 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMORPHOS: Autoregressive 4D Generation with Temporal Structured Latents
Jun 01, 2026We present MORPHOS, a novel autoregressive framework that generates dynamic 3D assets from videos across diverse representations, including meshes, 3D Gaussians, and radiance fields. Existing methods are typically limited to a single representation, struggle to model topological changes, or fail to maintain temporal consistency over long videos. To address these limitations, we introduce the Temporal Structured Latents (T-SLAT), a unified 4D representation that jointly encodes geometry and appearance along the temporal dimension. Leveraging T-SLAT, MORPHOS autoregressively generates dynamic 3D assets via causal attention, conditioning each frame on its preceding history to ensure temporal consistency while handling evolving topologies. We also propose a temporal-structural augmentation to mitigate error accumulation in autoregressive generation. MORPHOS achieves state-of-the-art performance in appearance and competitive results in geometry across multiple benchmarks, demonstrating superior generalization across various representations and robustness in long-horizon generation.
Repurposing Geometric Foundation Models for Multi-view Diffusion
Mar 23, 2026While recent advances in generative latent spaces have driven substantial progress in single-image generation, the optimal latent space for novel view synthesis (NVS) remains largely unexplored. In particular, NVS requires geometrically consistent generation across viewpoints, but existing approaches typically operate in a view-independent VAE latent space. In this paper, we propose Geometric Latent Diffusion (GLD), a framework that repurposes the geometrically consistent feature space of geometric foundation models as the latent space for multi-view diffusion. We show that these features not only support high-fidelity RGB reconstruction but also encode strong cross-view geometric correspondences, providing a well-suited latent space for NVS. Our experiments demonstrate that GLD outperforms both VAE and RAE on 2D image quality and 3D consistency metrics, while accelerating training by more than 4.4x compared to the VAE latent space. Notably, GLD remains competitive with state-of-the-art methods that leverage large-scale text-to-image pretraining, despite training its diffusion model from scratch without such generative pretraining.
Grounding World Simulation Models in a Real-World Metropolis
Mar 16, 2026What if a world simulation model could render not an imagined environment but a city that actually exists? Prior generative world models synthesize visually plausible yet artificial environments by imagining all content. We present Seoul World Model (SWM), a city-scale world model grounded in the real city of Seoul. SWM anchors autoregressive video generation through retrieval-augmented conditioning on nearby street-view images. However, this design introduces several challenges, including temporal misalignment between retrieved references and the dynamic target scene, limited trajectory diversity and data sparsity from vehicle-mounted captures at sparse intervals. We address these challenges through cross-temporal pairing, a large-scale synthetic dataset enabling diverse camera trajectories, and a view interpolation pipeline that synthesizes coherent training videos from sparse street-view images. We further introduce a Virtual Lookahead Sink to stabilize long-horizon generation by continuously re-grounding each chunk to a retrieved image at a future location. We evaluate SWM against recent video world models across three cities: Seoul, Busan, and Ann Arbor. SWM outperforms existing methods in generating spatially faithful, temporally consistent, long-horizon videos grounded in actual urban environments over trajectories reaching hundreds of meters, while supporting diverse camera movements and text-prompted scenario variations.
Projected Representation Conditioning for High-fidelity Novel View Synthesis
Feb 12, 2026We propose a novel framework for diffusion-based novel view synthesis in which we leverage external representations as conditions, harnessing their geometric and semantic correspondence properties for enhanced geometric consistency in generated novel viewpoints. First, we provide a detailed analysis exploring the correspondence capabilities emergent in the spatial attention of external visual representations. Building from these insights, we propose a representation-guided novel view synthesis through dedicated representation projection modules that inject external representations into the diffusion process, a methodology named ReNoV, short for representation-guided novel view synthesis. Our experiments show that this design yields marked improvements in both reconstruction fidelity and inpainting quality, outperforming prior diffusion-based novel-view methods on standard benchmarks and enabling robust synthesis from sparse, unposed image collections.
