 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoding-Free and Privacy-Preserving MCP Framework for Clinical Agentic Research Intelligence System
Apr 14, 2026Clinical research involves labor-intensive processes such as study design, cohort construction, model development, and documentation, requiring domain expertise, programming skills, and access to sensitive patient data. These demands create barriers for clinicians and external researchers conducting data-driven studies. To overcome these limitations, we developed a Clinical Agentic Research Intelligence System (CARIS) that automates the clinical research workflow while preserving data privacy, enabling comprehensive studies without direct access to raw data. CARIS integrates Large Language Models (LLMs) with modular tools via the Model Context Protocol (MCP), enabling natural language-driven orchestration of appropriate tools. Databases remain securely within the MCP server, and users access only the outputs and final research reports. Based on user intent, CARIS automatically executes the full pipeline: research planning, literature search, cohort construction, Institutional Review Board (IRB) documentation, Vibe Machine Learning (ML), and report generation, with iterative human-in-the-loop refinement. We evaluated CARIS on three heterogeneous datasets with distinct clinical tasks. Research plans and IRB documents were finalized within three to four iterations, using evidence from literature and data. The system supported Vibe ML by exploring feature-model combinations, ranking the top ten models, and generating performance visualizations. Final reports showed high completeness based on a checklist derived from the TRIPOD+AI framework, achieving 96% coverage in LLM evaluation and 82% in human evaluation. CARIS demonstrates that agentic AI can transform clinical hypotheses into executable research workflows across heterogeneous datasets. By eliminating the need for coding and direct data access, the system lowers barriers and bridges public and private clinical data environments.
Surgical Agent Orchestration Platform for Voice-directed Patient Data Interaction
Nov 11, 2025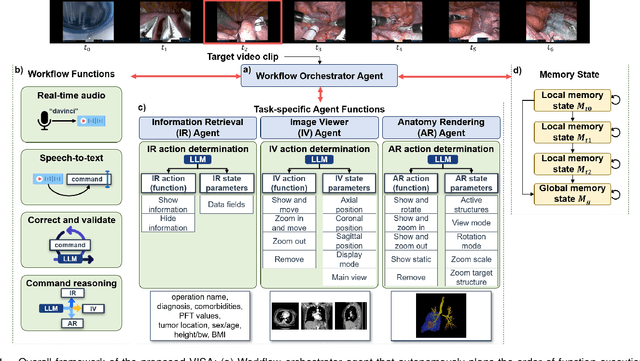
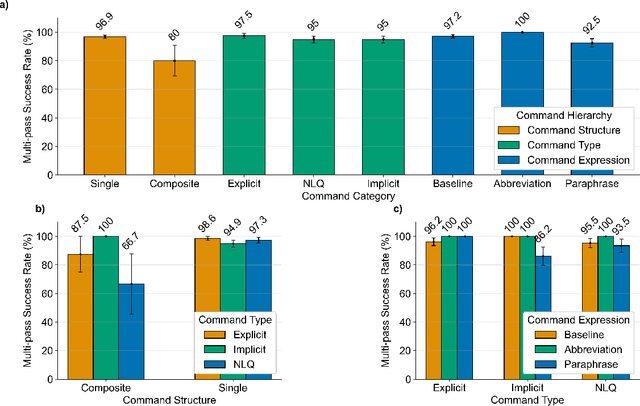
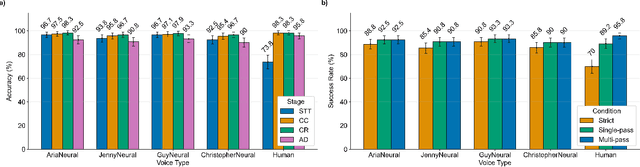

In da Vinci robotic surgery, surgeons' hands and eyes are fully engaged in the procedure, making it difficult to access and manipulate multimodal patient data without interruption. We propose a voice-directed Surgical Agent Orchestrator Platform (SAOP) built on a hierarchical multi-agent framework, consisting of an orchestration agent and three task-specific agents driven by Large Language Models (LLMs). These LLM-based agents autonomously plan, refine, validate, and reason to map voice commands into specific tasks such as retrieving clinical information, manipulating CT scans, or navigating 3D anatomical models on the surgical video. We also introduce a Multi-level Orchestration Evaluation Metric (MOEM) to comprehensively assess the performance and robustness from command-level and category-level perspectives. The SAOP achieves high accuracy and success rates across 240 voice commands, while LLM-based agents improve robustness against speech recognition errors and diverse or ambiguous free-form commands, demonstrating strong potential to support minimally invasive da Vinci robotic surgery.
