 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgRIPE challenge: Benchmark of Surgical Robot Instrument Pose Estimation
Jan 06, 2025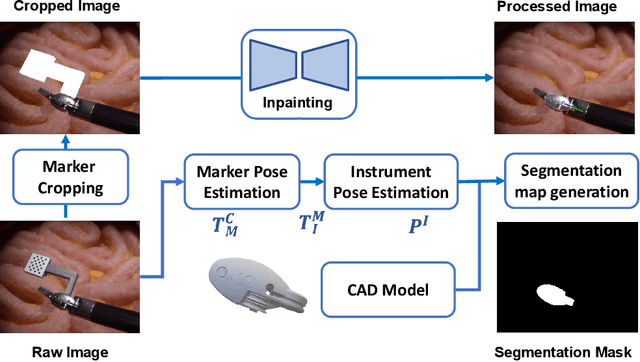


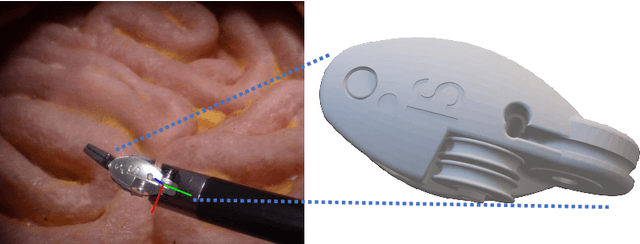
Accurate instrument pose estimation is a crucial step towards the future of robotic surgery, enabling applications such as autonomous surgical task execution. Vision-based methods for surgical instrument pose estimation provide a practical approach to tool tracking, but they often require markers to be attached to the instruments. Recently, more research has focused on the development of marker-less methods based on deep learning. However, acquiring realistic surgical data, with ground truth instrument poses, required for deep learning training, is challenging. To address the issues in surgical instrument pose estimation, we introduce the Surgical Robot Instrument Pose Estimation (SurgRIPE) challenge, hosted at the 26th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) in 2023. The objectives of this challenge are: (1) to provide the surgical vision community with realistic surgical video data paired with ground truth instrument poses, and (2) to establish a benchmark for evaluating markerless pose estimation methods. The challenge led to the development of several novel algorithms that showcased improved accuracy and robustness over existing methods. The performance evaluation study on the SurgRIPE dataset highlights the potential of these advanced algorithms to be integrated into robotic surgery systems, paving the way for more precise and autonomous surgical procedures. The SurgRIPE challenge has successfully established a new benchmark for the field, encouraging further research and development in surgical robot instrument pose estimation.
A Disease-Specific Foundation Model Using Over 100K Fundus Images: Release and Validation for Abnormality and Multi-Disease Classification on Downstream Tasks
Aug 16, 2024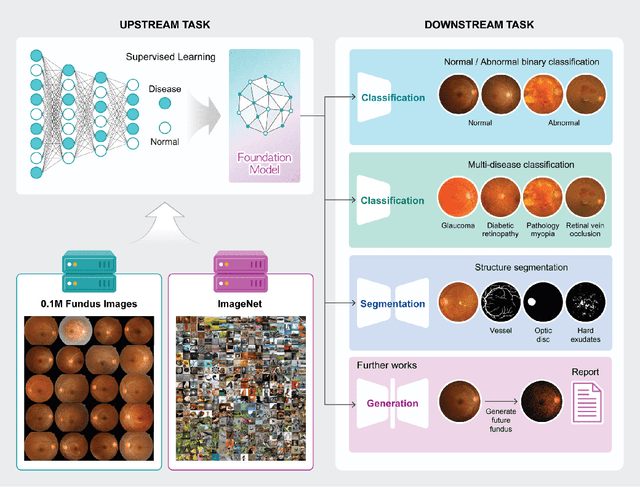
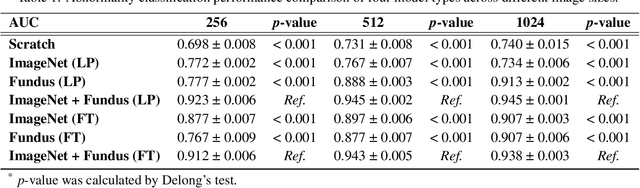