APPLE: Attribute-Preserving Pseudo-Labeling for Diffusion-Based Face Swapping
Jan 21, 2026Face swapping aims to transfer the identity of a source face onto a target face while preserving target-specific attributes such as pose, expression, lighting, skin tone, and makeup. However, since real ground truth for face swapping is unavailable, achieving both accurate identity transfer and high-quality attribute preservation remains challenging. In addition, recent diffusion-based approaches attempt to improve visual fidelity through conditional inpainting on masked target images, but the masked condition removes crucial appearance cues of target, resulting in plausible yet misaligned attributes. To address these limitations, we propose APPLE (Attribute-Preserving Pseudo-Labeling), a diffusion-based teacher-student framework that enhances attribute fidelity through attribute-aware pseudo-label supervision. We reformulate face swapping as a conditional deblurring task to more faithfully preserve target-specific attributes such as lighting, skin tone, and makeup. In addition, we introduce an attribute-aware inversion scheme to further improve detailed attribute preservation. Through an elaborate attribute-preserving design for teacher learning, APPLE produces high-quality pseudo triplets that explicitly provide the student with direct face-swapping supervision. Overall, APPLE achieves state-of-the-art performance in terms of attribute preservation and identity transfer, producing more photorealistic and target-faithful results.
Unveiling the Threat of Fraud Gangs to Graph Neural Networks: Multi-Target Graph Injection Attacks against GNN-Based Fraud Detectors
Dec 24, 2024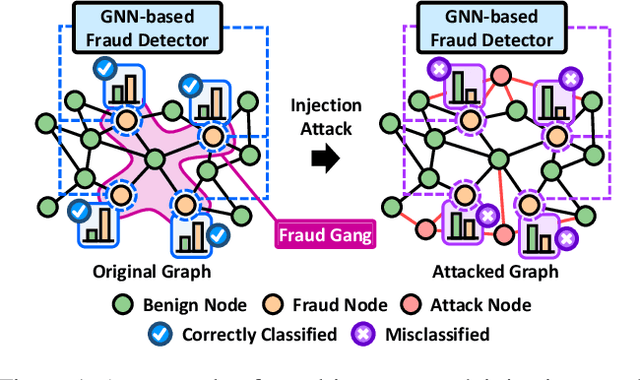

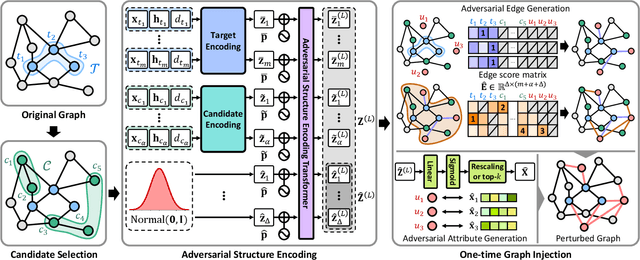

Graph neural networks (GNNs) have emerged as an effective tool for fraud detection, identifying fraudulent users, and uncovering malicious behaviors. However, attacks against GNN-based fraud detectors and their risks have rarely been studied, thereby leaving potential threats unaddressed. Recent findings suggest that frauds are increasingly organized as gangs or groups. In this work, we design attack scenarios where fraud gangs aim to make their fraud nodes misclassified as benign by camouflaging their illicit activities in collusion. Based on these scenarios, we study adversarial attacks against GNN-based fraud detectors by simulating attacks of fraud gangs in three real-world fraud cases: spam reviews, fake news, and medical insurance frauds. We define these attacks as multi-target graph injection attacks and propose MonTi, a transformer-based Multi-target one-Time graph injection attack model. MonTi simultaneously generates attributes and edges of all attack nodes with a transformer encoder, capturing interdependencies between attributes and edges more effectively than most existing graph injection attack methods that generate these elements sequentially. Additionally, MonTi adaptively allocates the degree budget for each attack node to explore diverse injection structures involving target, candidate, and attack nodes, unlike existing methods that fix the degree budget across all attack nodes. Experiments show that MonTi outperforms the state-of-the-art graph injection attack methods on five real-world graphs.