A foundation model for human-AI collaboration in medical literature mining
Jan 27, 2025



Systematic literature review is essential for evidence-based medicine, requiring comprehensive analysis of clinical trial publications. However, the application of artificial intelligence (AI) models for medical literature mining has been limited by insufficient training and evaluation across broad therapeutic areas and diverse tasks. Here, we present LEADS, an AI foundation model for study search, screening, and data extraction from medical literature. The model is trained on 633,759 instruction data points in LEADSInstruct, curated from 21,335 systematic reviews, 453,625 clinical trial publications, and 27,015 clinical trial registries. We showed that LEADS demonstrates consistent improvements over four cutting-edge generic large language models (LLMs) on six tasks. Furthermore, LEADS enhances expert workflows by providing supportive references following expert requests, streamlining processes while maintaining high-quality results. A study with 16 clinicians and medical researchers from 14 different institutions revealed that experts collaborating with LEADS achieved a recall of 0.81 compared to 0.77 experts working alone in study selection, with a time savings of 22.6%. In data extraction tasks, experts using LEADS achieved an accuracy of 0.85 versus 0.80 without using LEADS, alongside a 26.9% time savings. These findings highlight the potential of specialized medical literature foundation models to outperform generic models, delivering significant quality and efficiency benefits when integrated into expert workflows for medical literature mining.
End-to-End Deep Learning for Interior Tomography with Low-Dose X-ray CT
Jan 09, 2025Objective: There exist several X-ray computed tomography (CT) scanning strategies to reduce a radiation dose, such as (1) sparse-view CT, (2) low-dose CT, and (3) region-of-interest (ROI) CT (called interior tomography). To further reduce the dose, the sparse-view and/or low-dose CT settings can be applied together with interior tomography. Interior tomography has various advantages in terms of reducing the number of detectors and decreasing the X-ray radiation dose. However, a large patient or small field-of-view (FOV) detector can cause truncated projections, and then the reconstructed images suffer from severe cupping artifacts. In addition, although the low-dose CT can reduce the radiation exposure dose, analytic reconstruction algorithms produce image noise. Recently, many researchers have utilized image-domain deep learning (DL) approaches to remove each artifact and demonstrated impressive performances, and the theory of deep convolutional framelets supports the reason for the performance improvement. Approach: In this paper, we found that the image-domain convolutional neural network (CNN) is difficult to solve coupled artifacts, based on deep convolutional framelets. Significance: To address the coupled problem, we decouple it into two sub-problems: (i) image domain noise reduction inside truncated projection to solve low-dose CT problem and (ii) extrapolation of projection outside truncated projection to solve the ROI CT problem. The decoupled sub-problems are solved directly with a novel proposed end-to-end learning using dual-domain CNNs. Main results: We demonstrate that the proposed method outperforms the conventional image-domain deep learning methods, and a projection-domain CNN shows better performance than the image-domain CNNs which are commonly used by many researchers.
Autonomous Robotic Ultrasound System for Liver Follow-up Diagnosis: Pilot Phantom Study
May 09, 2024



The paper introduces a novel autonomous robot ultrasound (US) system targeting liver follow-up scans for outpatients in local communities. Given a computed tomography (CT) image with specific target regions of interest, the proposed system carries out the autonomous follow-up scan in three steps: (i) initial robot contact to surface, (ii) coordinate mapping between CT image and robot, and (iii) target US scan. Utilizing 3D US-CT registration and deep learning-based segmentation networks, we can achieve precise imaging of 3D hepatic veins, facilitating accurate coordinate mapping between CT and the robot. This enables the automatic localization of follow-up targets within the CT image, allowing the robot to navigate precisely to the target's surface. Evaluation of the ultrasound phantom confirms the quality of the US-CT registration and shows the robot reliably locates the targets in repeated trials. The proposed framework holds the potential to significantly reduce time and costs for healthcare providers, clinicians, and follow-up patients, thereby addressing the increasing healthcare burden associated with chronic disease in local communities.
