Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCochlScene: Acquisition of acoustic scene data using crowdsourcing
Paper and Code
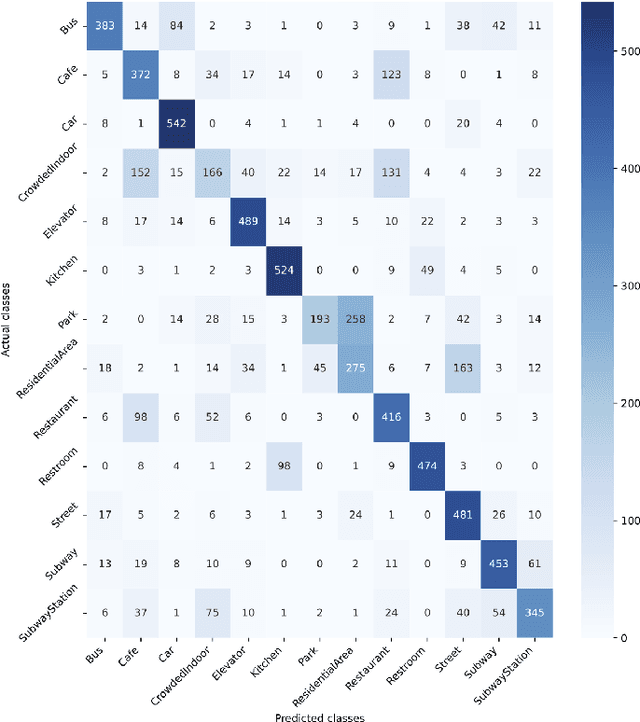
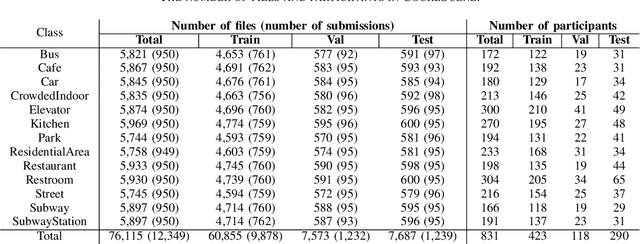

This paper describes a pipeline for collecting acoustic scene data by using crowdsourcing. The detailed process of crowdsourcing is explained, including planning, validation criteria, and actual user interfaces. As a result of data collection, we present CochlScene, a novel dataset for acoustic scene classification. Our dataset consists of 76k samples collected from 831 participants in 13 acoustic scenes. We also propose a manual data split of training, validation, and test sets to increase the reliability of the evaluation results. Finally, we provide a baseline system for future research.
* Accept by APSIPA ASC 2022, 5 pages, 2 figures
View paper on