 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Quadrupedal Locomotion for a Heavy Hydraulic Robot Using an Actuator Model
Jan 16, 2026The simulation-to-reality (sim-to-real) transfer of large-scale hydraulic robots presents a significant challenge in robotics because of the inherent slow control response and complex fluid dynamics. The complex dynamics result from the multiple interconnected cylinder structure and the difference in fluid rates of the cylinders. These characteristics complicate detailed simulation for all joints, making it unsuitable for reinforcement learning (RL) applications. In this work, we propose an analytical actuator model driven by hydraulic dynamics to represent the complicated actuators. The model predicts joint torques for all 12 actuators in under 1 microsecond, allowing rapid processing in RL environments. We compare our model with neural network-based actuator models and demonstrate the advantages of our model in data-limited scenarios. The locomotion policy trained in RL with our model is deployed on a hydraulic quadruped robot, which is over 300 kg. This work is the first demonstration of a successful transfer of stable and robust command-tracking locomotion with RL on a heavy hydraulic quadruped robot, demonstrating advanced sim-to-real transferability.
* 9 pages, Accepted to IEEE Robotics and Automation Letters (RA-L) 2025
Learning Semantic Traversability with Egocentric Video and Automated Annotation Strategy
Jun 05, 2024For reliable autonomous robot navigation in urban settings, the robot must have the ability to identify semantically traversable terrains in the image based on the semantic understanding of the scene. This reasoning ability is based on semantic traversability, which is frequently achieved using semantic segmentation models fine-tuned on the testing domain. This fine-tuning process often involves manual data collection with the target robot and annotation by human labelers which is prohibitively expensive and unscalable. In this work, we present an effective methodology for training a semantic traversability estimator using egocentric videos and an automated annotation process. Egocentric videos are collected from a camera mounted on a pedestrian's chest. The dataset for training the semantic traversability estimator is then automatically generated by extracting semantically traversable regions in each video frame using a recent foundation model in image segmentation and its prompting technique. Extensive experiments with videos taken across several countries and cities, covering diverse urban scenarios, demonstrate the high scalability and generalizability of the proposed annotation method. Furthermore, performance analysis and real-world deployment for autonomous robot navigation showcase that the trained semantic traversability estimator is highly accurate, able to handle diverse camera viewpoints, computationally light, and real-world applicable. The summary video is available at https://youtu.be/EUVoH-wA-lA.
Learning Vehicle Dynamics from Cropped Image Patches for Robot Navigation in Unpaved Outdoor Terrains
Sep 06, 2023

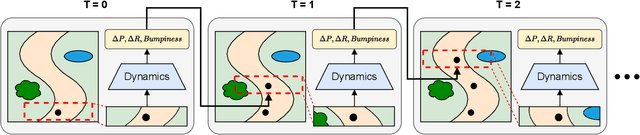

In the realm of autonomous mobile robots, safe navigation through unpaved outdoor environments remains a challenging task. Due to the high-dimensional nature of sensor data, extracting relevant information becomes a complex problem, which hinders adequate perception and path planning. Previous works have shown promising performances in extracting global features from full-sized images. However, they often face challenges in capturing essential local information. In this paper, we propose Crop-LSTM, which iteratively takes cropped image patches around the current robot's position and predicts the future position, orientation, and bumpiness. Our method performs local feature extraction by paying attention to corresponding image patches along the predicted robot trajectory in the 2D image plane. This enables more accurate predictions of the robot's future trajectory. With our wheeled mobile robot platform Raicart, we demonstrated the effectiveness of Crop-LSTM for point-goal navigation in an unpaved outdoor environment. Our method enabled safe and robust navigation using RGBD images in challenging unpaved outdoor terrains. The summary video is available at https://youtu.be/iIGNZ8ignk0.