 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiased Automatic Speech Recognition for Dysarthric Speech via Sample Reweighting with Sample Affinity Test
May 22, 2023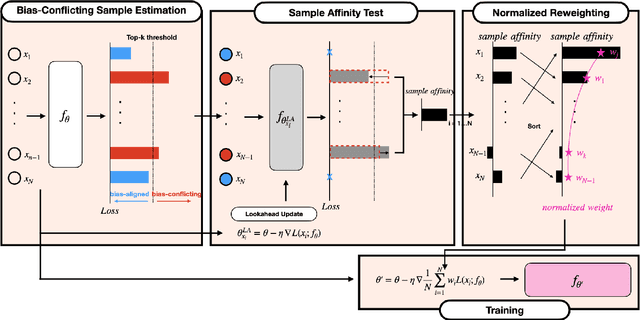
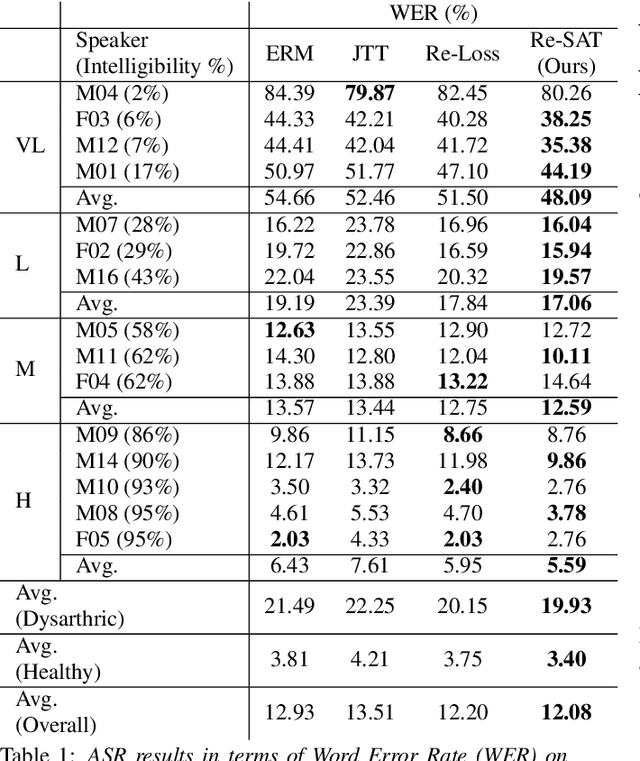
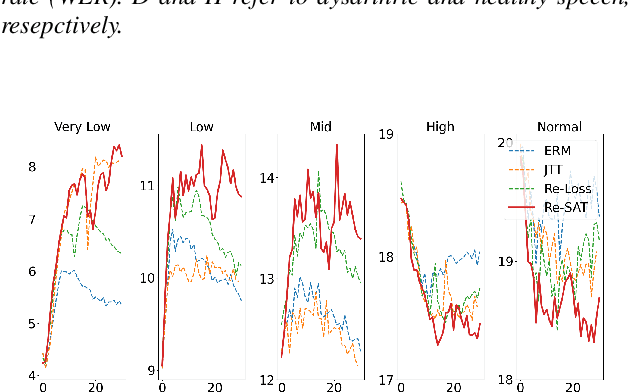
Automatic speech recognition systems based on deep learning are mainly trained under empirical risk minimization (ERM). Since ERM utilizes the averaged performance on the data samples regardless of a group such as healthy or dysarthric speakers, ASR systems are unaware of the performance disparities across the groups. This results in biased ASR systems whose performance differences among groups are severe. In this study, we aim to improve the ASR system in terms of group robustness for dysarthric speakers. To achieve our goal, we present a novel approach, sample reweighting with sample affinity test (Re-SAT). Re-SAT systematically measures the debiasing helpfulness of the given data sample and then mitigates the bias by debiasing helpfulness-based sample reweighting. Experimental results demonstrate that Re-SAT contributes to improved ASR performance on dysarthric speech without performance degradation on healthy speech.
Improving Audio-Language Learning with MixGen and Multi-Level Test-Time Augmentation
Oct 31, 2022



In this paper, we propose two novel augmentation methods 1) audio-language MixGen (AL-MixGen) and 2) multi-level test-time augmentation (Multi-TTA) for audio-language learning. Inspired by MixGen, which is originally applied to vision-language learning, we introduce an augmentation method for the audio-language domain. We also explore the impact of test-time augmentations and present Multi-TTA which generalizes test-time augmentation over multiple layers of a deep learning model. Incorporating AL-MixGen and Multi-TTA into the baseline achieves 47.5 SPIDEr on audio captioning, which is an +18.2% over the baseline and outperforms the state-of-the-art approach with a 5x smaller model. In audio-text retrieval, the proposed methods surpass the baseline performance as well.