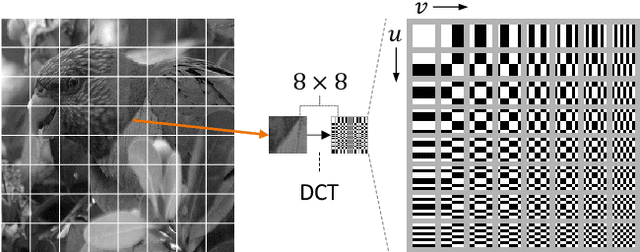
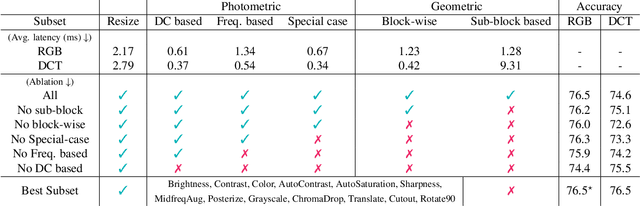
Most neural networks for computer vision are designed to infer using RGB images. However, these RGB images are commonly encoded in JPEG before saving to disk; decoding them imposes an unavoidable overhead for RGB networks. Instead, our work focuses on training Vision Transformers (ViT) directly from the encoded features of JPEG. This way, we can avoid most of the decoding overhead, accelerating data load. Existing works have studied this aspect but they focus on CNNs. Due to how these encoded features are structured, CNNs require heavy modification to their architecture to accept such data. Here, we show that this is not the case for ViTs. In addition, we tackle data augmentation directly on these encoded features, which to our knowledge, has not been explored in-depth for training in this setting. With these two improvements -- ViT and data augmentation -- we show that our ViT-Ti model achieves up to 39.2% faster training and 17.9% faster inference with no accuracy loss compared to the RGB counterpart.
CochlScene: Acquisition of acoustic scene data using crowdsourcing
Nov 04, 2022
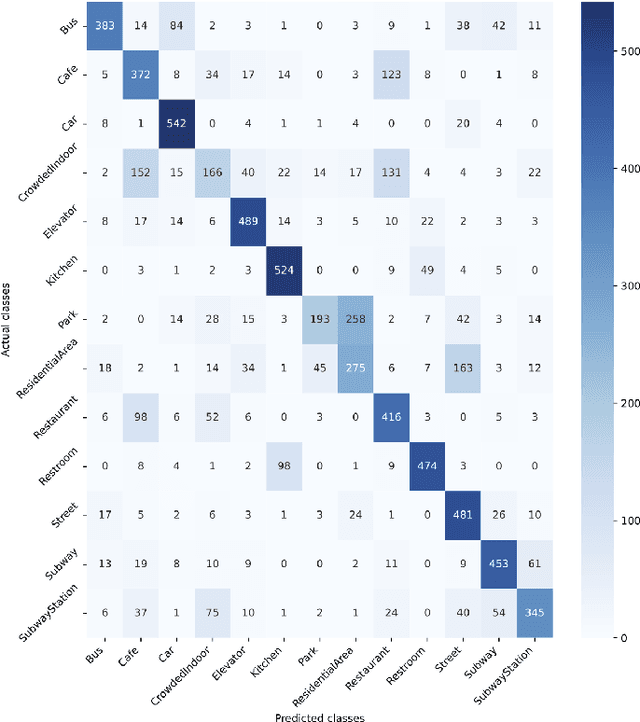
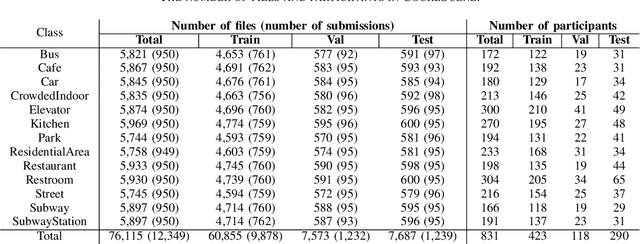

This paper describes a pipeline for collecting acoustic scene data by using crowdsourcing. The detailed process of crowdsourcing is explained, including planning, validation criteria, and actual user interfaces. As a result of data collection, we present CochlScene, a novel dataset for acoustic scene classification. Our dataset consists of 76k samples collected from 831 participants in 13 acoustic scenes. We also propose a manual data split of training, validation, and test sets to increase the reliability of the evaluation results. Finally, we provide a baseline system for future research.
Neural Audio Fingerprint for High-specific Audio Retrieval based on Contrastive Learning
Oct 28, 2020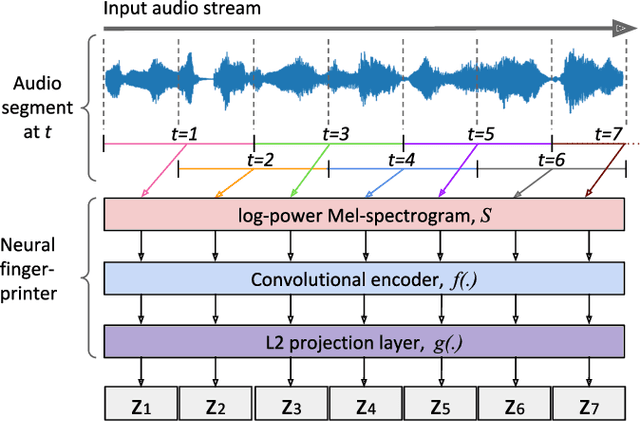

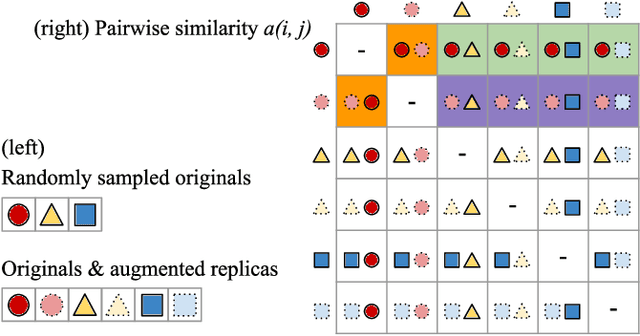
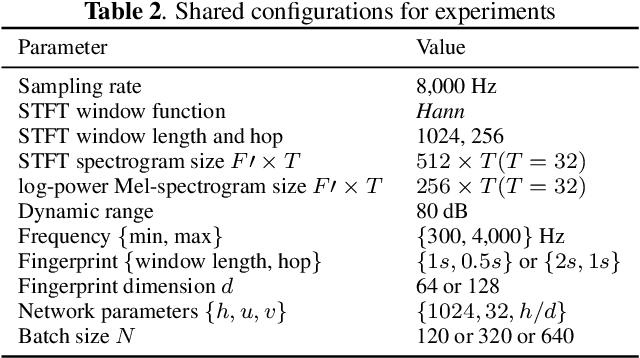
Most of existing audio fingerprinting systems have limitations to be used for high-specific audio retrieval at scale. In this work, we generate a low-dimensional representation from a short unit segment of audio, and couple this fingerprint with a fast maximum inner-product search. To this end, we present a contrastive learning framework that derives from the segment-level search objective. Each update in training uses a batch consisting of a set of pseudo labels, randomly selected original samples, and their augmented replicas. These replicas can simulate the degrading effects on original audio signals by applying small time offsets and various types of distortions, such as background noise and room/microphone impulse responses. In the segment-level search task, where the conventional audio fingerprinting systems used to fail, our system using 10x smaller storage has shown promising results. Our code and dataset will be available.