 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Battery Degradation Forecasting Driven by Foundation Model Across Diverse Chemistries and Conditions
Dec 30, 2025Accurate forecasting of battery capacity fade is essential for the safety, reliability, and long-term efficiency of energy storage systems. However, the strong heterogeneity across cell chemistries, form factors, and operating conditions makes it difficult to build a single model that generalizes beyond its training domain. This work proposes a unified capacity forecasting framework that maintains robust performance across diverse chemistries and usage scenarios. We curate 20 public aging datasets into a large-scale corpus covering 1,704 cells and 3,961,195 charge-discharge cycle segments, spanning temperatures from $-5\,^{\circ}\mathrm{C}$ to $45\,^{\circ}\mathrm{C}$, multiple C-rates, and application-oriented profiles such as fast charging and partial cycling. On this corpus, we adopt a Time-Series Foundation Model (TSFM) backbone and apply parameter-efficient Low-Rank Adaptation (LoRA) together with physics-guided contrastive representation learning to capture shared degradation patterns. Experiments on both seen and deliberately held-out unseen datasets show that a single unified model achieves competitive or superior accuracy compared with strong per-dataset baselines, while retaining stable performance on chemistries, capacity scales, and operating conditions excluded from training. These results demonstrate the potential of TSFM-based architectures as a scalable and transferable solution for capacity degradation forecasting in real battery management systems.
Foundation Models Knowledge Distillation For Battery Capacity Degradation Forecast
May 13, 2025Accurate estimation of lithium-ion battery capacity degradation is critical for enhancing the reliability and safety of battery operations. Traditional expert models, tailored to specific scenarios, provide isolated estimations. With the rapid advancement of data-driven techniques, a series of general-purpose time-series foundation models have been developed. However, foundation models specifically designed for battery capacity degradation remain largely unexplored. To enable zero-shot generalization in battery degradation prediction using large model technology, this study proposes a degradation-aware fine-tuning strategy for time-series foundation models. We apply this strategy to fine-tune the Timer model on approximately 10 GB of open-source battery charge discharge data. Validation on our released CycleLife-SJTUIE dataset demonstrates that the fine-tuned Battery-Timer possesses strong zero-shot generalization capability in capacity degradation forecasting. To address the computational challenges of deploying large models, we further propose a knowledge distillation framework that transfers the knowledge of pre-trained foundation models into compact expert models. Distillation results across several state-of-the-art time-series expert models confirm that foundation model knowledge significantly improves the multi-condition generalization of expert models.
Recommending Clinical Trials for Online Patient Cases using Artificial Intelligence
Apr 15, 2025


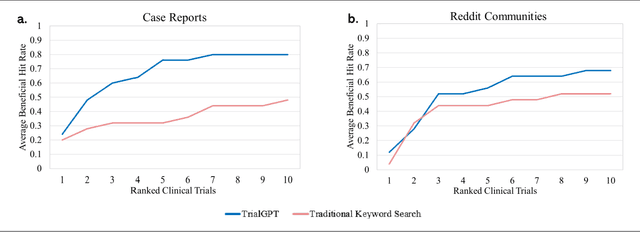
Clinical trials are crucial for assessing new treatments; however, recruitment challenges - such as limited awareness, complex eligibility criteria, and referral barriers - hinder their success. With the growth of online platforms, patients increasingly turn to social media and health communities for support, research, and advocacy, expanding recruitment pools and established enrollment pathways. Recognizing this potential, we utilized TrialGPT, a framework that leverages a large language model (LLM) as its backbone, to match 50 online patient cases (collected from published case reports and a social media website) to clinical trials and evaluate performance against traditional keyword-based searches. Our results show that TrialGPT outperforms traditional methods by 46% in identifying eligible trials, with each patient, on average, being eligible for around 7 trials. Additionally, our outreach efforts to case authors and trial organizers regarding these patient-trial matches yielded highly positive feedback, which we present from both perspectives.
A foundation model for human-AI collaboration in medical literature mining
Jan 27, 2025



Systematic literature review is essential for evidence-based medicine, requiring comprehensive analysis of clinical trial publications. However, the application of artificial intelligence (AI) models for medical literature mining has been limited by insufficient training and evaluation across broad therapeutic areas and diverse tasks. Here, we present LEADS, an AI foundation model for study search, screening, and data extraction from medical literature. The model is trained on 633,759 instruction data points in LEADSInstruct, curated from 21,335 systematic reviews, 453,625 clinical trial publications, and 27,015 clinical trial registries. We showed that LEADS demonstrates consistent improvements over four cutting-edge generic large language models (LLMs) on six tasks. Furthermore, LEADS enhances expert workflows by providing supportive references following expert requests, streamlining processes while maintaining high-quality results. A study with 16 clinicians and medical researchers from 14 different institutions revealed that experts collaborating with LEADS achieved a recall of 0.81 compared to 0.77 experts working alone in study selection, with a time savings of 22.6%. In data extraction tasks, experts using LEADS achieved an accuracy of 0.85 versus 0.80 without using LEADS, alongside a 26.9% time savings. These findings highlight the potential of specialized medical literature foundation models to outperform generic models, delivering significant quality and efficiency benefits when integrated into expert workflows for medical literature mining.
Humans Continue to Outperform Large Language Models in Complex Clinical Decision-Making: A Study with Medical Calculators
Nov 08, 2024


Although large language models (LLMs) have been assessed for general medical knowledge using medical licensing exams, their ability to effectively support clinical decision-making tasks, such as selecting and using medical calculators, remains uncertain. Here, we evaluate the capability of both medical trainees and LLMs to recommend medical calculators in response to various multiple-choice clinical scenarios such as risk stratification, prognosis, and disease diagnosis. We assessed eight LLMs, including open-source, proprietary, and domain-specific models, with 1,009 question-answer pairs across 35 clinical calculators and measured human performance on a subset of 100 questions. While the highest-performing LLM, GPT-4o, provided an answer accuracy of 74.3% (CI: 71.5-76.9%), human annotators, on average, outperformed LLMs with an accuracy of 79.5% (CI: 73.5-85.0%). With error analysis showing that the highest-performing LLMs continue to make mistakes in comprehension (56.6%) and calculator knowledge (8.1%), our findings emphasize that humans continue to surpass LLMs on complex clinical tasks such as calculator recommendation.