SpoT-Mamba: Learning Long-Range Dependency on Spatio-Temporal Graphs with Selective State Spaces
Jun 17, 2024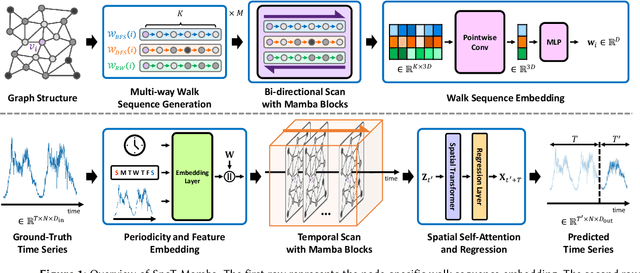

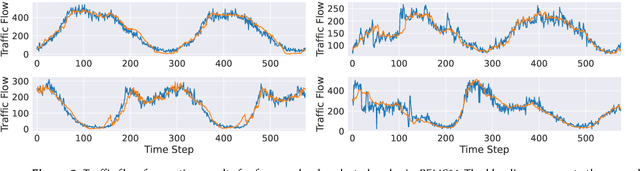
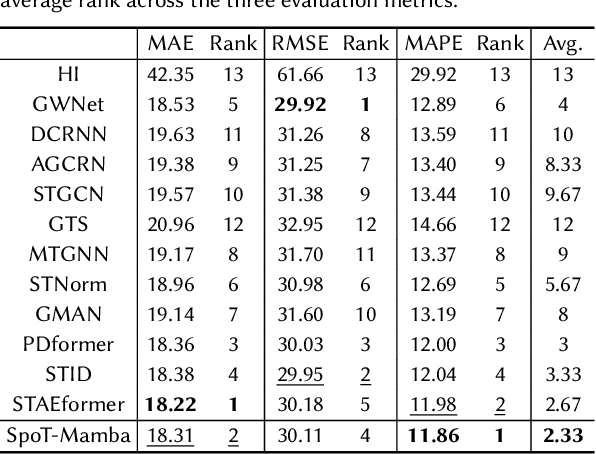
Spatio-temporal graph (STG) forecasting is a critical task with extensive applications in the real world, including traffic and weather forecasting. Although several recent methods have been proposed to model complex dynamics in STGs, addressing long-range spatio-temporal dependencies remains a significant challenge, leading to limited performance gains. Inspired by a recently proposed state space model named Mamba, which has shown remarkable capability of capturing long-range dependency, we propose a new STG forecasting framework named SpoT-Mamba. SpoT-Mamba generates node embeddings by scanning various node-specific walk sequences. Based on the node embeddings, it conducts temporal scans to capture long-range spatio-temporal dependencies. Experimental results on the real-world traffic forecasting dataset demonstrate the effectiveness of SpoT-Mamba.
Dynamic Relation-Attentive Graph Neural Networks for Fraud Detection
Oct 09, 2023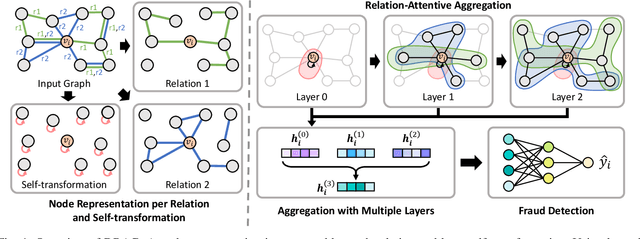
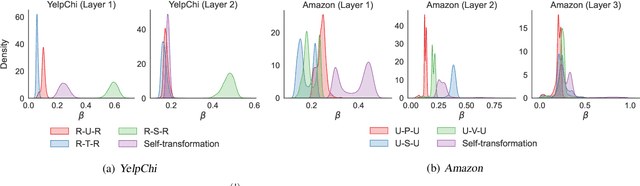
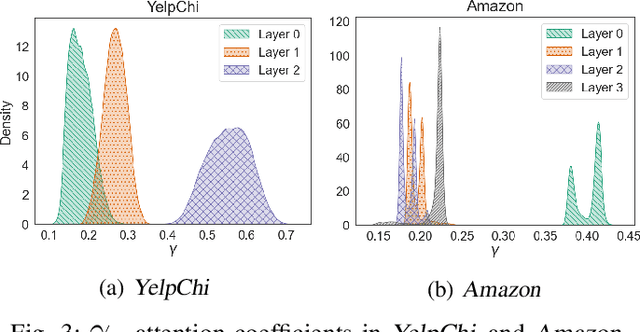
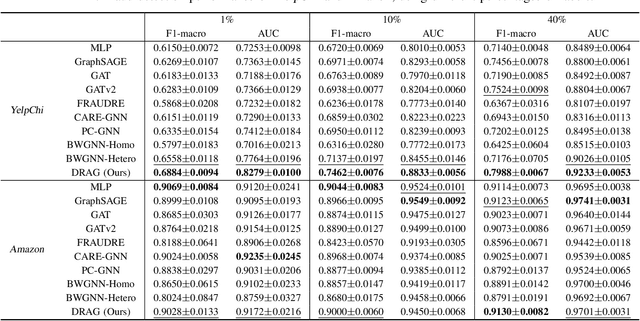
Fraud detection aims to discover fraudsters deceiving other users by, for example, leaving fake reviews or making abnormal transactions. Graph-based fraud detection methods consider this task as a classification problem with two classes: frauds or normal. We address this problem using Graph Neural Networks (GNNs) by proposing a dynamic relation-attentive aggregation mechanism. Based on the observation that many real-world graphs include different types of relations, we propose to learn a node representation per relation and aggregate the node representations using a learnable attention function that assigns a different attention coefficient to each relation. Furthermore, we combine the node representations from different layers to consider both the local and global structures of a target node, which is beneficial to improving the performance of fraud detection on graphs with heterophily. By employing dynamic graph attention in all the aggregation processes, our method adaptively computes the attention coefficients for each node. Experimental results show that our method, DRAG, outperforms state-of-the-art fraud detection methods on real-world benchmark datasets.
Learning Vehicle Dynamics from Cropped Image Patches for Robot Navigation in Unpaved Outdoor Terrains
Sep 06, 2023

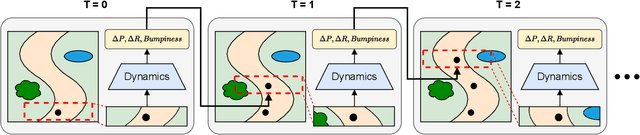

