 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-domain Sound Recognition for Efficient Underwater Data Analysis
Sep 07, 2023



This paper presents a novel deep learning approach for analyzing massive underwater acoustic data by leveraging a model trained on a broad spectrum of non-underwater (aerial) sounds. Recognizing the challenge in labeling vast amounts of underwater data, we propose a two-fold methodology to accelerate this labor-intensive procedure. The first part of our approach involves PCA and UMAP visualization of the underwater data using the feature vectors of an aerial sound recognition model. This enables us to cluster the data in a two dimensional space and listen to points within these clusters to understand their defining characteristics. This innovative method simplifies the process of selecting candidate labels for further training. In the second part, we train a neural network model using both the selected underwater data and the non-underwater dataset. We conducted a quantitative analysis to measure the precision, recall, and F1 score of our model for recognizing airgun sounds, a common type of underwater sound. The F1 score achieved by our model exceeded 84.3%, demonstrating the effectiveness of our approach in analyzing underwater acoustic data. The methodology presented in this paper holds significant potential to reduce the amount of labor required in underwater data analysis and opens up new possibilities for further research in the field of cross-domain data analysis.
Neural Audio Fingerprint for High-specific Audio Retrieval based on Contrastive Learning
Oct 28, 2020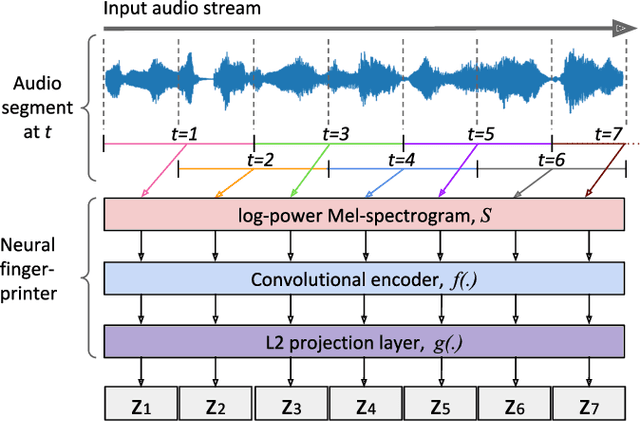

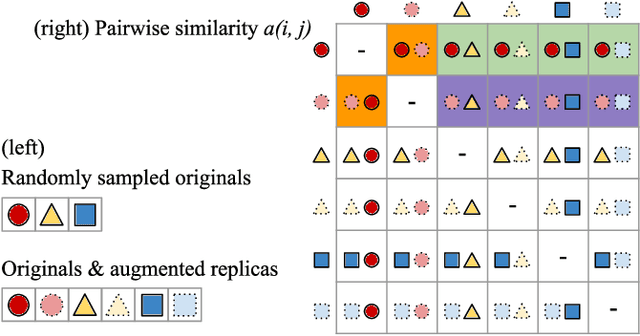
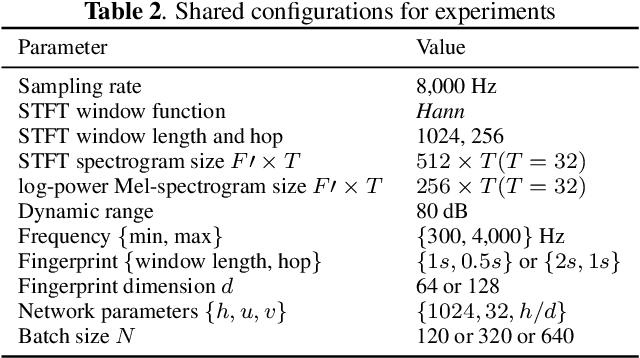
Most of existing audio fingerprinting systems have limitations to be used for high-specific audio retrieval at scale. In this work, we generate a low-dimensional representation from a short unit segment of audio, and couple this fingerprint with a fast maximum inner-product search. To this end, we present a contrastive learning framework that derives from the segment-level search objective. Each update in training uses a batch consisting of a set of pseudo labels, randomly selected original samples, and their augmented replicas. These replicas can simulate the degrading effects on original audio signals by applying small time offsets and various types of distortions, such as background noise and room/microphone impulse responses. In the segment-level search task, where the conventional audio fingerprinting systems used to fail, our system using 10x smaller storage has shown promising results. Our code and dataset will be available.
Deep convolutional neural networks for predominant instrument recognition in polyphonic music
Dec 26, 2016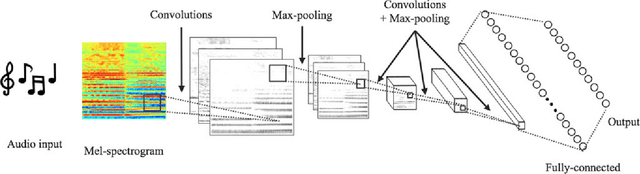
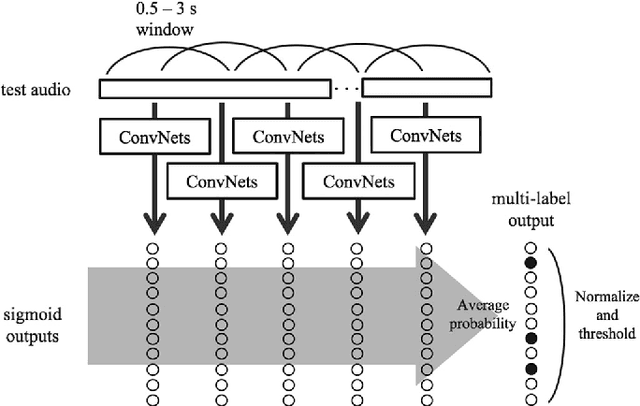