Prompt-driven Universal Model for View-Agnostic Echocardiography Analysis
Apr 09, 2024Echocardiography segmentation for cardiac analysis is time-consuming and resource-intensive due to the variability in image quality and the necessity to process scans from various standard views. While current automated segmentation methods in echocardiography show promising performance, they are trained on specific scan views to analyze corresponding data. However, this solution has a limitation as the number of required models increases with the number of standard views. To address this, in this paper, we present a prompt-driven universal method for view-agnostic echocardiography analysis. Considering the domain shift between standard views, we first introduce a method called prompt matching, aimed at learning prompts specific to different views by matching prompts and querying input embeddings using a pre-trained vision model. Then, we utilized a pre-trained medical language model to align textual information with pixel data for accurate segmentation. Extensive experiments on three standard views showed that our approach significantly outperforms the state-of-the-art universal methods and achieves comparable or even better performances over the segmentation model trained and tested on same views.
MediViSTA-SAM: Zero-shot Medical Video Analysis with Spatio-temporal SAM Adaptation
Sep 24, 2023In recent years, the Segmentation Anything Model (SAM) has attracted considerable attention as a foundational model well-known for its robust generalization capabilities across various downstream tasks. However, SAM does not exhibit satisfactory performance in the realm of medical image analysis. In this study, we introduce the first study on adapting SAM on video segmentation, called MediViSTA-SAM, a novel approach designed for medical video segmentation. Given video data, MediViSTA, spatio-temporal adapter captures long and short range temporal attention with cross-frame attention mechanism effectively constraining it to consider the immediately preceding video frame as a reference, while also considering spatial information effectively. Additionally, it incorporates multi-scale fusion by employing a U-shaped encoder and a modified mask decoder to handle objects of varying sizes. To evaluate our approach, extensive experiments were conducted using state-of-the-art (SOTA) methods, assessing its generalization abilities on multi-vendor in-house echocardiography datasets. The results highlight the accuracy and effectiveness of our network in medical video segmentation.
DULDA: Dual-domain Unsupervised Learned Descent Algorithm for PET image reconstruction
Mar 10, 2023



Deep learning based PET image reconstruction methods have achieved promising results recently. However, most of these methods follow a supervised learning paradigm, which rely heavily on the availability of high-quality training labels. In particular, the long scanning time required and high radiation exposure associated with PET scans make obtaining this labels impractical. In this paper, we propose a dual-domain unsupervised PET image reconstruction method based on learned decent algorithm, which reconstructs high-quality PET images from sinograms without the need for image labels. Specifically, we unroll the proximal gradient method with a learnable l2,1 norm for PET image reconstruction problem. The training is unsupervised, using measurement domain loss based on deep image prior as well as image domain loss based on rotation equivariance property. The experimental results domonstrate the superior performance of proposed method compared with maximum likelihood expectation maximazation (MLEM), total-variation regularized EM (EM-TV) and deep image prior based method (DIP).