In the realm of autonomous mobile robots, safe navigation through unpaved outdoor environments remains a challenging task. Due to the high-dimensional nature of sensor data, extracting relevant information becomes a complex problem, which hinders adequate perception and path planning. Previous works have shown promising performances in extracting global features from full-sized images. However, they often face challenges in capturing essential local information. In this paper, we propose Crop-LSTM, which iteratively takes cropped image patches around the current robot's position and predicts the future position, orientation, and bumpiness. Our method performs local feature extraction by paying attention to corresponding image patches along the predicted robot trajectory in the 2D image plane. This enables more accurate predictions of the robot's future trajectory. With our wheeled mobile robot platform Raicart, we demonstrated the effectiveness of Crop-LSTM for point-goal navigation in an unpaved outdoor environment. Our method enabled safe and robust navigation using RGBD images in challenging unpaved outdoor terrains. The summary video is available at https://youtu.be/iIGNZ8ignk0.
Not Only Rewards But Also Constraints: Applications on Legged Robot Locomotion
Aug 24, 2023



Several earlier studies have shown impressive control performance in complex robotic systems by designing the controller using a neural network and training it with model-free reinforcement learning. However, these outstanding controllers with natural motion style and high task performance are developed through extensive reward engineering, which is a highly laborious and time-consuming process of designing numerous reward terms and determining suitable reward coefficients. In this work, we propose a novel reinforcement learning framework for training neural network controllers for complex robotic systems consisting of both rewards and constraints. To let the engineers appropriately reflect their intent to constraints and handle them with minimal computation overhead, two constraint types and an efficient policy optimization algorithm are suggested. The learning framework is applied to train locomotion controllers for several legged robots with different morphology and physical attributes to traverse challenging terrains. Extensive simulation and real-world experiments demonstrate that performant controllers can be trained with significantly less reward engineering, by tuning only a single reward coefficient. Furthermore, a more straightforward and intuitive engineering process can be utilized, thanks to the interpretability and generalizability of constraints. The summary video is available at https://youtu.be/KAlm3yskhvM.