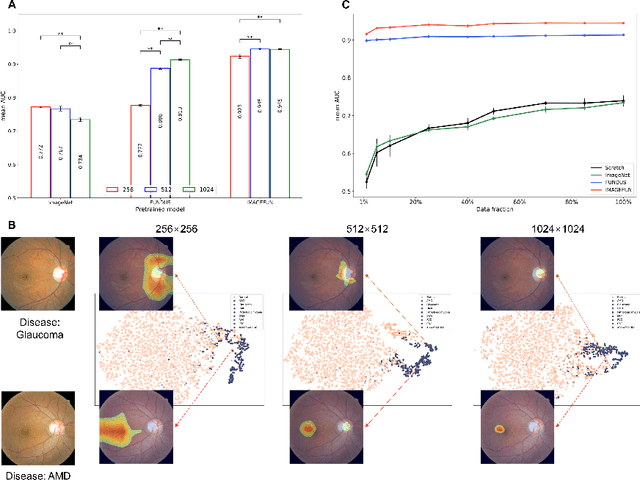
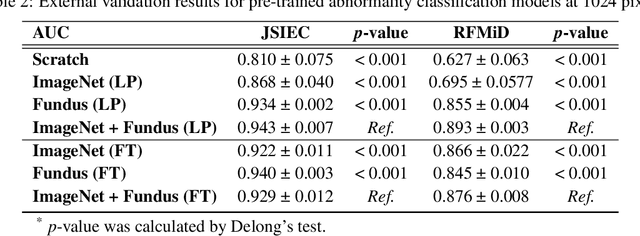
Artificial intelligence applied to retinal images offers significant potential for recognizing signs and symptoms of retinal conditions and expediting the diagnosis of eye diseases and systemic disorders. However, developing generalized artificial intelligence models for medical data often requires a large number of labeled images representing various disease signs, and most models are typically task-specific, focusing on major retinal diseases. In this study, we developed a Fundus-Specific Pretrained Model (Image+Fundus), a supervised artificial intelligence model trained to detect abnormalities in fundus images. A total of 57,803 images were used to develop this pretrained model, which achieved superior performance across various downstream tasks, indicating that our proposed model outperforms other general methods. Our Image+Fundus model offers a generalized approach to improve model performance while reducing the number of labeled datasets required. Additionally, it provides more disease-specific insights into fundus images, with visualizations generated by our model. These disease-specific foundation models are invaluable in enhancing the performance and efficiency of deep learning models in the field of fundus imaging.
Deep Learning-based Four-region Lung Segmentation in Chest Radiography for COVID-19 Diagnosis
Sep 26, 2020
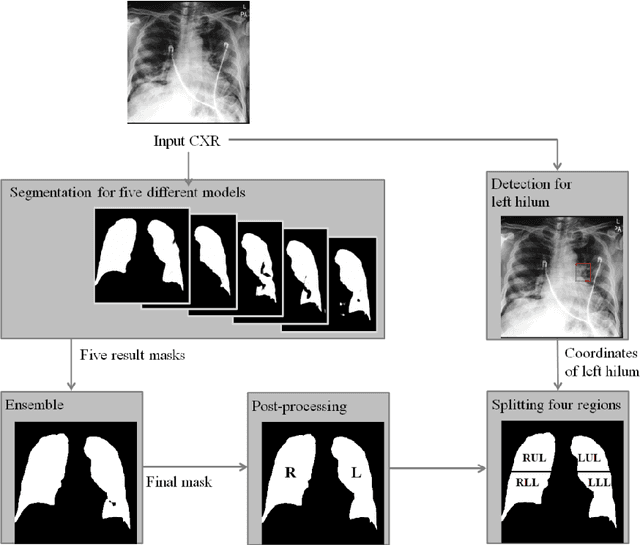
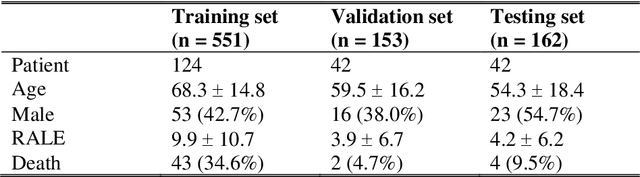
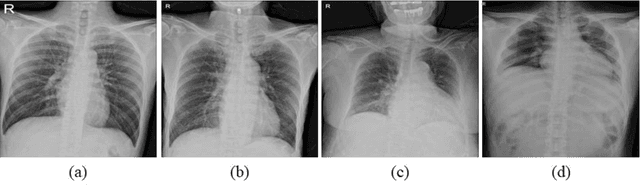
Purpose. Imaging plays an important role in assessing severity of COVID 19 pneumonia. However, semantic interpretation of chest radiography (CXR) findings does not include quantitative description of radiographic opacities. Most current AI assisted CXR image analysis framework do not quantify for regional variations of disease. To address these, we proposed a four region lung segmentation method to assist accurate quantification of COVID 19 pneumonia. Methods. A segmentation model to