A Noise-level-aware Framework for PET Image Denoising
Mar 15, 2022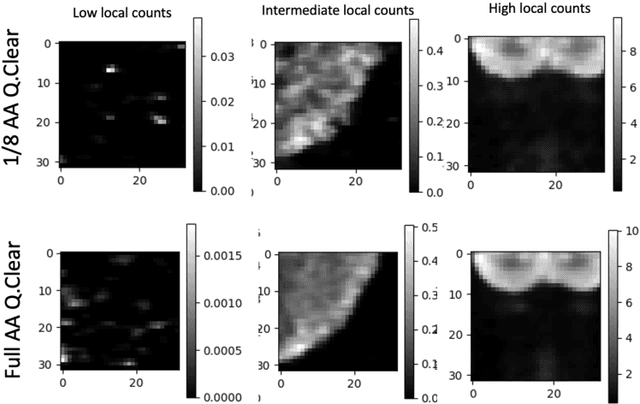
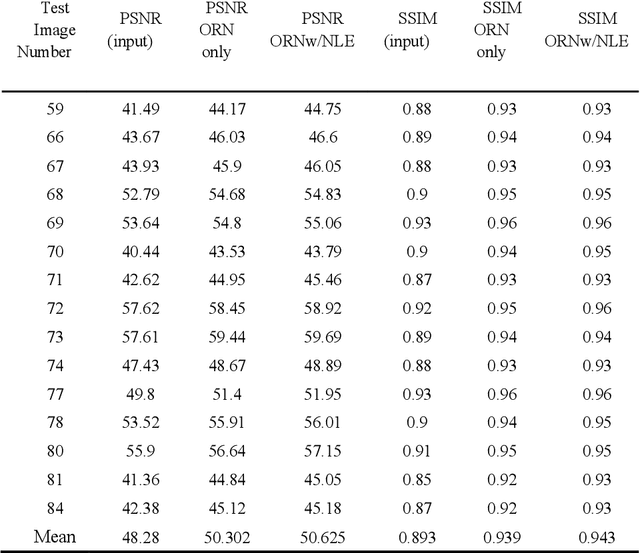
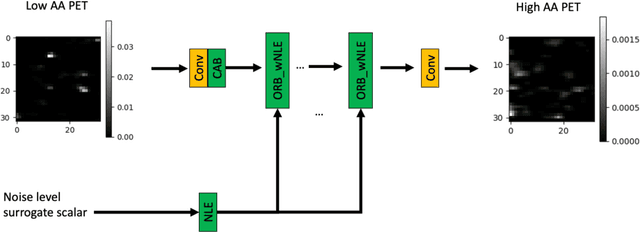
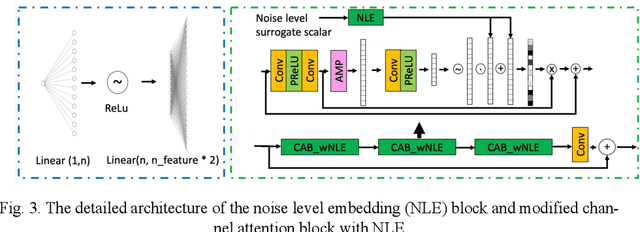
In PET, the amount of relative (signal-dependent) noise present in different body regions can be significantly different and is inherently related to the number of counts present in that region. The number of counts in a region depends, in principle and among other factors, on the total administered activity, scanner sensitivity, image acquisition duration, radiopharmaceutical tracer uptake in the region, and patient local body morphometry surrounding the region. In theory, less amount of denoising operations is needed to denoise a high-count (low relative noise) image than images a low-count (high relative noise) image, and vice versa. The current deep-learning-based methods for PET image denoising are predominantly trained on image appearance only and have no special treatment for images of different noise levels. Our hypothesis is that by explicitly providing the local relative noise level of the input image to a deep convolutional neural network (DCNN), the DCNN can outperform itself trained on image appearance only. To this end, we propose a noise-level-aware framework denoising framework that allows embedding of local noise level into a DCNN. The proposed is trained and tested on 30 and 15 patient PET images acquired on a GE Discovery MI PET/CT system. Our experiments showed that the increases in both PSNR and SSIM from our backbone network with relative noise level embedding (NLE) versus the same network without NLE were statistically significant with p<0.001, and the proposed method significantly outperformed a strong baseline method by a large margin.
Federated Active Learning (F-AL): an Efficient Annotation Strategy for Federated Learning
Feb 07, 2022



Federated learning (FL) has been intensively investigated in terms of communication efficiency, privacy, and fairness. However, efficient annotation, which is a pain point in real-world FL applications, is less studied. In this project, we propose to apply active learning (AL) and sampling strategy into the FL framework to reduce the annotation workload. We expect that the AL and FL can improve the performance of each other complementarily. In our proposed federated active learning (F-AL) method, the clients collaboratively implement the AL to obtain the instances which are considered as informative to FL in a distributed optimization manner. We compare the test accuracies of the global FL models using the conventional random sampling strategy, client-level separate AL (S-AL), and the proposed F-AL. We empirically demonstrate that the F-AL outperforms baseline methods in image classification tasks.