 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActuator-Constrained Reinforcement Learning for High-Speed Quadrupedal Locomotion
Dec 29, 2023This paper presents a method for achieving high-speed running of a quadruped robot by considering the actuator torque-speed operating region in reinforcement learning. The physical properties and constraints of the actuator are included in the training process to reduce state transitions that are infeasible in the real world due to motor torque-speed limitations. The gait reward is designed to distribute motor torque evenly across all legs, contributing to more balanced power usage and mitigating performance bottlenecks due to single-motor saturation. Additionally, we designed a lightweight foot to enhance the robot's agility. We observed that applying the motor operating region as a constraint helps the policy network avoid infeasible areas during sampling. With the trained policy, KAIST Hound, a 45 kg quadruped robot, can run up to 6.5 m/s, which is the fastest speed among electric motor-based quadruped robots.
Not Only Rewards But Also Constraints: Applications on Legged Robot Locomotion
Aug 24, 2023



Several earlier studies have shown impressive control performance in complex robotic systems by designing the controller using a neural network and training it with model-free reinforcement learning. However, these outstanding controllers with natural motion style and high task performance are developed through extensive reward engineering, which is a highly laborious and time-consuming process of designing numerous reward terms and determining suitable reward coefficients. In this work, we propose a novel reinforcement learning framework for training neural network controllers for complex robotic systems consisting of both rewards and constraints. To let the engineers appropriately reflect their intent to constraints and handle them with minimal computation overhead, two constraint types and an efficient policy optimization algorithm are suggested. The learning framework is applied to train locomotion controllers for several legged robots with different morphology and physical attributes to traverse challenging terrains. Extensive simulation and real-world experiments demonstrate that performant controllers can be trained with significantly less reward engineering, by tuning only a single reward coefficient. Furthermore, a more straightforward and intuitive engineering process can be utilized, thanks to the interpretability and generalizability of constraints. The summary video is available at https://youtu.be/KAlm3yskhvM.
Concurrent Training of a Control Policy and a State Estimator for Dynamic and Robust Legged Locomotion
Mar 02, 2022
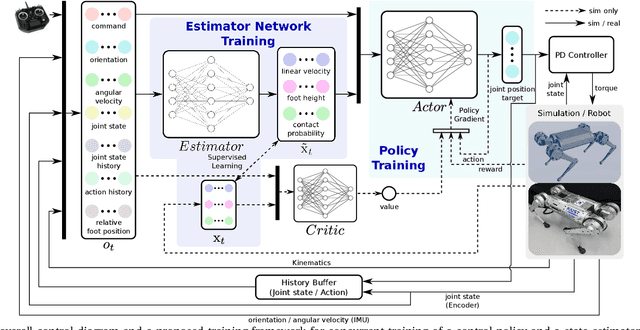
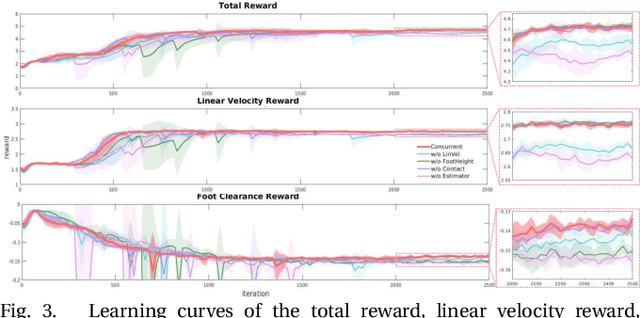
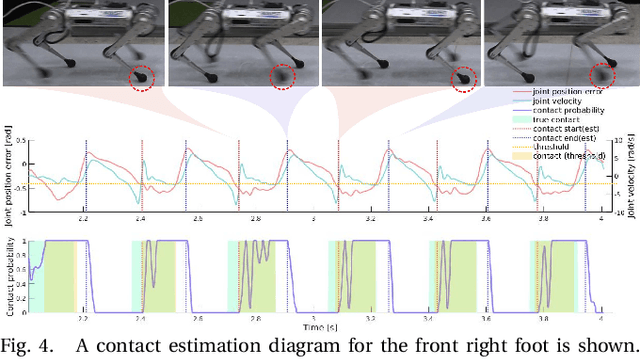
In this paper, we propose a locomotion training framework where a control policy and a state estimator are trained concurrently. The framework consists of a policy network which outputs the desired joint positions and a state estimation network which outputs estimates of the robot's states such as the base linear velocity, foot height, and contact probability. We exploit a fast simulation environment to train the networks and the trained networks are transferred to the real robot. The trained policy and state estimator are capable of traversing diverse terrains such as a hill, slippery plate, and bumpy road. We also demonstrate that the learned policy can run at up to 3.75 m/s on normal flat ground and 3.54 m/s on a slippery plate with the coefficient of friction of 0.22.
* Accepted for IEEE Robotics and Automation Letters (RA-L) and ICRA 2022