 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIPED: Pedagogically Informed Tutoring System for ESL Education
Jun 05, 2024Large Language Models (LLMs) have a great potential to serve as readily available and cost-efficient Conversational Intelligent Tutoring Systems (CITS) for teaching L2 learners of English. Existing CITS, however, are designed to teach only simple concepts or lack the pedagogical depth necessary to address diverse learning strategies. To develop a more pedagogically informed CITS capable of teaching complex concepts, we construct a BIlingual PEDagogically-informed Tutoring Dataset (BIPED) of one-on-one, human-to-human English tutoring interactions. Through post-hoc analysis of the tutoring interactions, we come up with a lexicon of dialogue acts (34 tutor acts and 9 student acts), which we use to further annotate the collected dataset. Based on a two-step framework of first predicting the appropriate tutor act then generating the corresponding response, we implemented two CITS models using GPT-4 and SOLAR-KO, respectively. We experimentally demonstrate that the implemented models not only replicate the style of human teachers but also employ diverse and contextually appropriate pedagogical strategies.
Show Me the Instruments: Musical Instrument Retrieval from Mixture Audio
Nov 15, 2022As digital music production has become mainstream, the selection of appropriate virtual instruments plays a crucial role in determining the quality of music. To search the musical instrument samples or virtual instruments that make one's desired sound, music producers use their ears to listen and compare each instrument sample in their collection, which is time-consuming and inefficient. In this paper, we call this task as Musical Instrument Retrieval and propose a method for retrieving desired musical instruments using reference music mixture as a query. The proposed model consists of the Single-Instrument Encoder and the Multi-Instrument Encoder, both based on convolutional neural networks. The Single-Instrument Encoder is trained to classify the instruments used in single-track audio, and we take its penultimate layer's activation as the instrument embedding. The Multi-Instrument Encoder is trained to estimate multiple instrument embeddings using the instrument embeddings computed by the Single-Instrument Encoder as a set of target embeddings. For more generalized training and realistic evaluation, we also propose a new dataset called Nlakh. Experimental results showed that the Single-Instrument Encoder was able to learn the mapping from the audio signal of unseen instruments to the instrument embedding space and the Multi-Instrument Encoder was able to extract multiple embeddings from the mixture of music and retrieve the desired instruments successfully. The code used for the experiment and audio samples are available at: https://github.com/minju0821/musical_instrument_retrieval
Improving Audio-Language Learning with MixGen and Multi-Level Test-Time Augmentation
Oct 31, 2022



In this paper, we propose two novel augmentation methods 1) audio-language MixGen (AL-MixGen) and 2) multi-level test-time augmentation (Multi-TTA) for audio-language learning. Inspired by MixGen, which is originally applied to vision-language learning, we introduce an augmentation method for the audio-language domain. We also explore the impact of test-time augmentations and present Multi-TTA which generalizes test-time augmentation over multiple layers of a deep learning model. Incorporating AL-MixGen and Multi-TTA into the baseline achieves 47.5 SPIDEr on audio captioning, which is an +18.2% over the baseline and outperforms the state-of-the-art approach with a 5x smaller model. In audio-text retrieval, the proposed methods surpass the baseline performance as well.
Exploiting Negative Preference in Content-based Music Recommendation with Contrastive Learning
Jul 28, 2022
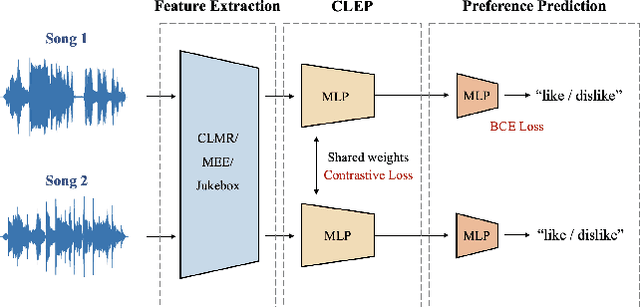
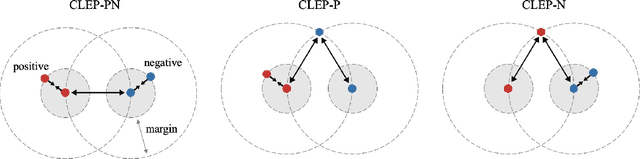

Advanced music recommendation systems are being introduced along with the development of machine learning. However, it is essential to design a music recommendation system that can increase user satisfaction by understanding users' music tastes, not by the complexity of models. Although several studies related to music recommendation systems exploiting negative preferences have shown performance improvements, there was a lack of explanation on how they led to better recommendations. In this work, we analyze the role of negative preference in users' music tastes by comparing music recommendation models with contrastive learning exploiting preference (CLEP) but with three different training strategies - exploiting preferences of both positive and negative (CLEP-PN), positive only (CLEP-P), and negative only (CLEP-N). We evaluate the effectiveness of the negative preference by validating each system with a small amount of personalized data obtained via survey and further illuminate the possibility of exploiting negative preference in music recommendations. Our experimental results show that CLEP-N outperforms the other two in accuracy and false positive rate. Furthermore, the proposed training strategies produced a consistent tendency regardless of different types of front-end musical feature extractors, proving the stability of the proposed method.