 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Semantic Traversability with Egocentric Video and Automated Annotation Strategy
Jun 05, 2024For reliable autonomous robot navigation in urban settings, the robot must have the ability to identify semantically traversable terrains in the image based on the semantic understanding of the scene. This reasoning ability is based on semantic traversability, which is frequently achieved using semantic segmentation models fine-tuned on the testing domain. This fine-tuning process often involves manual data collection with the target robot and annotation by human labelers which is prohibitively expensive and unscalable. In this work, we present an effective methodology for training a semantic traversability estimator using egocentric videos and an automated annotation process. Egocentric videos are collected from a camera mounted on a pedestrian's chest. The dataset for training the semantic traversability estimator is then automatically generated by extracting semantically traversable regions in each video frame using a recent foundation model in image segmentation and its prompting technique. Extensive experiments with videos taken across several countries and cities, covering diverse urban scenarios, demonstrate the high scalability and generalizability of the proposed annotation method. Furthermore, performance analysis and real-world deployment for autonomous robot navigation showcase that the trained semantic traversability estimator is highly accurate, able to handle diverse camera viewpoints, computationally light, and real-world applicable. The summary video is available at https://youtu.be/EUVoH-wA-lA.
Learning Dynamic Manipulation Skills from Haptic-Play
Jul 28, 2022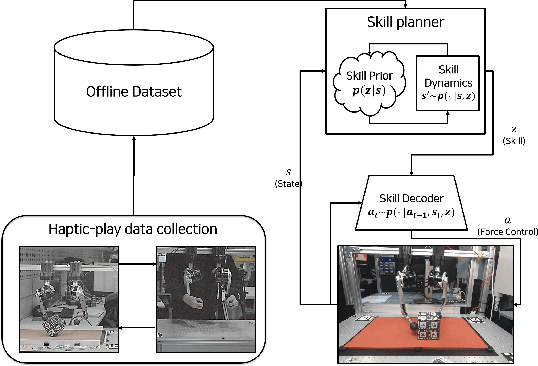
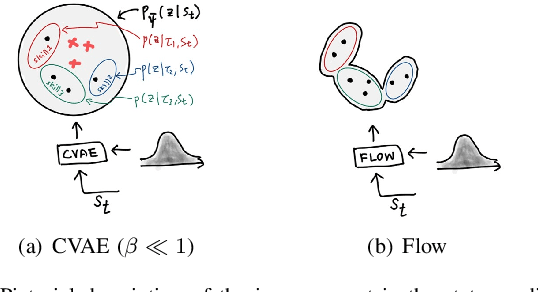

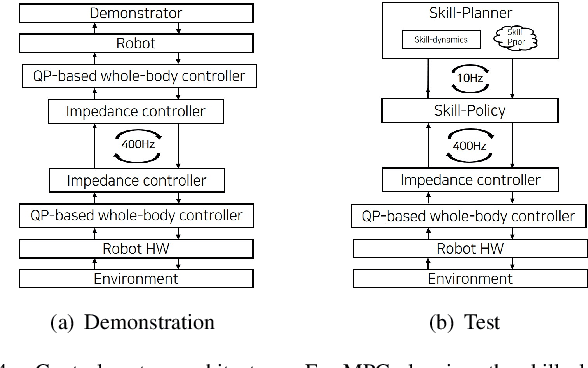
In this paper, we propose a data-driven skill learning approach to solve highly dynamic manipulation tasks entirely from offline teleoperated play data. We use a bilateral teleoperation system to continuously collect a large set of dexterous and agile manipulation behaviors, which is enabled by providing direct force feedback to the operator. We jointly learn the state conditional latent skill distribution and skill decoder network in the form of goal-conditioned policy and skill conditional state transition dynamics using a two-stage generative modeling framework. This allows one to perform robust model-based planning, both online and offline planning methods, in the learned skill-space to accomplish any given downstream tasks at test time. We provide both simulated and real-world dual-arm box manipulation experiments showing that a sequence of force-controlled dynamic manipulation skills can be composed in real-time to successfully configure the box to the randomly selected target position and orientation; please refer to the supplementary video, https://youtu.be/LA5B236ILzM.