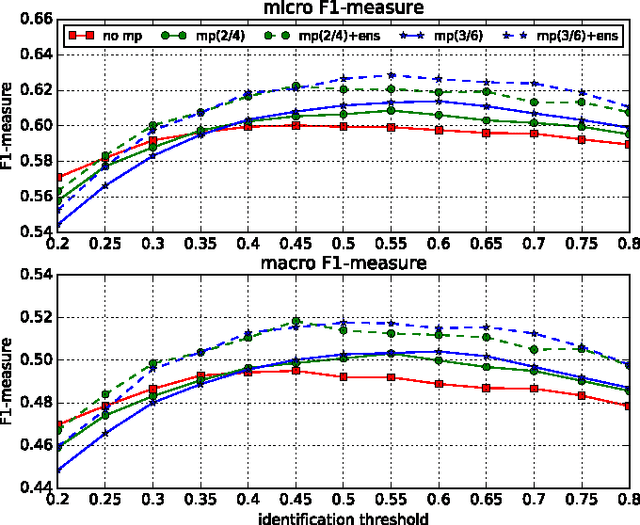
Identifying musical instruments in polyphonic music recordings is a challenging but important problem in the field of music information retrieval. It enables music search by instrument, helps recognize musical genres, or can make music transcription easier and more accurate. In this paper, we present a convolutional neural network framework for predominant instrument recognition in real-world polyphonic music. We train our network from fixed-length music excerpts with a single-labeled predominant instrument and estimate an arbitrary number of predominant instruments from an audio signal with a variable length. To obtain the audio-excerpt-wise result, we aggregate multiple outputs from sliding windows over the test audio. In doing so, we investigated two different aggregation methods: one takes the average for each instrument and the other takes the instrument-wise sum followed by normalization. In addition, we conducted extensive experiments on several important factors that affect the performance, including analysis window size, identification threshold, and activation functions for neural networks to find the optimal set of parameters. Using a dataset of 10k audio excerpts from 11 instruments for evaluation, we found that convolutional neural networks are more robust than conventional methods that exploit spectral features and source separation with support vector machines. Experimental results showed that the proposed convolutional network architecture obtained an F1 measure of 0.602 for micro and 0.503 for macro, respectively, achieving 19.6% and 16.4% in performance improvement compared with other state-of-the-art algorithms.
* 13 pages, 7 figures, accepted for publication in IEEE/ACM Transactions on Audio, Speech, and Language Processing on 16-Nov-2016. This is initial submission version. Fully edited version is available at http://ieeexplore.ieee.org/document/7755799/