separate left and right lung is firstly applied, and then a carina and left hilum detection network is used, which are the clinical landmarks to separate the upper and lower lungs. To improve the segmentation performance of COVID 19 images, ensemble strategy incorporating five models is exploited. Using each region, we evaluated the clinical relevance of the proposed method with the Radiographic Assessment of the Quality of Lung Edema (RALE). Results. The proposed ensemble strategy showed dice score of 0.900, which is significantly higher than conventional methods (0.854 0.889). Mean intensities of segmented four regions indicate positive correlation to the extent and density scores of pulmonary opacities under the RALE framework. Conclusion. A deep learning based model in CXR can accurately segment and quantify regional distribution of pulmonary opacities in patients with COVID 19 pneumonia.
Automatic Tip Detection of Surgical Instruments in Biportal Endoscopic Spine Surgery
Nov 07, 2019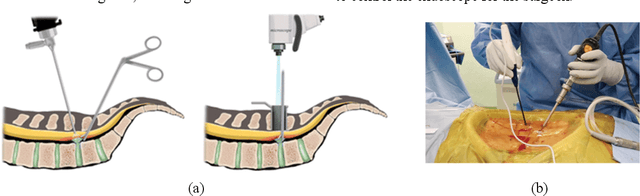
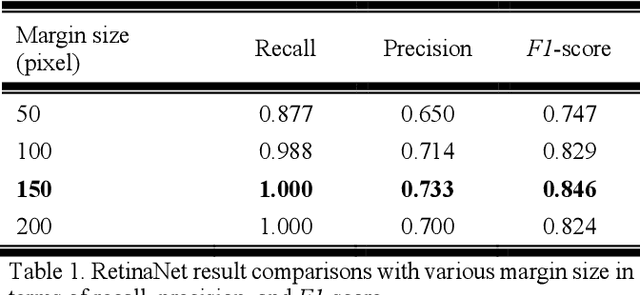
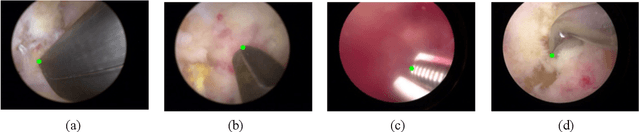
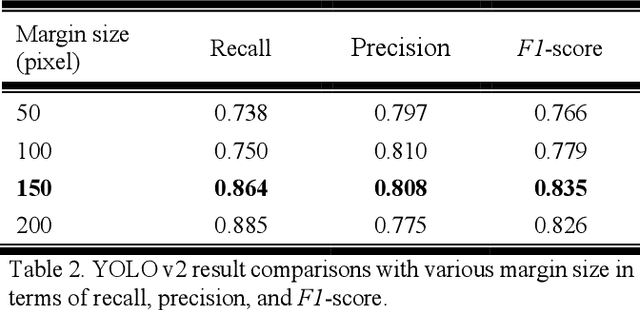
Some endoscopic surgeries require a surgeon to hold the endoscope with one hand and the surgical instruments with the other hand to perform the actual surgery with correct vision. Recent technical advances in deep learning as well as in robotics can introduce robotics to these endoscopic surgeries. This can have numerous advantages by freeing one hand of the surgeon, which will allow the surgeon to use both hands and to use more intricate and sophisticated techniques. Recently, deep learning with convolutional neural network achieves state-of-the-art results in computer vision. Therefore, the aim of this study is to automatically detect the tip of the instrument, localize a point, and evaluate detection accuracy in biportal endoscopic spine surgery. The localized point could be used for the controller's inputs of robotic endoscopy in these types of endoscopic surgeries.